20 - mayo - 2018
Unidad II: Investigación Documental y de Campo
Sesión 5: Investigación documental
Actividad II: Análisis y abstracción de información
Una red de computadoras (también llamada red de ordenadores o red informática) es un conjunto equipos (computadoras y dispositivos), conectados por medio de cables, señales, ondas o cualquier otro método de transporte de datos, para compartir información (archivos), recursos (discos, impresoras, programas, etc.) y servicios (acceso a una base de datos, internet, correo electrónico, chat, juegos, etc.). A cada una de las computadoras conectadas a la red se le denomina un nodo.
Las redes de computadora, son herramientas maravillosas que hoy en día constituyen una parte muy importante de nuestra sociedad dado a que todos los sistemas de comunicaciones, finanzas y traspaso de información se componen de redes de computadoras. Pero, a todo esto ¿Cual es la historia de esta útil herramienta?; pues para empezar, nos podemos remontar a 1957 cuando los Estados Unidos crearon la Advanced Research Projects Agency (ARPA), como organismo afiliado al departamento de defensa para impulsar el desarrollo tecnológico.
Posteriormente a la creación del ARPA, Leonard Kleinrock, un investigador del MIT escribía el primer libro sobre tecnologías basadas en la transmisión por un mismo cable de más de una comunicación.
En 1965, la ARPA patrocino un programa que trataba de analizar las redes de comunicación usando computadoras. Mediante este programa, la máquina TX-2 en el laboratorio Licoln del MIT y la AN/FSQ-32 del System Development Corporation de Santa Mónica en California, se enlazaron directamente mediante una línea delicada de 1200 bits por segundo.
En 1967, La ARPA convoca una reunión en Ann Arbor (Michigan), donde se discuten por primera vez aspectos sobre la futura ARPANET.
En 1968 la ARPA no espera más y llama a empresas y universidades para que propusieran diseños, con el objetivo de construir la futura red. La universidad de California gana la propuesta para el diseño del centro de gestión de red y la empresa BBN (Bolt Beraneck and Newman Inc.) El concurso de adjudicación para el desarrollo de la tecnología de conmutación de paquetes mediante la implementación de la Interfaz Message Processors (IMP)
En 1969, es un año clave para las redes de computadoras, ya que se construye la primera red de computadoras de la historia. Denominada ARPANET, estaba compuesta por cuatro nodos situados en UCLA (Universidad de California en los Angeles), SRI (Stanford Research Institute), UCBS (Universidad de California de Santa Bárbara, Los Angeles) y la Universidad de UTA.





1.2.4) Redes de área amplia
Una Red de Área Amplia, o WAN (Wide Area Network), abarca una extensa área geográfica, por lo general un país o continente. Empezaremos nuestra discusión con las redes WAN alámbricas y usaremos el ejemplo de una empresa con sucursales en distintas ciudades.
Podemos tomar como ejemplo la WAN de una red que conecta las oficinas en Perth, Melbourne y Brisbane. Cada una de estas oficinas contiene computadoras destinadas a ejecutar programas de usuario (aplicaciones). Seguiremos el uso tradicional y llamaremos a estas máquinas hosts. Al resto de la red que conecta estos hosts se le denomina subred de comunicación, o para abreviar sólo subred. La tarea de la subred es transportar los mensajes de host a host, al igual que el sistema telefónico transporta las palabras (en realidad sólo los sonidos) de la persona que habla a la persona que escucha.
En la mayoría de las redes WAN, la subred cuenta con dos componentes distintos: líneas de transmisión y elementos de conmutación. Las líneas de transmisión mueven bits entre máquinas. Se pueden fabricar a partir de alambre de cobre, fibra óptica o incluso enlaces de radio. Como la mayoría de las empresas no poseen líneas de transmisión, tienen que rentarlas a una compañía de telecomunicaciones. Los elementos de conmutación o switches son computadoras especializadas que conectan dos o más líneas de transmisión. Cuando los datos llegan por una línea entrante, el elemento de conmutación debe elegir una línea saliente hacia la cual reenviarlos. En el pasado, estas computadoras de conmutación han recibido varios nombres; ahora se conocen como enrutador.

1.3) Software de red
Las primeras redes de computadoras se diseñaron teniendo en cuenta al hardware como punto principal y al software como secundario. Pero esta estrategia ya no funciona. Ahora el software de red está muy estructurado. En las siguientes secciones examinaremos con cierto detalle la técnica para estructurar el software.
Como hemos ya visto, las redes de área local o LAN, son redes de propiedad privada que operan dentro de un solo edificio, como una casa, oficina o fábrica. Las redes LAN se utilizan ampliamente para conectar computadoras personales y electrodomésticos con el fin de compartir recursos e intercambiar información. Cuando las empresas utilizan redes LAN se les conoce como redes empresariales.
El modelo cliente-servidor es una arquitectura que distribuye aplicaciones entre servidores tales como Windows Server 2008 )' computadoras cliente como máquinas con Windows 7 o Windows Vista. También distribuye la potencia necesaria de procesamiento. Esto es extremadamente común en las LANs hoy en día y con más aplicaciones que un usuario promedio utilizaría cuando se conecta a Internet. Por ejemplo, cuando un usuario llega a trabajar, este típicamente ingresa a la red. Hay posibilidades de que sea una red cliente/ servidor. El usuario puede estar utilizando Windows 7 como la computadora cliente para ingresar al dominio de Windows que es controlado por un Windows Server. Un ejemplo más simple sería un usuario casero que se conecta a Internet. Cuando esta persona quiere ir a un si tio web tal como Bing, abre el navegador web e introduce http://www.bing. com/ (o alguno de muchos accesos directos). El navegador web es la aplicación cliente. El servidor web de Bing es obviamente el ··servidor". Este sirve las páginas web llenas de código HTML. El navegador web de la computadora cliente decodifica el HTML y llena la pantalla del usuario con información de Internet.
Aquí algunos ejemplos de aplicaciones de los servidores:
Las redes de pare.{ significan primordialmente que cada computadora es n-arada como igual. Esto significa que cada computadora tiene la habilidad equitativa para servir y acceder a la información, justo como cualquier otra computadora en la red. Antes que los servidores se hicieran populares en redes computacionales basadas en PCs, cada computadora tenía la habilidad de almacenar información. Incluso después de que el modelo cliente/servidor fuera tan popular, las redes de pares han seguido conservando su lugar, en especial en redes pequeñas con lO computadoras o menos. Hoy en día, las computadoras pares pueden se servir información, la única diferencia es que solo pueden servirla a un pequeño número de computadoras al mismo tiempo.
Las redes de Pares han tomado un segundo sig nificado a partir de la última década. Ahora se refieren a redes de archivos compartidos y en esre caso es conocido como P2P. Ejemplos de redes de compartición de archivos incluyen al Napster, Gnutella y G2, pero otras tecnologías también cuentan con las ventajas de la compartición de archivos P2P, cales como Skype, VoiP y la computación en la nube. En una red P2P, los hose son añadidos de manera ad hoc. Esros pueden dejar la red en cualquier momento sin impactar la descarga de archivos. ~[uchos pares pueden contribuir a la disponibilidad de archivos y recursos.
Una persona que descarga información de una red P2P puede obtener unos pocos bits de información de muchas comput adoras d iferentes, después, la computadora que está descargando puede también compartir el archivo. La mayoría de las redes de compartición pares a pares uri !izan software especial para descargar archivos, raJes como BirTorrenc, que es un protocolo pero también un programa.
3.1) Comprender el enrutamiento
El enrutamiento es el proceso de mover datos a través de redes o interconexiones de redes entre hosts o entre routers. la información es transmitida de acuerdo a las redes lP y direcciones lP individuales de los host en cuestión. Un router se encarga de mantener tablas de información acerca de otros routers en la red o interconexión de redes. También utiliza algunos protocolos TCP/IP diferentes para transferir los daros y para descubrir otros routers. El enrutamienco IP es el cipo más común de enrutamiento, justo como el TCP/IP es la.suite de protocolos más común. El enrutamiento IP ocurre en la capa de red del modelo OSI.
4.1) ¿Que es Internet?
En lugar de proporcionar una sentencia simple, intentaremos dar una aproximación descriptiva. Existen un par de formas de hacer esto. Una forma en describir los componentes hardware y software básico que lo forman. Otra forma es describir Internet en términos de infraestructura de red que proporciona servicios para aplicaciones distribuidas.
Internet publico es una red de computadores mundial, esto es, una red que conecta millones de dispositivos de cómputo a través del mundo. La mayoría de estos dispositivos de computo son los PC tradicionales de sobremesa, las estaciones de de trabajo basadas en UNIX , y los llamados servidores, que almacenan y transmiten información del tipo de paginas de web y mensajes de correo electrónico. Cada vez mas, dispositivos terminales no tradicionales de Internet, como asistentes digitales (PDA), televisores, computadores portátiles y tostadoras se están conectando a internet. En la jerga de Internet todos estos dispositivos se llaman host y sistemas terminales. Los sistemas terminales se conectan mediante enlace de comunicación. Distintos enlaces pueden transmitir datos a diferente velocidad, La tasa de transmisión de enlace se llama a menudo ancho de banda, y se mide normalmente en bits/segundo.
Los sistemas terminales normalmente no se enlazan directamente entre si mediante enlaces sencillos de comunicación, sino que se conectan unos a otros a través de dispositivos de conmutación llamados routers. Un router toma un trozo de información de los enlaces de comunicación de entrada. En la jerga de redes, al trozo de información se les conoce como paquete.
Los sistemas terminales, los routers, y otros elementos de internet, ejecutan protocolos que controlan el envio y la recepción de información de internet. TPC (protocolo de control de transmisión) e IP (protocolo Internet) son los dos protocolos mas importantes de Internet, los que estudiaremos con mayor profundidad en el punto 4.2.
El internet público es la red a la que normalmente uno se refiere a la Internet. Existen también muchas redes privadas, como redes corporativas o de gobierno, cuyos host no pueden intercambiar mensajes con host externos a la red privada (a menos que los mensajes pasen a través de los llamados contrafuegos, que restringen el flujo de mensajes a y desde la red). Estas redes privadas se conocen frecuentemente como intranets, ya que utilizan los mismos tipos de host, routers, enlaces y protocolos que Internet público.
A nivel técnico y de desarrollo, Internet ha sido posible gracias a la creación prueba e implementación de estándares de Internet. Estos estándares son desarrollados por el Internet Engineering Task Force (iETF). Los documentos estándares de IEFT se llaman RFC (solicitudes de comentarios). Las RFC tienden a ser completamente técnicas y detalladas. Definen protocolos como TCP, IP, HTTP (para la web) y SMTP (para estándares abiertos de correo electrónico. Hay mas de 3000 solicitudes de RFC diferentes.
Ahora que hemos analizado en lo abstracto las redes basadas en capas, es tiempo de ver algunos ejemplos.
Analizaremos dos arquitecturas de redes importantes: el modelo de referencia OSI y el modelo de referencia TCP/IP. Aunque ya casi no se utilizan los protocolos asociados con el modelo OSI, el modelo en sí es bastante general y sigue siendo válido; asimismo, las características en cada nivel siguen siendo muy importantes. El modelo TCP/IP tiene las propiedades opuestas: el modelo en sí no se utiliza mucho, pero los protocolos son usados ampliamente. Por esta razón veremos ambos elementos con detalle. Además, algunas veces podemos aprender más de los fracasos que de los éxitos.
5.1) Modelo de referencia OSI
Este modelo se basa en una propuesta desarrollada por la Organización Internacional de Normas (ISO) como el primer paso hacia la estandarización internacional de los protocolos utilizados en las diversas capas. Este modelo se revisó en 1995 y se le llama Modelo de referencia OSI (Interconexión de Sistemas Abiertos, Open Systems Interconnection) de la iso puesto que se ocupa de la conexión de sistemas abiertos; esto es, sistemas que están abiertos a la comunicación con otros sistemas. Para abreviar, lo llamaremos modelo OSI.
El modelo OSI tiene siete capas. Los principios que se aplicaron para llegar a las siete capas se pueden resumir de la siguiente manera:
A continuación mostramos el modelo OSI (sin el medio físico):

El cableado instalado apropiadamente y las redes inalámbricas son las claves para una planta física eficiente, el cable físico y las conexiones inalámbricas son el núcleo de una red rápida.
6.1) Redes alámbricas
Las redes alámbricas siguen siendo el tipo más común de conexión física que se realiza en las computadoras. Aunque las redes inalámbricas hao hecho avances en muchas organizaciones, aún prevalecen las conexiones alámbricas. La mayoría de las computadoras utilizan cableado de par trenzado para sus conexiones físicas.
7.1) La capa física
En capítulos anteriores hemos empezado a conocer un poco a las capas, pero en este capitulo estudiaremos esos tipos de capas; en este punto estudiaremos la capa física, la que se podría denominar como la mas baja capa en nuestro modelo de protocolos.
Ésta define las interfaces eléctricas, de temporización y demás interfaces mediante las cuales se envían los bits como señales a través de los canales. La capa física es la base sobre la cual se construye la red.
Este estudio se enfoca en los algoritmos para lograr una comunicación confiable y eficiente de unidades completas de información llamadas tramas (en vez de bits individuales, como en la capa física) entre dos máquinas adyacentes. Por adyacente, queremos decir que las dos máquinas están conectadas mediante un canal de comunicaciones que actúa de manera conceptual como un alambre (por ejemplo, un cable coaxial, una línea telefónica o un canal inalámbrico). La propiedad esencial de un canal que lo hace asemejarse a un “alambre” es que los bits se entregan exactamente en el mismo orden en que se enviaron.
Por desgracia, en ocaciones los canales de comunicación cometen errores. Además, sólo tienen una tasa de transmisión de datos finita y hay un retardo de propagación distinto de cero entre el momento en que se envía un bit y el momento en que se recibe. Estas limitaciones tienen implicaciones importantes para la eficiencia de la transferencia de datos. Los protocolos usados para comunicaciones deben considerar todos estos factores.
Los enlaces de red se pueden dividir en dos categorías: los que utilizan conexiones punto a punto y los que utilizan canales de difusión. En cualquier red de difusión, el asunto clave es la manera de determinar quién puede utilizar el canal cuando tiene competencia por él. Para aclarar este punto, considere una llamada en conferencia en la que seis personas, en seis teléfonos diferentes, están conectadas de modo que cada una puede oír y hablar con todas las demás. Es muy probable que cuando una de ellas deje de hablar, dos o más comiencen a hacerlo al mismo tiempo, lo que conducirá al caos. En una reunión cara a cara, el caos se evita por medios competentes. Por ejemplo, en una reunión la gente levanta la mano para solicitar permiso para hablar. Cuando sólo hay un canal disponible, es mucho más difícil determinar quién debería tener el turno. Se conocen muchos protocolos para resolver el problema, los cuales forman el contenido de este capítulo.
En la literatura, los canales de difusión a veces se denominan canales multiacceso o canales de acceso aleatorio. Los protocolos que se utilizan para determinar quién sigue en un canal multiacceso pertenecen a una subcapa de la capa de enlace de datos llamada subcapa MAC (Control de Acceso al Medio, del inglés Medium Access Control). La subcapa MAC tiene especial importancia en las LAN, en especial las inalámbricas puesto que el canal inalámbrico es de difusión por naturaleza. En contraste, las WAN usan enlaces punto a punto, excepto en las redes satelitales. Debido a que los canales multiacceso y las LAN están muy relacionados, en este capítulo analizaremos las LAN en general, además de algunos aspectos que no son estrictamente parte de la subcapa MAC, pero el tema principal será el control del canal.
ANTECEDENTES
Una red de computadoras (también llamada red de ordenadores o red informática) es un conjunto equipos (computadoras y dispositivos), conectados por medio de cables, señales, ondas o cualquier otro método de transporte de datos, para compartir información (archivos), recursos (discos, impresoras, programas, etc.) y servicios (acceso a una base de datos, internet, correo electrónico, chat, juegos, etc.). A cada una de las computadoras conectadas a la red se le denomina un nodo.
Las redes de computadora, son herramientas maravillosas que hoy en día constituyen una parte muy importante de nuestra sociedad dado a que todos los sistemas de comunicaciones, finanzas y traspaso de información se componen de redes de computadoras. Pero, a todo esto ¿Cual es la historia de esta útil herramienta?; pues para empezar, nos podemos remontar a 1957 cuando los Estados Unidos crearon la Advanced Research Projects Agency (ARPA), como organismo afiliado al departamento de defensa para impulsar el desarrollo tecnológico.
Posteriormente a la creación del ARPA, Leonard Kleinrock, un investigador del MIT escribía el primer libro sobre tecnologías basadas en la transmisión por un mismo cable de más de una comunicación.
En 1965, la ARPA patrocino un programa que trataba de analizar las redes de comunicación usando computadoras. Mediante este programa, la máquina TX-2 en el laboratorio Licoln del MIT y la AN/FSQ-32 del System Development Corporation de Santa Mónica en California, se enlazaron directamente mediante una línea delicada de 1200 bits por segundo.
En 1967, La ARPA convoca una reunión en Ann Arbor (Michigan), donde se discuten por primera vez aspectos sobre la futura ARPANET.
En 1968 la ARPA no espera más y llama a empresas y universidades para que propusieran diseños, con el objetivo de construir la futura red. La universidad de California gana la propuesta para el diseño del centro de gestión de red y la empresa BBN (Bolt Beraneck and Newman Inc.) El concurso de adjudicación para el desarrollo de la tecnología de conmutación de paquetes mediante la implementación de la Interfaz Message Processors (IMP)
En 1969, es un año clave para las redes de computadoras, ya que se construye la primera red de computadoras de la historia. Denominada ARPANET, estaba compuesta por cuatro nodos situados en UCLA (Universidad de California en los Angeles), SRI (Stanford Research Institute), UCBS (Universidad de California de Santa Bárbara, Los Angeles) y la Universidad de UTA.
CAPITULO 1. INTRODUCCIÓN
1.1) Usos de las redes de computadoras
Antes de introducirnos en los temas y términos con mayor detalle, sera mejor analizar el por qué las personas están interesadas en las redes de computadoras y para qué se pueden utilizar. Después de todo, si nadie estuviera interesado en ellas, se construirían muy pocas.
1.1.1) Aplicaciones de negocios
La mayoría de las empresas tienen una cantidad considerable de computadoras. Por ejemplo, tal vez una empresa tenga una computadora para cada empleado y las utilice para diseñar productos, escribir folletos y llevar la nómina. Al principio, algunas de estas computadoras tal vez hayan trabajado aisladas unas de otras, pero en algún momento, la administración podría decidir que es necesario conectarlas para distribuir la información en toda la empresa.
En términos generales, el asunto es compartir recursos y la meta es que todos los programas, equipo y en especial los datos estén disponibles para cualquier persona en la red, sin importar la ubicación física del recurso o del usuario. Un ejemplo obvio y de uso popular es el de un grupo de empleados de oficina que comparten una impresora. Ninguno de los individuos necesita realmente una impresora privada, por otro lado, una impresora en red de alto volumen es más económica, veloz y fácil de mantener que una extensa colección de impresoras individuales.
Pero, probablemente, compartir información sea aún más importante que compartir recursos físicos como impresoras y sistemas de respaldo en cinta magnética. Las empresas tanto pequeñas como grandes dependen vitalmente de la información computarizada. La mayoría tiene registros de clientes, información de productos, inventarios, estados de cuenta, información fiscal y muchos datos más en línea. Si de repente todas sus computadoras se desconectaran de la red, un banco no podría durar más de cinco minutos. Una planta moderna de manufactura con una línea de ensamble controlada por computadora no duraría ni cinco segundos. Incluso una pequeña agencia de viajes o un despacho legal compuesto de tres personas son altamente dependientes de las redes de computadoras para permitir a los empleados acceder a la información y los documentos relevantes de manera instantánea.
En las empresas más pequeñas es probable que todas las computadoras se encuentren en una sola oficina o tal vez en un solo edificio, pero en las empresas más grandes las computadoras y empleados se encuentran esparcidos en docenas de oficinas y plantas en muchos países. Sin embargo, un vendedor en Nueva York podría requerir acceso a una base de datos que se encuentra en Singapur. Las redes conocidas como VPN (Redes Privadas Virtuales, Virtual Private Networks) se pueden usar para unir las redes individuales, ubicadas en distintos sitios, en una sola red extendida.
A esta disposición se le conoce como modelo cliente-servidor. Es un modelo ampliamente utilizado y forma la base de muchas redes. La realización más popular es la de una aplicación web, en la cual el servidor genera páginas web basadas en su base de datos en respuesta a las solicitudes de los clientes que pueden actualizarla. El modelo cliente-servidor es aplicable cuando el cliente y el servidor se encuentran en el mismo edificio (y pertenecen a la misma empresa), pero también cuando están muy alejados.
Si analizamos detalladamente el modelo cliente-servidor, podremos ver que hay dos procesos (es decir, programas en ejecución) involucrados: uno en la máquina cliente y otro en la máquina servidor. La comunicación ocurre cuando el proceso cliente envía un mensaje a través de la red al proceso servidor. El proceso cliente espera un mensaje de respuesta. Cuando el proceso servidor obtiene la solicitud, lleva a cabo la tarea solicitada o busca los datos solicitados y devuelve una respuesta.
Un segundo objetivo al establecer una red de computadoras se relaciona con las personas y no con la información o con las computadoras. Una red de computadoras puede proveer un poderoso medio de comunicación entre los empleados. Ahora casi todas las empresas que tienen dos o más computadoras usan el e-mail, generalmente para la comunicación diaria. En algunos casos, las llamadas telefónicas entre los empleados se pueden realizar a través de la red de computadoras en lugar de usar la compañía telefónica. A esta tecnología se le conoce como telefonía IP o Voz sobre IP (VoIP) cuando se utiliza la tecnología de Internet. El micrófono y el altavoz en cada extremo pueden ser de un teléfono habilitado para VoIP o la computadora del empleado. Para las empresas ésta es una maravillosa forma de ahorrar en sus cuentas telefónicas.
Un tercer objetivo para muchas empresas es realizar negocios electrónicamente, en especial con los clientes y proveedores. A este nuevo modelo se le denomina e-commerce (comercio electrónico) y ha crecido con rapidez en los años recientes.
1.1.2) Aplicaciones domesticas
En 1977, Ken Olsen era presidente de Digital Equipment Corporation, en ese entonces la segunda empresa distribuidora de computadoras más importante del mundo (después de IBM). Cuando se le preguntó por qué Digital no iba a incursionar a lo grande en el mercado de las computadoras personales, dijo: “No hay motivos para que una persona tenga una computadora en su hogar”. La historia demostró lo contrario y Digital desapareció.
En los últimos años, probablemente la razón más importante sea acceder a Internet. En la actualidad muchos dispositivos electrónicos para el consumidor, como los decodificadores (set-top boxes), las consolas de juegos y los dispositivos de radio reloj, vienen con computadoras y redes integradas, especialmente redes inalámbricas; además las redes domésticas se utilizan ampliamente para actividades de entretenimiento, como escuchar, ver y crear música, fotos y videos.
El acceso a Internet ofrece a los usuarios domésticos conectividad a las computadoras remotas. Al igual que en las empresas, los usuarios domésticos pueden acceder a la información, comunicarse con otras personas y comprar productos y servicios mediante el comercio electrónico. Ahora el principal beneficio se obtiene al conectarse fuera del hogar.
1.1.3) Usuarios móviles
Las computadoras móviles como las laptops y las computadoras de bolsillo son uno de los segmentos de más rápido crecimiento en la industria de las computadoras. Sus ventas ya han sobrepasado a las de las computadoras de escritorio.
Con frecuencia las personas que pasan mucho tiempo fuera de su oficina u hogar desean usar sus dispositivos móviles para leer y enviar correos electrónicos, usar Twitter, ver películas, descargar música, jugar o simplemente navegar en la Web para buscar información. Quieren hacer todas las cosas que hacen en su hogar y en su oficina. Por ende, quieren hacerlo desde cualquier lugar, ya sea en tierra, en el mar o incluso en el aire.
Muchos de estos usuarios móviles permiten la conectividad a Internet. Como es imposible tener una conexión alámbrica en los autos, botes y aviones, hay mucho interés en las redes móviles. Las redes celulares operadas por las compañías telefónicas son un tipo conocido de red inalámbrica que nos ofrece cobertura para los teléfonos móviles. Los hotspots basados en el estándar 802.11 son otro tipo de red inalámbrica para computadoras móviles.
Las redes inalámbricas son de gran valor para las flotillas de camiones, taxis, vehículos de reparto y técnicos para mantenerse en contacto con su base. Las redes inalámbricas también son importantes para los militares. Si de repente usted tiene que pelear una guerra en cualquier parte de la Tierra, probablemente no sea buena idea confiar en que podrá usar la infraestructura de red local. Es mejor que lleve su propia red.
Por último, también hay aplicaciones verdaderamente móviles e inalámbricas, como cuando las personas caminan por las tiendas con computadoras de mano registrando el inventario. En muchos aeropuertos concurridos, los empleados de los negocios de renta de autos trabajan en el lote de estacionamiento con computadoras móviles inalámbricas; escanean los códigos de barras o chips RFID de los autos que regresan y su dispositivo móvil, que tiene una impresora integrada, llama a la computadora principal, obtiene la información sobre la renta e imprime la factura en ese instante.
1.1.4) Cuestiones sociales
Al igual que la imprenta hace 500 años, las redes de computadoras permiten a los ciudadanos comunes distribuir y ver el contenido en formas que no hubiera sido posible lograr antes. Pero con lo bueno viene lo malo, y esta posibilidad trae consigo muchas cuestiones sociales, políticas y éticas sin resolver; a continuación mencionaremos brevemente algunas de ellas, ya que para un estudio completo de las mismas se requeriría por lo menos todo un libro.
Las redes sociales, los tableros de mensajes, los sitios de compartición de contenido y varias aplicaciones más permiten a las personas compartir sus opiniones con individuos de pensamientos similares. Mientras que los temas estén restringidos a cuestiones técnicas o aficiones como la jardinería, no surgirán muchas dificultades.
Ahora hay sistemas automatizados que buscan redes de igual a igual y envían advertencias a los operadores de red y usuarios sospechosos de infringir los derechos de autor. En Estados Unidos a estas advertencias se les conoce como avisos de DCMA para quitar contenido según la Ley de Copyright del Milenio Digital. Esta búsqueda es una carrera armamentista, ya que es difícil detectar de manera confiable el momento en que se violan los derechos de autor.
Las redes de computadoras facilitan considerablemente la comunicación. También ayudan a las personas que operan la red con el proceso de husmear en el tráfico. Esto provoca conflictos sobre cuestiones como los derechos de los empleados frente a los derechos de los patrones. Muchas personas leen y escriben correos electrónicos en su trabajo. Muchos patrones han reclamado el derecho de leer y tal vez censurar los mensajes de los empleados, incluyendo los mensajes enviados desde una computadora en el hogar, después de las horas de trabajo. No todos los empleados están de acuerdo con esto, en especial con lo último.
Otro conflicto se centra alrededor de los derechos del gobierno frente a los derechos de los ciudadanos. El FBI ha instalado sistemas con muchos proveedores de servicios de Internet para analizar todo el correo electrónico entrante y saliente en busca de fragmentos que le interesen. Uno de los primeros sistemas se llamaba originalmente Carnivore, pero la mala publicidad provocó que cambiaran su nombre por el de DCS1000, algo más inocente. El objetivo de este sistema es espiar a millones de personas con la esperanza de encontrar información sobre actividades ilegales. Por desgracia para los espías, la Cuarta Enmienda a la Constitución de Estados Unidos prohíbe las búsquedas gubernamentales sin una orden de cateo, pero a menudo el gobierno ignora esta regulación.
Claro que el gobierno no es el único que amenaza la privacidad de las personas. El sector privado también participa al crear perfiles de los usuarios. Por ejemplo, los pequeños archivos llamados cookies que los navegadores web almacenan en las computadoras de los usuarios permiten a las empresas rastrear las actividades de los usuarios en el ciberespacio y también pueden permitir que los números de tarjetas de crédito, de seguro social y demás información confidencial se filtren por todo Internet.
Hay otro tipo de información que por lo general es indeseable. El correo electrónico basura (spam) se ha convertido en parte de la vida, ya que los emisores de correo electrónico basura (spammers) han recolectado millones de direcciones de correo electrónico y los aspirantes a vendedores pueden enviarles mensajes generados por computadora a un costo muy bajo. La inundación resultante de spam rivaliza con el flujo de mensajes de personas reales. Por fortuna hay software de filtrado capaz de leer y desechar el spam generado por otras computadoras, aunque su grado de éxito puede variar en forma considerable.
Existe también contenido destinado al comportamiento criminal. Las páginas web y los mensajes de correo electrónico con contenido activo (en esencia, programas o macros que se ejecutan en la máquina del receptor) pueden contener virus que invadan nuestra computadora. Podrían utilizarlos para robar las contraseñas de nuestras cuentas bancarias o hacer que nuestra computadora envíe spam como parte de una red zombie (botnet) o grupo de equipos comprometidos.
1.1.5) Telemática
La telemática es la disciplina científica y tecnológica que analiza e implementa servicios y aplicaciones que usan tanto los sistemas informáticos como las telecomunicaciones, como resultado de la unión de ambas disciplinas.
Son servicios o aplicaciones telemáticas, por ejemplo, cualquier tipo de comunicación a través de internet o los sistemas de posicionamiento global por ejemplo mandar un Email a otro país.
El termino "Telemática" ha evolucionado. En la actualidad se considera la rama de la ingeniería que se encarga de desarrollar sistemas telemáticos, tales como aplicaciones del internet de las cosas, domótica, robótica móvil y sistemas embebidos.
Para poder comprender mejor la unión entre las redes de computadoras y la telemática, podemos decir que, las redes de computadora son hoy en día una de las principales maneras de comunicación en todo el mundo; y como vimos anteriormente, la telemática es la ciencia que se encarga de estudiar las comunicaciones de todos tipos, teniendo ahí la enorme relación de estos dos temas.
1.2) Hardware de red
Ahora que estudiamos los principios referentes a los softwares, las aplicaciones y las cuestiones sociales aplicadas a las redes, podemos pasar a las cuestiones técnicas implicadas en su diseño. No existe una clasificación aceptada en la que encajen todas las redes, pero hay dos que sobresalen de manera importante: la tecnología de transmisión y la escala. Examinaremos ahora cada una de ellas por turno.
Hablando en sentido general, existen dos tipos de tecnología de transmisión que se emplean mucho en la actualidad: los enlaces de difusión (broadcast) y los enlaces de punto a punto. Los enlaces de punto a punto conectan pares individuales de máquinas. Para ir del origen al destino en una red formada por enlaces de punto a punto, los mensajes cortos (conocidos como paquetes en ciertos contextos) tal vez tengan primero que visitar una o más máquinas intermedias. A menudo es posible usar varias rutas de distintas longitudes, por lo que es importante encontrar las más adecuadas en las redes de punto a punto. A la transmisión punto a punto en donde sólo hay un emisor y un receptor se le conoce como unidifusión (unicasting).
Por el contrario, en una red de difusión todas las máquinas en la red comparten el canal de comunicación; los paquetes que envía una máquina son recibidos por todas las demás. Un campo de dirección dentro de cada paquete especifica a quién se dirige. Cuando una máquina recibe un paquete, verifica el campo de dirección. Si el paquete está destinado a la máquina receptora, ésta procesa el paquete; si el paquete está destinado para otra máquina, sólo lo ignora.
Por lo general, los sistemas de difusión también brindan la posibilidad de enviar un paquete a todos los destinos mediante el uso de un código especial en el campo de dirección. Cuando se transmite un paquete con este código, todas las máquinas en la red lo reciben y procesan. A este modo de operación se le conoce como difusión (broadcasting). Algunos sistemas de difusión también soportan la transmisión a un subconjunto de máquinas, lo cual se conoce como multidifusión (multicasting).
Hay un criterio alternativo para clasificar las redes: por su escala. La distancia es importante como medida de clasificación, ya que las distintas tecnologías se utilizan a diferentes escalas.

En la parte de arriba están las redes de área personal, las cuales están destinadas a una persona. Después se encuentran redes más grandes. Éstas se pueden dividir en redes de área local, de área metropolitana y de área amplia, cada una con una escala mayor que la anterior. Por último, a la conexión de dos o más redes se le conoce como interred (internetwork). La Internet de nivel mundial es sin duda el mejor ejemplo (aunque no el único) de una interred. Pronto tendremos interredes aún más grandes con la Internet interplanetaria que conecta redes a través del espacio.
1.2.1) Redes de área personal
Las redes de área personal, generalmente llamadas PAN (Personal Area Network) permiten a los dispositivos comunicarse dentro del rango de una persona. Un ejemplo común es una red inalámbrica que conecta a una computadora con sus periféricos. Casi todas las computadoras tienen conectado un monitor, un teclado, un ratón y una impresora. Sin la tecnología inalámbrica es necesario realizar esta conexión mediante cables. Hay tantos usuarios nuevos que batallan mucho para encontrar los cables adecuados y conectarlos en los orificios apropiados (aun cuando, por lo general, están codificados por colores), que la mayoría de los distribuidores de computadoras ofrecen la opción de enviar un técnico al hogar del usuario para que se encargue de ello. Para ayudar a estos usuarios, algunas empresas se pusieron de acuerdo para diseñar una red inalámbrica de corto alcance conocida como Bluetooth para conectar estos componentes sin necesidad de cables. La idea es que si sus dispositivos tienen Bluetooth, no necesitará cables. Sólo hay que ponerlos en el lugar apropiado, encenderlos y trabajarán en conjunto. Para muchas personas, esta facilidad de operación es una gran ventaja. Las redes PAN también se pueden construir con otras tecnologías que se comunican dentro de rangos cortos, como RFID en las tarjetas inteligentes y los libros de las bibliotecas.
1.2.2) Redes de área local
Las redes de área local, generalmente llamadas LAN (Local Area Networks), son redes de propiedad privada que operan dentro de un solo edificio, como una casa, oficina o fábrica. Las redes LAN se utilizan ampliamente para conectar computadoras personales y electrodomésticos con el fin de compartir recursos e intercambiar información. Cuando las empresas utilizan redes LAN se les conoce como redes empresariales.
Las redes LAN son muy populares en la actualidad, en especial en los hogares, los edificios de oficinas antiguos, las cafeterías y demás sitios en donde es muy problemático instalar cables. En estos sistemas, cada computadora tiene un módem y una antena que utiliza para comunicarse con otras computadoras. En la mayoría de los casos, cada computadora se comunica con un dispositivo en el techo. A este dispositivo se le denomina AP (Punto de Acceso, del inglés Access Point), enrutador inalámbrico o estación base; transmite paquetes entre las computadoras inalámbricas y también entre éstas e Internet. Hay un estándar para las redes LAN inalámbricas llamado IEEE 802.11, mejor conocido como WiFi. Opera a velocidades desde 11 hasta cientos de Mbps.
Las redes LAN alámbricas utilizan distintas tecnologías de transmisión. La mayoría utilizan cables de cobre, pero algunas usan fibra óptica. Las redes LAN tienen restricciones en cuanto a su tamaño, lo cual significa que el tiempo de transmisión en el peor de los casos es limitado y se sabe de antemano. Conocer estos límites facilita la tarea del diseño de los protocolos de red. Por lo general las redes LAN alámbricas que operan a velocidades que van de los 100 Mbps hasta un 1 Gbps, tienen retardo bajo (microsegundos o nanosegundos) y cometen muy pocos errores. Las redes LAN más recientes pueden operar a una velocidad de hasta 10 Gbps. En comparación con las redes inalámbricas, las redes LAN alámbricas son mucho mejores en cuanto al rendimiento, ya que es más fácil enviar señales a través de un cable o fibra que por el aire. La topología de muchas redes LAN alámbricas está basada en los enlaces de punto a punto. El estándar IEEE 802.3, comúnmente conocido como Ethernet, es hasta ahora el tipo más común de LAN alámbrica.

1.2.3) Redes de área metropolitana
Una Red de Área Metropolitana, o MAN (Metropolitan Area Network), cubre toda una ciudad. El ejemplo más popular de una MAN es el de las redes de televisión por cable disponibles en muchas ciudades. Estos sistemas surgieron a partir de los primeros sistemas de antenas comunitarias que se utilizaban en áreas donde la recepción de televisión por aire era mala. En esos primeros sistemas se colocaba una gran antena encima de una colina cercana y después se canalizaba una señal a las casas de los suscriptores. Al principio estos sistemas se diseñaban con fines específicos en forma local. Después, las empresas empezaron a entrar al negocio y consiguieron contratos de los gobiernos locales para cablear ciudades completas. El siguiente paso fue la programación de televisión e incluso canales completos diseñados sólo para cable. A menudo estos canales eran altamente especializados, como canales de sólo noticias, sólo deportes, sólo cocina, sólo jardinería, etc. Pero desde su comienzo hasta finales de la década de 1990, estaban diseñados sólo para la recepción de televisión. Cabe mencionar que la televisión por cable no es la única MAN. Los recientes desarrollos en el acceso inalámbrico a Internet de alta velocidad han originado otra, la cual se estandarizó como IEEE 802.16 y se conoce comúnmente como WiMAX.
1.2.4) Redes de área amplia
Una Red de Área Amplia, o WAN (Wide Area Network), abarca una extensa área geográfica, por lo general un país o continente. Empezaremos nuestra discusión con las redes WAN alámbricas y usaremos el ejemplo de una empresa con sucursales en distintas ciudades.
Podemos tomar como ejemplo la WAN de una red que conecta las oficinas en Perth, Melbourne y Brisbane. Cada una de estas oficinas contiene computadoras destinadas a ejecutar programas de usuario (aplicaciones). Seguiremos el uso tradicional y llamaremos a estas máquinas hosts. Al resto de la red que conecta estos hosts se le denomina subred de comunicación, o para abreviar sólo subred. La tarea de la subred es transportar los mensajes de host a host, al igual que el sistema telefónico transporta las palabras (en realidad sólo los sonidos) de la persona que habla a la persona que escucha.
En la mayoría de las redes WAN, la subred cuenta con dos componentes distintos: líneas de transmisión y elementos de conmutación. Las líneas de transmisión mueven bits entre máquinas. Se pueden fabricar a partir de alambre de cobre, fibra óptica o incluso enlaces de radio. Como la mayoría de las empresas no poseen líneas de transmisión, tienen que rentarlas a una compañía de telecomunicaciones. Los elementos de conmutación o switches son computadoras especializadas que conectan dos o más líneas de transmisión. Cuando los datos llegan por una línea entrante, el elemento de conmutación debe elegir una línea saliente hacia la cual reenviarlos. En el pasado, estas computadoras de conmutación han recibido varios nombres; ahora se conocen como enrutador.
1.2.5) Interredes
Existen muchas redes en el mundo, a menudo con distintos componentes de hardware y software. Por lo general, las personas conectadas a una red se quieren comunicar con las personas conectadas a una red distinta; para lograrlo, es necesario conectar redes distintas que con frecuencia son incompatibles. A una colección de redes interconectadas se le conoce como interred o internet. Utilizaremos estos términos en un sentido genérico, en contraste a la red Internet mundial (que es una internet específica), a la cual nos referiremos siempre con I mayúscula. Internet usa redes de ISP para conectar redes empresariales, domésticas y muchos otros tipos más.
A menudo se confunden las subredes, las redes y las interredes. El término “subred” tiene más sentido en el contexto de una red de área amplia, en donde se refiere a la colección de enrutadores y líneas de comunicación que pertenecen al operador de red. Como analogía, el sistema telefónico está compuesto por oficinas de conmutación telefónica conectadas entre sí mediante líneas de alta velocidad y conectadas a los hogares y negocios mediante líneas de baja velocidad. Estas líneas y equipos, que pertenecen y son administradas por la compañía telefónica, forman la subred del sistema telefónico. Los teléfonos en sí (los hosts en esta analogía) no forman parte de la subred.
Para profundizar en este tema, hablaremos sobre la forma en que se pueden conectar dos redes distintas. El nombre general para una máquina que realiza una conexión entre dos o más redes y provee la traducción necesaria, tanto en términos de hardware como de software, es puerta de enlace (gateway). Las puertas de enlace se distinguen por la capa en la que operan en la jerarquía de protocolos.
Como el beneficio de formar una internet es para conectar computadoras entre distintas redes, no es conveniente usar una puerta de enlace de una capa demasiado baja, ya que no podremos realizar conexiones entre distintos tipos de redes. Tampoco es conveniente usar una puerta de enlace de una capa demasiado alta, o de lo contrario la conexión sólo funcionará para ciertas aplicaciones. A la capa en la parte media que resulta ser la “ideal” se le denomina comúnmente capa de red; un enrutador es una puerta de enlace que conmuta paquetes en la capa de red. Así, para detectar una interred o internet hay que buscar una red que tenga enrutadores.

Existen muchas redes en el mundo, a menudo con distintos componentes de hardware y software. Por lo general, las personas conectadas a una red se quieren comunicar con las personas conectadas a una red distinta; para lograrlo, es necesario conectar redes distintas que con frecuencia son incompatibles. A una colección de redes interconectadas se le conoce como interred o internet. Utilizaremos estos términos en un sentido genérico, en contraste a la red Internet mundial (que es una internet específica), a la cual nos referiremos siempre con I mayúscula. Internet usa redes de ISP para conectar redes empresariales, domésticas y muchos otros tipos más.
A menudo se confunden las subredes, las redes y las interredes. El término “subred” tiene más sentido en el contexto de una red de área amplia, en donde se refiere a la colección de enrutadores y líneas de comunicación que pertenecen al operador de red. Como analogía, el sistema telefónico está compuesto por oficinas de conmutación telefónica conectadas entre sí mediante líneas de alta velocidad y conectadas a los hogares y negocios mediante líneas de baja velocidad. Estas líneas y equipos, que pertenecen y son administradas por la compañía telefónica, forman la subred del sistema telefónico. Los teléfonos en sí (los hosts en esta analogía) no forman parte de la subred.
Para profundizar en este tema, hablaremos sobre la forma en que se pueden conectar dos redes distintas. El nombre general para una máquina que realiza una conexión entre dos o más redes y provee la traducción necesaria, tanto en términos de hardware como de software, es puerta de enlace (gateway). Las puertas de enlace se distinguen por la capa en la que operan en la jerarquía de protocolos.
Como el beneficio de formar una internet es para conectar computadoras entre distintas redes, no es conveniente usar una puerta de enlace de una capa demasiado baja, ya que no podremos realizar conexiones entre distintos tipos de redes. Tampoco es conveniente usar una puerta de enlace de una capa demasiado alta, o de lo contrario la conexión sólo funcionará para ciertas aplicaciones. A la capa en la parte media que resulta ser la “ideal” se le denomina comúnmente capa de red; un enrutador es una puerta de enlace que conmuta paquetes en la capa de red. Así, para detectar una interred o internet hay que buscar una red que tenga enrutadores.
1.3) Software de red
Las primeras redes de computadoras se diseñaron teniendo en cuenta al hardware como punto principal y al software como secundario. Pero esta estrategia ya no funciona. Ahora el software de red está muy estructurado. En las siguientes secciones examinaremos con cierto detalle la técnica para estructurar el software.
1.3.1) Jerarquías de protocolos
Para reducir la complejidad de su diseño, la mayoría de las redes se organizan como una pila de capas o niveles, cada una construida a partir de la que está abajo. El número de capas, su nombre, el contenido de cada una y su función difieren de una red a otra. El propósito de cada capa es ofrecer ciertos servicios a las capas superiores, mientras les oculta los detalles relacionados con la forma en que se implementan los servicios ofrecidos.
En realidad este concepto es familiar y se utiliza en muchas áreas de las ciencias computacionales, en donde se le conoce de muchas formas: ocultamiento de información, tipos de datos abstractos, encapsulamiento de datos y programación orientada a objetos. La idea fundamental es que una pieza particular de software (o hardware) provee un servicio a sus usuarios pero mantiene ocultos los detalles de su estado interno y los algoritmos que utiliza.
Cuando la capa n en una máquina lleva a cabo una conversación con la capa n en otra máquina, a las reglas y convenciones utilizadas en esta conversación se les conoce como el protocolo de la capa n. En esencia, un protocolo es un acuerdo entre las partes que se comunican para establecer la forma en que se llevará a cabo esa comunicación.
En un conjunto de capas, las entidades que conforman las correspondientes capas en diferentes máquinas se llaman iguales (peers). Los iguales pueden ser procesos de software, dispositivos de hardware o incluso seres humanos. En otras palabras, los iguales son los que se comunican a través del protocolo.
Entre cada par de capas adyacentes hay una interfaz. Ésta define las operaciones y servicios primitivos que pone la capa más baja a disposición de la capa superior inmediata. Cuando los diseñadores de redes deciden cuántas capas incluir en una red y qué debe hacer cada una, la consideración más importante es definir interfaces limpias entre las capas. Al hacer esto es necesario que la capa desempeñe un conjunto específico de funciones bien entendidas. Además de minimizar la cantidad de información que se debe pasar entre las capas, las interfaces bien definidas también simplifican el reemplazo de una capa con un protocolo o implementación totalmente diferente (por ejemplo, reemplazar todas las líneas telefónicas por canales de satélite), ya que todo lo que se requiere del nuevo protocolo o implementación es que ofrezca exactamente el mismo conjunto de servicios a su vecino de arriba.
A un conjunto de capas y protocolos se le conoce como arquitectura de red. La especificación de una arquitectura debe contener suficiente información como para permitir que un programador escriba el programa o construya el hardware para cada capa, de manera que se cumpla correctamente el protocolo apropiado. Ni los detalles de la implementación ni la especificación de las interfaces forman parte de la arquitectura, ya que están ocultas dentro de las máquinas y no se pueden ver desde el exterior. Ni siquiera es necesario que las interfaces en todas las máquinas de una red sean iguales, siempre y cuando cada máquina pueda utilizar todos los protocolos correctamente. La lista de los protocolos utilizados por cierto sistema, un protocolo por capa, se le conoce como pila de protocolos.
Para reducir la complejidad de su diseño, la mayoría de las redes se organizan como una pila de capas o niveles, cada una construida a partir de la que está abajo. El número de capas, su nombre, el contenido de cada una y su función difieren de una red a otra. El propósito de cada capa es ofrecer ciertos servicios a las capas superiores, mientras les oculta los detalles relacionados con la forma en que se implementan los servicios ofrecidos.
En realidad este concepto es familiar y se utiliza en muchas áreas de las ciencias computacionales, en donde se le conoce de muchas formas: ocultamiento de información, tipos de datos abstractos, encapsulamiento de datos y programación orientada a objetos. La idea fundamental es que una pieza particular de software (o hardware) provee un servicio a sus usuarios pero mantiene ocultos los detalles de su estado interno y los algoritmos que utiliza.
Cuando la capa n en una máquina lleva a cabo una conversación con la capa n en otra máquina, a las reglas y convenciones utilizadas en esta conversación se les conoce como el protocolo de la capa n. En esencia, un protocolo es un acuerdo entre las partes que se comunican para establecer la forma en que se llevará a cabo esa comunicación.
En un conjunto de capas, las entidades que conforman las correspondientes capas en diferentes máquinas se llaman iguales (peers). Los iguales pueden ser procesos de software, dispositivos de hardware o incluso seres humanos. En otras palabras, los iguales son los que se comunican a través del protocolo.
Entre cada par de capas adyacentes hay una interfaz. Ésta define las operaciones y servicios primitivos que pone la capa más baja a disposición de la capa superior inmediata. Cuando los diseñadores de redes deciden cuántas capas incluir en una red y qué debe hacer cada una, la consideración más importante es definir interfaces limpias entre las capas. Al hacer esto es necesario que la capa desempeñe un conjunto específico de funciones bien entendidas. Además de minimizar la cantidad de información que se debe pasar entre las capas, las interfaces bien definidas también simplifican el reemplazo de una capa con un protocolo o implementación totalmente diferente (por ejemplo, reemplazar todas las líneas telefónicas por canales de satélite), ya que todo lo que se requiere del nuevo protocolo o implementación es que ofrezca exactamente el mismo conjunto de servicios a su vecino de arriba.
A un conjunto de capas y protocolos se le conoce como arquitectura de red. La especificación de una arquitectura debe contener suficiente información como para permitir que un programador escriba el programa o construya el hardware para cada capa, de manera que se cumpla correctamente el protocolo apropiado. Ni los detalles de la implementación ni la especificación de las interfaces forman parte de la arquitectura, ya que están ocultas dentro de las máquinas y no se pueden ver desde el exterior. Ni siquiera es necesario que las interfaces en todas las máquinas de una red sean iguales, siempre y cuando cada máquina pueda utilizar todos los protocolos correctamente. La lista de los protocolos utilizados por cierto sistema, un protocolo por capa, se le conoce como pila de protocolos.
1.3.2) Aspectos de diseño de capas
Algunos de los aspectos clave de diseño que ocurren en las redes de computadoras están presentes en las diversas capas.
La confiabilidad es el aspecto de diseño enfocado en verificar que una red opere correctamente, aun cuando esté formada por una colección de componentes que sean, por sí mismos, poco confiables. Piense en los bits de un paquete que viajan a través de la red. Existe la posibilidad de que algunas de estas piezas se reciban dañadas (invertidas) debido al ruido eléctrico, a las señales aleatorias inalámbricas, a fallas en el hardware, a errores del software, etc.
Un mecanismo para detectar errores en la información recibida utiliza códigos de detección de errores. Así, la información que se recibe de manera incorrecta puede retransmitirse hasta que se reciba de manera correcta. Los códigos más poderosos cuentan con corrección de errores, en donde el mensaje correcto se recupera a partir de los bits posiblemente incorrectos que se recibieron originalmente. Ambos mecanismos funcionan añadiendo información redundante. Se utilizan en capas bajas para proteger los paquetes que se envían a través de enlaces individuales, y en capas altas para verificar que el contenido correcto fue recibido.
Otro aspecto de la confiabilidad consiste en encontrar una ruta funcional a través de una red. A menudo hay múltiples rutas entre origen y destino, y en una red extensa puede haber algunos enlaces o enrutadores descompuestos. Suponga que la red está caída en Alemania. Los paquetes que se envían de Londres a Roma a través de Alemania no podrán pasar, pero para evitar esto, podríamos enviar los paquetes de Londres a Roma vía París. La red debería tomar esta decisión de manera automática. A este tema se le conoce como enrutamiento.
Un segundo aspecto de diseño se refiere a la evolución de la red. Con el tiempo, las redes aumentan su tamaño y emergen nuevos diseños que necesitan conectarse a la red existente. Recientemente vimos el mecanismo de estructuración clave que se utiliza para soportar el cambio dividiendo el problema general y ocultando los detalles de la implementación: distribución de protocolos en capas. También existen muchas otras estrategias.
Como hay muchas computadoras en la red, cada capa necesita un mecanismo para identificar los emisores y receptores involucrados en un mensaje específico. Este mecanismo se conoce como direccionamiento o nombramiento en las capas altas y bajas, respectivamente.
Un aspecto del crecimiento es que las distintas tecnologías de red a menudo tienen diferentes limitaciones. Otro ejemplo es el de las diferencias en el tamaño máximo de un mensaje que las redes pueden transmitir. Esto provoca la creación de mecanismos para desensamblar, transmitir y después volver a ensamblar los mensajes. A este tema en general se le conoce como interconexión de redes (internetworking).
Un tercer aspecto de diseño radica en la asignación de recursos. Las redes proveen un servicio a los hosts desde sus recursos subyacentes, como la capacidad de las líneas de transmisión. Para hacer bien su trabajo necesitan mecanismos que dividan sus recursos de manera que un host no interfiera demasiado con otro host.
Muchos diseños comparten el ancho de banda de una red en forma dinámica, de acuerdo con las necesidades a corto plazo de los hosts, en vez de otorgar a cada host una fracción fija del ancho de banda que puede llegar a utilizar o quizás no. A este diseño se le denomina multiplexado estadístico, lo cual significa que se comparten los recursos con base en la demanda. Se puede aplicar en capas bajas para un solo enlace o en capas altas para una red, o incluso para aplicaciones que utilizan la red.
Algunos de los aspectos clave de diseño que ocurren en las redes de computadoras están presentes en las diversas capas.
La confiabilidad es el aspecto de diseño enfocado en verificar que una red opere correctamente, aun cuando esté formada por una colección de componentes que sean, por sí mismos, poco confiables. Piense en los bits de un paquete que viajan a través de la red. Existe la posibilidad de que algunas de estas piezas se reciban dañadas (invertidas) debido al ruido eléctrico, a las señales aleatorias inalámbricas, a fallas en el hardware, a errores del software, etc.
Un mecanismo para detectar errores en la información recibida utiliza códigos de detección de errores. Así, la información que se recibe de manera incorrecta puede retransmitirse hasta que se reciba de manera correcta. Los códigos más poderosos cuentan con corrección de errores, en donde el mensaje correcto se recupera a partir de los bits posiblemente incorrectos que se recibieron originalmente. Ambos mecanismos funcionan añadiendo información redundante. Se utilizan en capas bajas para proteger los paquetes que se envían a través de enlaces individuales, y en capas altas para verificar que el contenido correcto fue recibido.
Otro aspecto de la confiabilidad consiste en encontrar una ruta funcional a través de una red. A menudo hay múltiples rutas entre origen y destino, y en una red extensa puede haber algunos enlaces o enrutadores descompuestos. Suponga que la red está caída en Alemania. Los paquetes que se envían de Londres a Roma a través de Alemania no podrán pasar, pero para evitar esto, podríamos enviar los paquetes de Londres a Roma vía París. La red debería tomar esta decisión de manera automática. A este tema se le conoce como enrutamiento.
Un segundo aspecto de diseño se refiere a la evolución de la red. Con el tiempo, las redes aumentan su tamaño y emergen nuevos diseños que necesitan conectarse a la red existente. Recientemente vimos el mecanismo de estructuración clave que se utiliza para soportar el cambio dividiendo el problema general y ocultando los detalles de la implementación: distribución de protocolos en capas. También existen muchas otras estrategias.
Como hay muchas computadoras en la red, cada capa necesita un mecanismo para identificar los emisores y receptores involucrados en un mensaje específico. Este mecanismo se conoce como direccionamiento o nombramiento en las capas altas y bajas, respectivamente.
Un aspecto del crecimiento es que las distintas tecnologías de red a menudo tienen diferentes limitaciones. Otro ejemplo es el de las diferencias en el tamaño máximo de un mensaje que las redes pueden transmitir. Esto provoca la creación de mecanismos para desensamblar, transmitir y después volver a ensamblar los mensajes. A este tema en general se le conoce como interconexión de redes (internetworking).
Un tercer aspecto de diseño radica en la asignación de recursos. Las redes proveen un servicio a los hosts desde sus recursos subyacentes, como la capacidad de las líneas de transmisión. Para hacer bien su trabajo necesitan mecanismos que dividan sus recursos de manera que un host no interfiera demasiado con otro host.
Muchos diseños comparten el ancho de banda de una red en forma dinámica, de acuerdo con las necesidades a corto plazo de los hosts, en vez de otorgar a cada host una fracción fija del ancho de banda que puede llegar a utilizar o quizás no. A este diseño se le denomina multiplexado estadístico, lo cual significa que se comparten los recursos con base en la demanda. Se puede aplicar en capas bajas para un solo enlace o en capas altas para una red, o incluso para aplicaciones que utilizan la red.
1.3.3) Comparación entre servicio orientado a conexión y servicio sin conexión
Las capas pueden ofrecer dos tipos distintos de servicio a las capas superiores: orientado a conexión y sin conexión. En esta sección analizaremos estos dos tipos y examinaremos las diferencias entre ellos.
El servicio orientado a conexión está modelado a partir del sistema telefónico. Para hablar con alguien levantamos el auricular, marcamos el número, hablamos y después colgamos. De manera similar, para usar un servicio de red orientado a conexión, el usuario del servicio establece primero una conexión, la utiliza y después la libera. El aspecto esencial de una conexión es que funciona como un tubo: el emisor mete objetos (bits) en un extremo y el receptor los toma en el otro extremo. En la mayoría de los casos se conserva el orden de manera que los bits llegan en el orden en el que se enviaron.
En contraste al servicio orientado a la conexión, el servicio sin conexión está modelado a partir del sistema postal. Cada mensaje (carta) lleva la dirección de destino completa, y cada uno es enrutado hacia los nodos intermedios dentro del sistema, en forma independiente a todos los mensajes subsecuentes. Hay distintos nombres para los mensajes en diferentes contextos: un paquete es un mensaje en la capa de red. Cuando los nodos intermedios reciben un mensaje completo antes de enviarlo al siguiente nodo, se le llama conmutación de almacenamiento y envío.
Cada tipo de servicio se puede caracterizar con base en su confiabilidad. Algunos servicios son confiables en cuanto a que nunca pierden datos. Por lo general, para implementar un servicio confiable, el receptor tiene que confirmar la recepción de cada mensaje, de manera que el emisor esté seguro de que hayan llegado. El proceso de confirmación de recepción introduce sobrecarga y retardos, que a menudo valen la pena pero algunas veces no son deseables. Una situación común en la que es apropiado un servicio confiable orientado a la conexión es la transferencia de archivos.
El servicio confiable orientado a la conexión tiene dos variaciones menores: secuencias de mensajes y flujos de bytes. En la primera variante se conservan los límites de los mensajes. Cuando se envían dos mensajes de 1024 bytes, llegan como dos mensajes distintos de 1024 bytes y nunca como un mensaje de 2048 bytes. En la segunda variante, la conexión es simplemente un flujo de bytes sin límites en los mensajes.
Las capas pueden ofrecer dos tipos distintos de servicio a las capas superiores: orientado a conexión y sin conexión. En esta sección analizaremos estos dos tipos y examinaremos las diferencias entre ellos.
El servicio orientado a conexión está modelado a partir del sistema telefónico. Para hablar con alguien levantamos el auricular, marcamos el número, hablamos y después colgamos. De manera similar, para usar un servicio de red orientado a conexión, el usuario del servicio establece primero una conexión, la utiliza y después la libera. El aspecto esencial de una conexión es que funciona como un tubo: el emisor mete objetos (bits) en un extremo y el receptor los toma en el otro extremo. En la mayoría de los casos se conserva el orden de manera que los bits llegan en el orden en el que se enviaron.
En contraste al servicio orientado a la conexión, el servicio sin conexión está modelado a partir del sistema postal. Cada mensaje (carta) lleva la dirección de destino completa, y cada uno es enrutado hacia los nodos intermedios dentro del sistema, en forma independiente a todos los mensajes subsecuentes. Hay distintos nombres para los mensajes en diferentes contextos: un paquete es un mensaje en la capa de red. Cuando los nodos intermedios reciben un mensaje completo antes de enviarlo al siguiente nodo, se le llama conmutación de almacenamiento y envío.
Cada tipo de servicio se puede caracterizar con base en su confiabilidad. Algunos servicios son confiables en cuanto a que nunca pierden datos. Por lo general, para implementar un servicio confiable, el receptor tiene que confirmar la recepción de cada mensaje, de manera que el emisor esté seguro de que hayan llegado. El proceso de confirmación de recepción introduce sobrecarga y retardos, que a menudo valen la pena pero algunas veces no son deseables. Una situación común en la que es apropiado un servicio confiable orientado a la conexión es la transferencia de archivos.
El servicio confiable orientado a la conexión tiene dos variaciones menores: secuencias de mensajes y flujos de bytes. En la primera variante se conservan los límites de los mensajes. Cuando se envían dos mensajes de 1024 bytes, llegan como dos mensajes distintos de 1024 bytes y nunca como un mensaje de 2048 bytes. En la segunda variante, la conexión es simplemente un flujo de bytes sin límites en los mensajes.
1.3.4) Primitivas de servicios
Un servicio se puede especificar de manera formal como un conjunto de primitivas (operaciones) disponibles a los procesos de usuario para que accedan al servicio. Estas primitivas le indican al servicio que desarrollen alguna acción o que informen sobre la acción que haya tomado una entidad par. Si la pila de protocolos se encuentra en el sistema operativo, como se da en la mayoría de los casos, por lo general las primitivas son llamadas al sistema. Estas llamadas provocan un salto al modo de kernel, que a su vez devuelve el control de la máquina al sistema operativo para que envíe los paquetes necesarios. El conjunto de primitivas disponibles depende de la naturaleza del servicio que se va a ofrecer. Las primitivas para el servicio orientado a conexión son distintas de las primitivas para el servicio sin conexión. Como un ejemplo mínimo de las primitivas de servicio que se podrían ofrecer para implementar un flujo de bytes confiable.

Primero, el servidor ejecuta LISTEN para indicar que está preparado para aceptar conexiones entrantes. Una forma común de implementar LISTEN es mediante una llamada de bloqueo del sistema. Después de ejecutar la primitiva, el proceso servidor se bloquea hasta que aparezca una petición de conexión. Después, el proceso cliente ejecuta CONNECT para establecer una conexión con el servidor. La llamada a CONNECT necesita especificar con quién se va a realizar la conexión, por lo que podría incluir un parámetro para proporcionar la dirección del servidor. El proceso cliente se suspende hasta que haya una respuesta. Cuando el paquete llega al servidor, el sistema operativo ve que el paquete solicita una conexión. Verifica que haya alguien escuchando y, en ese caso, desbloquea al que está escuchando. Ahora el proceso servidor puede establecer la conexión con la llamada a ACCEPT. Esta llamada envía una respuesta de vuelta al proceso cliente para aceptar la conexión. Al llegar esta respuesta se libera el cliente. En este punto, el cliente y el servidor se están ejecutando y tienen una conexión establecida. El siguiente paso es que el servidor ejecute RECEIVE y se prepare para aceptar la primera petición. Por lo general, el servidor hace esto justo después de ser liberado de la primitiva LISTEN, antes de que la confirmación de recepción pueda regresar al cliente. La llamada a RECEIVE bloquea al servidor. Entonces, el cliente ejecuta SEND para transmitir su petición (3) después de ejecutar RECEIVE para obtener la respuesta. La llegada del paquete solicitado a la máquina servidor desbloquea el servidor, de manera que pueda manejar la petición. Después de realizar su trabajo, el servidor usa SEND para devolver la respuesta al cliente (4). Al llegar este paquete se desbloquea el cliente, que ahora puede inspeccionar la respuesta. Si el cliente tiene peticiones adicionales, puede hacerlas ahora. Cuando el cliente termina, ejecuta DISCONNECT para terminar la conexión (5). Por lo general una primitiva DISCONNECT inicial es una llamada de bloqueo, la cual suspende al cliente y envía un paquete al servidor para indicar que ya no necesita la conexión. Cuando el servidor recibe el paquete también emite una primitiva DISCONNECT por su cuenta, envía una confirmación de recepción al cliente y libera la conexión (6). Cuando el paquete del servidor regresa a la máquina cliente, se libera el proceso cliente y se interrumpe la conexión. En esencia, así es como funciona la comunicación orientada a conexión.
1.3.5) La relación entre servicios y protocolos
Los servicios y los protocolos son conceptos distintos. Esta distinción es tan importante que la enfatizaremos una vez más. Un servicio es un conjunto de primitivas (operaciones) que una capa proporciona a la capa que está encima de ella. El servicio define qué operaciones puede realizar la capa en beneficio de sus usuarios, pero no dice nada sobre cómo se implementan estas operaciones. Un servicio se relaciona con una interfaz entre dos capas, en donde la capa inferior es el proveedor del servicio y la capa superior es el usuario.
En contraste, un protocolo es un conjunto de reglas que rigen el formato y el significado de los paquetes o mensajes que intercambian las entidades iguales en una capa. Las entidades utilizan protocolos para implementar sus definiciones de servicios. Pueden cambiar sus protocolos a voluntad, siempre y cuando no cambien el servicio visible para sus usuarios. De esta manera, el servicio y el protocolo no dependen uno del otro. Éste es un concepto clave que cualquier diseñador de red debe comprender bien.
En contraste, los protocolos se relacionan con los paquetes que se envían entre las entidades pares de distintas máquinas. Es muy importante no confundir los dos conceptos.
Un servicio se puede especificar de manera formal como un conjunto de primitivas (operaciones) disponibles a los procesos de usuario para que accedan al servicio. Estas primitivas le indican al servicio que desarrollen alguna acción o que informen sobre la acción que haya tomado una entidad par. Si la pila de protocolos se encuentra en el sistema operativo, como se da en la mayoría de los casos, por lo general las primitivas son llamadas al sistema. Estas llamadas provocan un salto al modo de kernel, que a su vez devuelve el control de la máquina al sistema operativo para que envíe los paquetes necesarios. El conjunto de primitivas disponibles depende de la naturaleza del servicio que se va a ofrecer. Las primitivas para el servicio orientado a conexión son distintas de las primitivas para el servicio sin conexión. Como un ejemplo mínimo de las primitivas de servicio que se podrían ofrecer para implementar un flujo de bytes confiable.

1.3.5) La relación entre servicios y protocolos
Los servicios y los protocolos son conceptos distintos. Esta distinción es tan importante que la enfatizaremos una vez más. Un servicio es un conjunto de primitivas (operaciones) que una capa proporciona a la capa que está encima de ella. El servicio define qué operaciones puede realizar la capa en beneficio de sus usuarios, pero no dice nada sobre cómo se implementan estas operaciones. Un servicio se relaciona con una interfaz entre dos capas, en donde la capa inferior es el proveedor del servicio y la capa superior es el usuario.
En contraste, un protocolo es un conjunto de reglas que rigen el formato y el significado de los paquetes o mensajes que intercambian las entidades iguales en una capa. Las entidades utilizan protocolos para implementar sus definiciones de servicios. Pueden cambiar sus protocolos a voluntad, siempre y cuando no cambien el servicio visible para sus usuarios. De esta manera, el servicio y el protocolo no dependen uno del otro. Éste es un concepto clave que cualquier diseñador de red debe comprender bien.
En contraste, los protocolos se relacionan con los paquetes que se envían entre las entidades pares de distintas máquinas. Es muy importante no confundir los dos conceptos.
CAPITULO 2. REDES DE ÁREA LOCAL
Como hemos ya visto, las redes de área local o LAN, son redes de propiedad privada que operan dentro de un solo edificio, como una casa, oficina o fábrica. Las redes LAN se utilizan ampliamente para conectar computadoras personales y electrodomésticos con el fin de compartir recursos e intercambiar información. Cuando las empresas utilizan redes LAN se les conoce como redes empresariales.
2.1) Estudio de las redes de área local
2.1.1) Definiendo una LAN
Recordemos que la LAN en una red de computadoras que está concentrada en un área geográfica, como un edificio o un campus universitarios. Cuando un usuario accede a Internet desde una universidad, el acceso es casi siempre mediante una LAN. Para este tipo de acceso a internet, el host del usuario esta en un nodo de la LAN, y la LAN proporciona acceso a Internet a través de de un router.
La LAN es un simple enlace entre el host de cada usuario y el router; utiliza, por tanto, un protocolo de la capa de enlace, parte del cual es un protocolo de acceso múltiple. La tasa de transmisión, R, de la mayoría de las redes de área local es muy alta. Incluso en los primeros años de la década de 1980, LAN de 10 Mbps eran habituales; en la actualidad, son comunes las redes de 100 Mbps, y están disponibles des de 1 Gbps.
2.1.1) Definiendo una LAN
Recordemos que la LAN en una red de computadoras que está concentrada en un área geográfica, como un edificio o un campus universitarios. Cuando un usuario accede a Internet desde una universidad, el acceso es casi siempre mediante una LAN. Para este tipo de acceso a internet, el host del usuario esta en un nodo de la LAN, y la LAN proporciona acceso a Internet a través de de un router.
La LAN es un simple enlace entre el host de cada usuario y el router; utiliza, por tanto, un protocolo de la capa de enlace, parte del cual es un protocolo de acceso múltiple. La tasa de transmisión, R, de la mayoría de las redes de área local es muy alta. Incluso en los primeros años de la década de 1980, LAN de 10 Mbps eran habituales; en la actualidad, son comunes las redes de 100 Mbps, y están disponibles des de 1 Gbps.
2.1.2) Transferencia de datos en una LAN
Generalmente, cuando la información es transferida en una LAN se envía de forma serial a través de cableado de par trenzado. La Transferencia serial de datos significa la transferencia de un bit a la vez, en otras palabras, transferir en una sola cadena de bits.
Este es el formato regularmente utilizado para enviar información de un adaptador de red a otro. Ahora, discutiremos esta ordenación a mayor profundidad. Digamos que un usuario desea enviar un archivo de texto pequeño (tamaño de 10 bytes) a otro usuario en la red. Hay muchas formas de hacer esto, una de ellas sería mapear una unidad de red a otra computadora de usuario)' simplemente copiar y pegar el archivo de texto al disco duro de la otra computadora. Cuando ocurre esto, suceden algunas cosas:
En este tipo de red, cuando una computadora envía datos, estos son transmitidos por defecto (broadcast) a cada uno de los hosts en la red. El problema con es te método es que generalmente solo hay un receptor destinado para la información, así que el resto de las computadoras simplemente deshechan los paquetes de datos. Esto, a su vez, desperdicia ancho de banda de red. Para aligerar este problema, se desarrolló el switcheo Ethernet hace cerca de 15 años y aún es utilizado en la mayoría de redes hoy en día. El Switcheo o Switching tiene muchas ventajas, una de ellas es que el switch solo envía tráfico unicast.
Unicast describe la situación en la cual la información se envía a un solo host. Esto reduce el tráfico de red en gran medida y cambien ayuda con los paquetes perdidos y duplicados.
Generalmente, cuando la información es transferida en una LAN se envía de forma serial a través de cableado de par trenzado. La Transferencia serial de datos significa la transferencia de un bit a la vez, en otras palabras, transferir en una sola cadena de bits.
Este es el formato regularmente utilizado para enviar información de un adaptador de red a otro. Ahora, discutiremos esta ordenación a mayor profundidad. Digamos que un usuario desea enviar un archivo de texto pequeño (tamaño de 10 bytes) a otro usuario en la red. Hay muchas formas de hacer esto, una de ellas sería mapear una unidad de red a otra computadora de usuario)' simplemente copiar y pegar el archivo de texto al disco duro de la otra computadora. Cuando ocurre esto, suceden algunas cosas:
- Primero, el archivo de texto se empaqueta por el sistema operativo. El paquete será ligeramente más grande que el archivo original. Entonces, paquete es enviado al adaptador de red.
- A continuación, el adaptador de red coma el paquete y lo ubica dentro de un frame, el cual es ligeramenre más grande que un paquete; generalmenre, este será una frame Ethernet.
- Ahora se debe enviar el frame de información al medio físico: el cableado. Para hacer eso, el adaptador de red divide el frame de información en una cadena serial de daros que se envían un bit a la vez a través de los cables a la otra computadora.
- La computadora receptora roma la cadena de bits y recrea el frame de daros. Después de analizar el frame y verificar que, de hecho, es el receptor destino, la computadora desmonta el frame de información para que solo quede el paquete.
- El paquete se envía al sistema operativo y, finalmente, el archivo de texto aparece en el disco duro de la computadora.
En este tipo de red, cuando una computadora envía datos, estos son transmitidos por defecto (broadcast) a cada uno de los hosts en la red. El problema con es te método es que generalmente solo hay un receptor destinado para la información, así que el resto de las computadoras simplemente deshechan los paquetes de datos. Esto, a su vez, desperdicia ancho de banda de red. Para aligerar este problema, se desarrolló el switcheo Ethernet hace cerca de 15 años y aún es utilizado en la mayoría de redes hoy en día. El Switcheo o Switching tiene muchas ventajas, una de ellas es que el switch solo envía tráfico unicast.
Unicast describe la situación en la cual la información se envía a un solo host. Esto reduce el tráfico de red en gran medida y cambien ayuda con los paquetes perdidos y duplicados.
2.1.3) Configurar el protocolo de red
El Protocolo de Internet o IP es la parte de TCP/IP que, entre otras cosas, gobierna las direcciones IP. La dirección IP es la piedra angular de las redes porque define la computadora o host en la que usted está trabajando. Hoy en día, cada computadora y muchos otros dispositivos tienen esa dirección. Una dirección IP le permite a cada computadora enviar y recibir información de un lado a otro de una manera ordenada y eficiente. las direcciones IP son parecidas a la dirección de su casa. Sin embargo, mientras que su dirección identifica el número de la casa y la calle en la que vive, una dirección IP identifica el número de computadora y la red en la que vive. Un ejemplo típico de una dirección IP sería 192.168.1.1.
Cada dirección IP se divide en dos partes: la porción de red (en este caso 192.168.1), la cual es la red de la que su computadora es miembro y la porción de host, el cual es el número individual de su computadora que diferencia su computadora de las demás en la red. En este caso, la porción de red es 1. ¿Cómo sabemos esto?La máscara de subred nos lo dice.
El Protocolo de Internet o IP es la parte de TCP/IP que, entre otras cosas, gobierna las direcciones IP. La dirección IP es la piedra angular de las redes porque define la computadora o host en la que usted está trabajando. Hoy en día, cada computadora y muchos otros dispositivos tienen esa dirección. Una dirección IP le permite a cada computadora enviar y recibir información de un lado a otro de una manera ordenada y eficiente. las direcciones IP son parecidas a la dirección de su casa. Sin embargo, mientras que su dirección identifica el número de la casa y la calle en la que vive, una dirección IP identifica el número de computadora y la red en la que vive. Un ejemplo típico de una dirección IP sería 192.168.1.1.
Cada dirección IP se divide en dos partes: la porción de red (en este caso 192.168.1), la cual es la red de la que su computadora es miembro y la porción de host, el cual es el número individual de su computadora que diferencia su computadora de las demás en la red. En este caso, la porción de red es 1. ¿Cómo sabemos esto?La máscara de subred nos lo dice.
2.1.4) Tipos de LAN
El primero y mas común de los tipos de LAN es la alámbrica. Aquí, las computadoras y otros dispositivos están interconectados utilizando cables de par trenzado de cobre. Estos cables tienen un conector RJ45 en cada extremo, el cual es la conexión real a los puercos RJ45 que residen en el adaptador de red de la computadora y en los hubs, swirches, o routers.
Históricamente, las redes alámbricas fueron significativamente más rápidas que las redes inalámbricas, pero ahora la diferencia de velocidad entre las dos es mucho m¡\s pequeña debido al hecho de que las tecnologías de redes inalámbricas han progresado a saltos agigantados desde la década pasada. Una Red de Área Local lnalámbrica (WLAN) tiene muchas ventajas, la más obvia es la movilidad. Una persona con una laptop, PDA u otro dispositivo puede trabajar donde sea. Sin embargo, las LANs inalámbricas tienen muchos problemas de seguridad y, debido a esto, algunas compañías han optado no utilizarlas en sus oficinas principales.
También existe otro tipo de LAN, la LAN Virtual o VLAN. Una LAN Virtual es un grupo de hosts con un conjunto común de requerimientos que se comunican como si estuvieran conectados de una manera normal en un switch, sin importar su localización física. Una VLAN se implementa a un segmento de red, reduce colisiones, organiza la red, impulsa el desempeño e incrementa la seguridad. Generalmente los swicches controlan la VLAN. Como subneteo, una VLAN segmenta a una red y puede aislar el tráfico. Pero a diferencia del subneteo, una VLAN puede establecerse de manera física.
En la década de 1980 y en los primeros años de la década de 1990, eran populares dos clases de tecnologías LAN en el ámbito. La primera clase estaba formada por redes de área local Ethernet (conocidas también como redes de área local 802.3), que se basan en acceso aleatorio. La segunda clase de tecnologías LAN eran eran las de paso de testigo, como token ring (conocida también como IEEE 802.5).

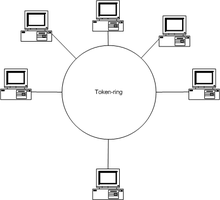
El primero y mas común de los tipos de LAN es la alámbrica. Aquí, las computadoras y otros dispositivos están interconectados utilizando cables de par trenzado de cobre. Estos cables tienen un conector RJ45 en cada extremo, el cual es la conexión real a los puercos RJ45 que residen en el adaptador de red de la computadora y en los hubs, swirches, o routers.
Históricamente, las redes alámbricas fueron significativamente más rápidas que las redes inalámbricas, pero ahora la diferencia de velocidad entre las dos es mucho m¡\s pequeña debido al hecho de que las tecnologías de redes inalámbricas han progresado a saltos agigantados desde la década pasada. Una Red de Área Local lnalámbrica (WLAN) tiene muchas ventajas, la más obvia es la movilidad. Una persona con una laptop, PDA u otro dispositivo puede trabajar donde sea. Sin embargo, las LANs inalámbricas tienen muchos problemas de seguridad y, debido a esto, algunas compañías han optado no utilizarlas en sus oficinas principales.
También existe otro tipo de LAN, la LAN Virtual o VLAN. Una LAN Virtual es un grupo de hosts con un conjunto común de requerimientos que se comunican como si estuvieran conectados de una manera normal en un switch, sin importar su localización física. Una VLAN se implementa a un segmento de red, reduce colisiones, organiza la red, impulsa el desempeño e incrementa la seguridad. Generalmente los swicches controlan la VLAN. Como subneteo, una VLAN segmenta a una red y puede aislar el tráfico. Pero a diferencia del subneteo, una VLAN puede establecerse de manera física.
En la década de 1980 y en los primeros años de la década de 1990, eran populares dos clases de tecnologías LAN en el ámbito. La primera clase estaba formada por redes de área local Ethernet (conocidas también como redes de área local 802.3), que se basan en acceso aleatorio. La segunda clase de tecnologías LAN eran eran las de paso de testigo, como token ring (conocida también como IEEE 802.5).
2.1.5) Introducción a las redes perimetrales
Una red perímetral (también conocida como una zona desmilitarizada o DMZ) es una red pequeña que se implementa separadamente de una LAN privada de la compañía y de la Internet. Se llama red perimetral debido a que generalmente se encuentra en la orilla de la LAN, pero la DMZ se ha convertido en un término mucho más popular. Una DMZ permite a los usuarios fuera de la compañía acceder a servicios específicos ubicados en la DMZ. Sin embargo, cuando se implementa apropiadamente una DMZ, a esos usuarios se les bloquea el acceso a la LAN de la compañía. Los usuarios en la LAN a menudo se conectan también a la DMZ, pero lo pueden hacer sin tener que preocuparse por atacantes externos que accedan a su LAN privada. Un DMZ puede alojar un switch con servidores conectados que ofrezcan web, correo electrónico y otros servicios. Dos configuraciones comunes de las DMZs incluyen lo siguiente:
Una red perímetral (también conocida como una zona desmilitarizada o DMZ) es una red pequeña que se implementa separadamente de una LAN privada de la compañía y de la Internet. Se llama red perimetral debido a que generalmente se encuentra en la orilla de la LAN, pero la DMZ se ha convertido en un término mucho más popular. Una DMZ permite a los usuarios fuera de la compañía acceder a servicios específicos ubicados en la DMZ. Sin embargo, cuando se implementa apropiadamente una DMZ, a esos usuarios se les bloquea el acceso a la LAN de la compañía. Los usuarios en la LAN a menudo se conectan también a la DMZ, pero lo pueden hacer sin tener que preocuparse por atacantes externos que accedan a su LAN privada. Un DMZ puede alojar un switch con servidores conectados que ofrezcan web, correo electrónico y otros servicios. Dos configuraciones comunes de las DMZs incluyen lo siguiente:
- Configuración Back-to-back: involucra a una DMZ situada entre dos firewalls, los cuales pueden ser aplicaciones de caja negra o servidores de Aceleración y seguridad
- Configuración perimetral de 3 patas: en este escenario, la DMZ generalmente se adjunta a una conexión separada del firewall de la compañía. Por lo tanto, el firewall podría tener eres conexiones: una a la LAN de la compañía, otra a la DMZ y otra a Internet. En esta configuración, un atacante solo necesitaría atravesar un firewall para ganar acceso a la LAN. Aunque esto es una desventaja, las tecnologías como los sistemas de detección y prevención de intrusos de red pueden ayudar a aligerar la mayoría de las cuestiones de seguridad. Ademas, un solo firewall significa menos administración.
2.2) Topologías de red y estándares
A continuación centraremos nuestro estudio en una introducción a las topologías LAN básicas para la capa física.
A continuación centraremos nuestro estudio en una introducción a las topologías LAN básicas para la capa física.
2.2.1) Tipos de topologías de red
Las topologías usuales en LAN son bus, árbol, anillo y estrella. El bus es un caso especial de la topología en árbol, con un solo tronco y sin ramas; usaremos el término bus cuando las diferencias no sean importantes.
Topologías en Bus y Árbol:
Ambas topologías se caracterizan por el uso de un medio multipunto. En el caso de la topología en bus, todas las estaciones se encuentran directamente conectadas, a través de interfaces físicas apropiadas conocidas como tomas de conexión (taps), a un medio de transmisión lineal o bus. El funcionamiento full-duplex entre la estación y la toma de conexión permite la transmisión de datos a través del bus y la recepción de estos desde aquel. Una transmisión desde cualquier estación se propaga a través de del medio en ambos sentidos y es recibida por el resto de las estaciones. En cada extremo del bus existe un terminador que absorbe las señales, eliminándolas del bus.
La topología en árbol es una generalización de la topología en bus. El medio de transmisión es un cable ramificado sin bucles cerrados, que comienza en un punto conocido como raíz o cabecera. Uno o mas cables comienzan en el punto raíz, y cada uno de ellos puede presentar ramificaciones. Las ramas pueden disponer de ramas adicionales, dando lugar a esquemas mas complejos. De nuevo, la transmisión desde una estación se propaga a través del medio y puede alcanzar al resto de estaciones.
Existen dos problemas en esta disposición. En primer lugar, dado que la transmisión desde una estación se puede recibir en las demás estaciones, es necesario algún método para indicar a quien va dirigida a la transmisión. En segundo lugar, se precisa un mecanismo para regular la transmisión. Para ver la razón de este hecho hemos de comprender que si dos estaciones intentan transmitir simultáneamente, sus señales se superpondrán y serán erróneas; también se puede considerar la situación en que una estación decide transmitir continuamente durante un largo periodo de tiempo.
Para solucionar estos problemas las estaciones transmiten datos en bloques pequeños llamados tramas. Cada trama consta de una porción de los datos que una estación desea transmitir además de una cabecera de trama que contiene información de control. A cada estación en el bus se le asigna una dirección o identificador, unica, incluyéndose en la cabecera la dirección destino de la trama.



Las topologías usuales en LAN son bus, árbol, anillo y estrella. El bus es un caso especial de la topología en árbol, con un solo tronco y sin ramas; usaremos el término bus cuando las diferencias no sean importantes.
Topologías en Bus y Árbol:
Ambas topologías se caracterizan por el uso de un medio multipunto. En el caso de la topología en bus, todas las estaciones se encuentran directamente conectadas, a través de interfaces físicas apropiadas conocidas como tomas de conexión (taps), a un medio de transmisión lineal o bus. El funcionamiento full-duplex entre la estación y la toma de conexión permite la transmisión de datos a través del bus y la recepción de estos desde aquel. Una transmisión desde cualquier estación se propaga a través de del medio en ambos sentidos y es recibida por el resto de las estaciones. En cada extremo del bus existe un terminador que absorbe las señales, eliminándolas del bus.
La topología en árbol es una generalización de la topología en bus. El medio de transmisión es un cable ramificado sin bucles cerrados, que comienza en un punto conocido como raíz o cabecera. Uno o mas cables comienzan en el punto raíz, y cada uno de ellos puede presentar ramificaciones. Las ramas pueden disponer de ramas adicionales, dando lugar a esquemas mas complejos. De nuevo, la transmisión desde una estación se propaga a través del medio y puede alcanzar al resto de estaciones.
Existen dos problemas en esta disposición. En primer lugar, dado que la transmisión desde una estación se puede recibir en las demás estaciones, es necesario algún método para indicar a quien va dirigida a la transmisión. En segundo lugar, se precisa un mecanismo para regular la transmisión. Para ver la razón de este hecho hemos de comprender que si dos estaciones intentan transmitir simultáneamente, sus señales se superpondrán y serán erróneas; también se puede considerar la situación en que una estación decide transmitir continuamente durante un largo periodo de tiempo.
Para solucionar estos problemas las estaciones transmiten datos en bloques pequeños llamados tramas. Cada trama consta de una porción de los datos que una estación desea transmitir además de una cabecera de trama que contiene información de control. A cada estación en el bus se le asigna una dirección o identificador, unica, incluyéndose en la cabecera la dirección destino de la trama.

Topología en anillo
En la topología en anillo, la rede consta de un conjunto de repetidores unidos por enlaces punto a punto formando un bucle cerrado. El repetidor es un dispositivo relativamente simple, capaz de recibir datos a través del enlace y de transmitirlos, bit a bit, a través del otro enlace tan rápido como son recibidos.
Los enlaces unidireccionales; es decir, los datos se transmiten solo en un sentido, de modo que estos circulan alrededor del anillo en el sentido de las agujas del reloj o en el contrario.
Cada estación se conecta a la red mediante un repetidor, transmitiendo los datos hacia la red a través de él.
Como en el caso de las topologías en bus y en árbol, los datos se transmiten en tramas. Una trama que circula por el anillo pasa por las demás estaciones, de modo que las estaciones de destino reconocen su dirección y copia la trama, mientras estas las atraviesa, en una memorial local temporal. La trama continua circulando hasta que alcanza de nuevo la estación de origen, donde es eliminada del medio.
Dado que el anillo es compartido por varias estaciones, se necesita una técnica de control de acceso al medio para determinar cuando puede insertar tramas cada estación.

Topología en estrella
En las redes LAN con topología en estrella cada estación esta directamente conectada a un nodo central, generalmente a través de dos enlaces punto a punto, uno para transmisión y otro para recepción.
En general existen dos alternativas para el funcionamiento del nodo central. Una es el funcionamiento en un modo de difusión, en el que la transmisión de una trama por parte de una estación se retransmite sobre todos los enlaces de salida del nodo central.
En este caso, aunque la disposición física es una estrella, lógicamente funciona como un bus; una transmisión desde cualquier estación es recibida por el resto de las estaciones, y solo puede transmitir una estación en un instante de tiempo dado.

2.2.2) Estándares Ethernet
Ethemet es un grupo de tecnologías de redes que definen cómo la información es enviada y recibida entre adaptadores de red, hubs, switches y otros dispositivos. Es un estándar abierto, Ethernet es, de hecho, un estándar y tiene la compartición de redes más grande hoy en día, con Token Ring y FDDI que llenan algunas pequeñas lagunas donde no existe el Ethernet. El Ethernet está estandarizado por el Instituto de Ingenieros Eléctricos y Electrónicos (IEEE} como 802.3. Desarrollado origínalmente por Xerox, después fue defendido por DEC e In tel. HO)' en día, ciemos de compañías ofrecen productos Ethernet, incluyendo D-Link, Linksys, 3Com, HP, etcétera.
Las computadoras en redes Ethernet se comunican mediante el envío de frames Ethernet. Un frame es un grupo de bytes empaquetados por un adaptador de red para su transmisión a través de la red, estos frames se crean y residen en la Capa 2 del modelo OSI, el cual será cubierto más a profundidad en la próxima lección. Por defecto, todas las computadoras en redes Ethernet comparten un canal; sin embargo, las redes nuevas con switches más avanzados trascienden esca limitación.
El IEEE 802.3 define el Acceso Múltiple por Detección de Portadora con Detección de Colisiones o CSMAICD. Debido a que todas las computadoras en una LAN Ethernet comparten el mismo canal por defecto, CSMA/CD gobierna la manera en la cual las computadoras coexisten con colisiones limitadas. Los pasos básicos para CSMA/CD son !os siguientes:
Si se detecta una colisión en el Paso 4, se emplea otro proceso llamado "Procedimiento de colisión detectada" como sigue:
2.2.3) Modelos cliente/servidor
Ethemet es un grupo de tecnologías de redes que definen cómo la información es enviada y recibida entre adaptadores de red, hubs, switches y otros dispositivos. Es un estándar abierto, Ethernet es, de hecho, un estándar y tiene la compartición de redes más grande hoy en día, con Token Ring y FDDI que llenan algunas pequeñas lagunas donde no existe el Ethernet. El Ethernet está estandarizado por el Instituto de Ingenieros Eléctricos y Electrónicos (IEEE} como 802.3. Desarrollado origínalmente por Xerox, después fue defendido por DEC e In tel. HO)' en día, ciemos de compañías ofrecen productos Ethernet, incluyendo D-Link, Linksys, 3Com, HP, etcétera.
Las computadoras en redes Ethernet se comunican mediante el envío de frames Ethernet. Un frame es un grupo de bytes empaquetados por un adaptador de red para su transmisión a través de la red, estos frames se crean y residen en la Capa 2 del modelo OSI, el cual será cubierto más a profundidad en la próxima lección. Por defecto, todas las computadoras en redes Ethernet comparten un canal; sin embargo, las redes nuevas con switches más avanzados trascienden esca limitación.
El IEEE 802.3 define el Acceso Múltiple por Detección de Portadora con Detección de Colisiones o CSMAICD. Debido a que todas las computadoras en una LAN Ethernet comparten el mismo canal por defecto, CSMA/CD gobierna la manera en la cual las computadoras coexisten con colisiones limitadas. Los pasos básicos para CSMA/CD son !os siguientes:
- El adaptador de red construye y prepara un frame para transmisión a través de la red.
- El adaptador de red revisa sn el medio (por ejemplo, cable de par trenzado) es un idle. Si el medio no es un id le, el adaptador espera aproximadamente 10 microsegundos (10 ps). Este retardo es conocido como espacio interframe.
- El frame es transmitido a través de la red.
- El adaptador de red verifica si ocurren colisiones. Si tienen lugar, mueve el procedimiento de "Colisión Detectada".
- El adaptador de red restablece cualquier contador de retransmisión (si es necesario) y termina la transmisión del frame.
Si se detecta una colisión en el Paso 4, se emplea otro proceso llamado "Procedimiento de colisión detectada" como sigue:
- El adaptador de red continúa la transmisión hasta que se alcanza el tiempo mínimo de paquete (conocido como atasco de la señal o jam signa!). Esto asegura que codos los receptores han detectado la colisión.
- El adaptador de red incrementa el contador de retransmisión.
- El adaptador de red verifica si se alcanza el número máximo de intentos de transmisión. Si fue alcanzado, el adaptador de red aborta la transmisión.
- El adaptador de red calcula y espera un periodo aleatorio de backoff basado en el número de colisiones detectadas.
- Por último, el adaptador de red comienza el procedimiento original en el paso l.
2.2.3) Modelos cliente/servidor
El modelo cliente-servidor es una arquitectura que distribuye aplicaciones entre servidores tales como Windows Server 2008 )' computadoras cliente como máquinas con Windows 7 o Windows Vista. También distribuye la potencia necesaria de procesamiento. Esto es extremadamente común en las LANs hoy en día y con más aplicaciones que un usuario promedio utilizaría cuando se conecta a Internet. Por ejemplo, cuando un usuario llega a trabajar, este típicamente ingresa a la red. Hay posibilidades de que sea una red cliente/ servidor. El usuario puede estar utilizando Windows 7 como la computadora cliente para ingresar al dominio de Windows que es controlado por un Windows Server. Un ejemplo más simple sería un usuario casero que se conecta a Internet. Cuando esta persona quiere ir a un si tio web tal como Bing, abre el navegador web e introduce http://www.bing. com/ (o alguno de muchos accesos directos). El navegador web es la aplicación cliente. El servidor web de Bing es obviamente el ··servidor". Este sirve las páginas web llenas de código HTML. El navegador web de la computadora cliente decodifica el HTML y llena la pantalla del usuario con información de Internet.
Aquí algunos ejemplos de aplicaciones de los servidores:
- Servidor de archivos: un servidor de archivos almacena archivos para compartirlos con las computadoras. La conexión a un servidor de archivos puede hacerse por medio de la navegación, mapeando una unidad de red, conectándose en la línea de comandos o conectándose con un cliente FTP. Este último requeriría la instalación y configuración de un software especial de servidor FTP en el servidor de archivos. Por defecto, Windows Server 2008, Windows Server 2003 y Windows Server 2000 pueden ser servidores de archivos listos para su implementación.
- Servidor de impresión: un servidor de impresión controla impresoras que se pueden conectar directamente al servidor o (y más comúnmente) a la red. El servidor de red puede controlar el in icio y la interrupción de la impresión de documentos, así como también conceptos cales como el de cola, cola de impresión, puercos y muchos más. Por defecto, Windows Server 2008, Windows Server 2003 y Windows Server 2000 pueden ser servidores de impresión listos para su implementación.
- Servidor de Base de datos: un servidor de base de datos hospeda una base de datos relacional hecha de uno o más archivos. Las bases de daros SQL caen en esta categoría. Requieren de software especial, cal como Microsoft SQL Server. El acceso a las bases de datos (las cuales son de un solo archivo) no requieren necesariamente de un servidor de base de daros, son regularmente almacenados en un servidor de archivos regular.
- Controlador de red: un servidor de control, tal como el controlador de dominio de Microsoft, está a cargo de las cuentas de usuario, cuentas de computadoras, tiempo de red y el bienestar general del dominio encero de computadoras y usuarios. Windows Server 2008, Windows Server 2003 y Windows Server 2000 pueden ser controladores de dominio, pero deben ser promovidos a ese estado. Por defecto, un sistema operativo de Windows Server no es un controlador. Los sistemas operativos de control de red también son conocidos como sistemas operativos de red o NOS.
- Servidor de mensajería: esta categoría es enorme. Los servidores de mensajería incluyen no solo servidores de correo electrónico, también de fax, mensajería instantánea, colaboración y otros tipos de servidores de mensajería. Para que Windows Server controle el correo electrónico, tiene que cargar software especial conocido como Servidor Exchange añadiéndolo al sistema operativo.
- Servidor web: los servidores web son importantes para compartir daros y proporcionar información acerca de una compañía. Los Windows Servers pueden ser servidores web, pero los Servicios de Información de Internet (IIS) se deben instalar y configurar para que funcionen apropiadamente.
- Servidor CTI: CTI es una abreviatura para Integración de Telefonía y Computadoras. Esto es cuando el sistema de la compañía de teléfono se encuentra con el sistema computacional. Aquí, PBXs especiales que controlaban los teléfonos como una entidad separada se pueden controlar con servidores con software poderoso.
.
2.2.4) Modelo red de pares
Las redes de pare.{ significan primordialmente que cada computadora es n-arada como igual. Esto significa que cada computadora tiene la habilidad equitativa para servir y acceder a la información, justo como cualquier otra computadora en la red. Antes que los servidores se hicieran populares en redes computacionales basadas en PCs, cada computadora tenía la habilidad de almacenar información. Incluso después de que el modelo cliente/servidor fuera tan popular, las redes de pares han seguido conservando su lugar, en especial en redes pequeñas con lO computadoras o menos. Hoy en día, las computadoras pares pueden se servir información, la única diferencia es que solo pueden servirla a un pequeño número de computadoras al mismo tiempo.
Las redes de Pares han tomado un segundo sig nificado a partir de la última década. Ahora se refieren a redes de archivos compartidos y en esre caso es conocido como P2P. Ejemplos de redes de compartición de archivos incluyen al Napster, Gnutella y G2, pero otras tecnologías también cuentan con las ventajas de la compartición de archivos P2P, cales como Skype, VoiP y la computación en la nube. En una red P2P, los hose son añadidos de manera ad hoc. Esros pueden dejar la red en cualquier momento sin impactar la descarga de archivos. ~[uchos pares pueden contribuir a la disponibilidad de archivos y recursos.
Una persona que descarga información de una red P2P puede obtener unos pocos bits de información de muchas comput adoras d iferentes, después, la computadora que está descargando puede también compartir el archivo. La mayoría de las redes de compartición pares a pares uri !izan software especial para descargar archivos, raJes como BirTorrenc, que es un protocolo pero también un programa.
CAPITULO 3. REDES DE ÁREA AMPLIA
3.1) Comprender el enrutamiento
El enrutamiento es el proceso de mover datos a través de redes o interconexiones de redes entre hosts o entre routers. la información es transmitida de acuerdo a las redes lP y direcciones lP individuales de los host en cuestión. Un router se encarga de mantener tablas de información acerca de otros routers en la red o interconexión de redes. También utiliza algunos protocolos TCP/IP diferentes para transferir los daros y para descubrir otros routers. El enrutamienco IP es el cipo más común de enrutamiento, justo como el TCP/IP es la.suite de protocolos más común. El enrutamiento IP ocurre en la capa de red del modelo OSI.
3.1.1) Tipos de enrutamiento (dinámico y estático)
Una vez comprendido el término enrutamiento, podemos decir, que esta herramienta se divide en dos tipos: el enrutamiento dinámico y el enrutamiento estático.
El enrutamiento Estático se refiere a la configuración manual de un router. Por ejemplo, cuando una entrada de enrutamiento es introducida manualmente en la rabia de enrutamiento con el comando roure add, se conoce como enrutamiento estático. Este es un tipo básico de router que no cambia con la red y no es tolerante a fallas. Las rutas introducidas estáticamente no "saben" lo que pasa en la red, no pueden sentir nuevos routers o el estado modificado de una router en particular. Por consiguiente, hay una gran cantidad de mantenimiento requerido con el router estático. Debido a esto, la mejor solución es utilizar el enrutamiento dinámico.
El Enrutamiento Dinámico es implementado por tablas de enrutamiento configuradas dinámicamente. Esto se hace con protocolos de enrutamiento dinámico, tales como RIP y OSPF. Los dos son parte de la suite de protocolos de TCP/IP y ambos trabajan en la capa 3 del modelo OSI. Es importante ser capaz de distinguir entre protocolos enrutables y protocolos de enturamiento. NetBEUl es un ejemplo de un protocolo no enrutable. Un ejemplo de un protocolo enrutable sería el TCP/IP o RIP. Hablaremos más acerca de RIP y algunos otros protocolos de enrutamienro:
Cuando se trata de redes grandes e Internet, las tablas de enrutamiento pueden hacerse muy pesadas. Un router requiere de mucha velocidad, memoria eficiente para manejar esas tablas. Los routers antiguos simplemente no pueden hacer frente al número de entradas y algunos protocolos como BGP podrían no trabajar apropiadamente en esos routers. Debido a que Internet está creciendo rápidamente, los ISPs utilizan colectivamente el CIDR en un intento de limitar el tamaño de las rabias de enrutamiento. La congestión de red y el balanceo de carga son también un problema. Dependiendo del caso, podría necesitar utilizar routers más nuevos con más memoria y conexiones de red más rápidas y debería considerar cuidadosamente cuáles protocolos emplear. Generalmente, una compañía de pequeña a mediana puede arreglárselas con RIP.
Una vez comprendido el término enrutamiento, podemos decir, que esta herramienta se divide en dos tipos: el enrutamiento dinámico y el enrutamiento estático.
El enrutamiento Estático se refiere a la configuración manual de un router. Por ejemplo, cuando una entrada de enrutamiento es introducida manualmente en la rabia de enrutamiento con el comando roure add, se conoce como enrutamiento estático. Este es un tipo básico de router que no cambia con la red y no es tolerante a fallas. Las rutas introducidas estáticamente no "saben" lo que pasa en la red, no pueden sentir nuevos routers o el estado modificado de una router en particular. Por consiguiente, hay una gran cantidad de mantenimiento requerido con el router estático. Debido a esto, la mejor solución es utilizar el enrutamiento dinámico.
El Enrutamiento Dinámico es implementado por tablas de enrutamiento configuradas dinámicamente. Esto se hace con protocolos de enrutamiento dinámico, tales como RIP y OSPF. Los dos son parte de la suite de protocolos de TCP/IP y ambos trabajan en la capa 3 del modelo OSI. Es importante ser capaz de distinguir entre protocolos enrutables y protocolos de enturamiento. NetBEUl es un ejemplo de un protocolo no enrutable. Un ejemplo de un protocolo enrutable sería el TCP/IP o RIP. Hablaremos más acerca de RIP y algunos otros protocolos de enrutamienro:
- Protocolo de bzformación de Enrutamiento (RIP): un prorocolo dinámico que utiliza algoritmos de enrutamiento de vector-distancia para descifrar a cuál ruta enviar los paquetes de datos. En redes de conmutación de paquetes, un protocolo de enrutamiento de vector-distancia utiliza el algoritmo Bellman-Ford para calcular dónde y cómo los daros serán transmitidos. El protocolo calcula la dirección o interfaz a la que los paquetes deberían ser reenviados, así como también la distancia desde el destino. RIPv 1 y RIPv2 son comunes entre las redes de hoy día.
- Primero la Ruta más Corta Abierta (OSPF): un protocolo de estado de enlace que monirorea la red por routers que han cambiado su estado de enlace, esto significa que han sido apagados, prendidos o reiniciados. Este es tal vez el protocolo de puerta de enlace interior más utilizado en redes grandes. Los protocolos de puerta de enlace interior se utilizan para determinar conexiones entre sistemas autónomos.
- Protocolo de Enrutamíento de Puerta de Enlace Interior (IGRP): un protocolo propietario utilizado en redes grandes para superar las limitaciones de RIP.
- Protocolo de Pueta de Enlace de Frontera (BGP): un protocolo de enrutamiento de núcleo que basa las decisiones de enrutamiento en las rucas y reglas en la red.
Cuando se trata de redes grandes e Internet, las tablas de enrutamiento pueden hacerse muy pesadas. Un router requiere de mucha velocidad, memoria eficiente para manejar esas tablas. Los routers antiguos simplemente no pueden hacer frente al número de entradas y algunos protocolos como BGP podrían no trabajar apropiadamente en esos routers. Debido a que Internet está creciendo rápidamente, los ISPs utilizan colectivamente el CIDR en un intento de limitar el tamaño de las rabias de enrutamiento. La congestión de red y el balanceo de carga son también un problema. Dependiendo del caso, podría necesitar utilizar routers más nuevos con más memoria y conexiones de red más rápidas y debería considerar cuidadosamente cuáles protocolos emplear. Generalmente, una compañía de pequeña a mediana puede arreglárselas con RIP.
3.2) Tecnologías y conexiones comunes de WAN
Las redes de área amplia conectan múltiples redes de área local juntas. Si una organización desea tener una conexión de área amplia a otra oficina, necesita decid irse por un servicio de red y la velocidad a la cual desea que se conecte. El presupuesto juega un rol significante en este cipo de decisiones .
3.2.1) Conmutación de paquetes
3.2.1) Conmutación de paquetes
La conmutación de paquetes se refiere a la forma en la cual los paquetes de datos se mueven sobre redes de área amplia conmutadas. Los tipos de servicios de conmutación de paquetes incluyen el X.25 y el Frame Relay.
Los servicios de Conmutación de Paquetes incluyen el X.25 y el Frame Relay. Antes de la conmutación de paquetes, había conexiones directas de dial-up y otras formas arcaicas de comunicación. Algunos de los problemas asociados con estos incluyen lo siguiente:

3.2.2) X.25
Los servicios de Conmutación de Paquetes incluyen el X.25 y el Frame Relay. Antes de la conmutación de paquetes, había conexiones directas de dial-up y otras formas arcaicas de comunicación. Algunos de los problemas asociados con estos incluyen lo siguiente:
- Hasta principios de 1970, la transferencia de datos fue análoga con mucha estática
- y ruido. También fue principalmente asíncrona y conducida por módems de dialup.
- La transferencia de información podría ser cuando mucho un 40% de overhead
- y solo un 60% de información real. El Overhead incluía tolerancia al ruido,
- comprobación de errores, Aagging, bits de parada/in icio, paridad, etcétera.
- Las transferencias de datos más gl"'andes podrían ser desconectadas por muchas
- razones, incluyendo:
- Una conexión pobre
- Degradación de red
- Pérdida de circuitos
- Después de una desconexión, el mensaje encero (archivo) tendría que ser reenviado,
- usualmente después de que la persona marcara de nuevo.
A continuación analizaremos dos técnicas de conmutación de paquetes: los datagramas y los circuitos vitales.

En la técnica de datagrama cada paquete se trata de forma independiente, sin referencia alguna a los paquetes anteriores. Veamos las implicaciones de este enfoque. Supongamos que la estación A de la imagen anterior tiene que enviar a E un mensaje de 3 paquetes. Transmite los paquetes 1, 2 y 3 al nodo 4, conteniendo cada uno de ellos la dirección del destino, E en este caso. El nodo 4 debe tomar una decisión de encaminamiento para cada paquete. El paquete 1 se recibe con destino a E, con lo que el nodo 4 podría enviar este paquete hacia el nodo 5 o hacia el noto 7 como siguiente paso en la ruta. En este caso el nodo 4 determina que su cola de paquetes hacia el nodo 5 es menor que la del nodo 7, de manera que pone en cola el paquete hacia el nodo 5. Igual para el paquete 2, pero en el caso del paquete 3, el nodo 4 observa que su cola hacia el nodo 7 es ahora mas corta y, por tanto, envía el paquete 3 hacia este nodo. Así pues, aunque todos los paquetes tienen el mismo destino no todos siguen la misma ruta. En consecuencia, puede suceder que el paquete 3 se adelante al paquete 2, e incluso al 1, en el nodo 6. De esta forma, es posible que los paquetes se reciban en E en orden distinto al que lo enviaron, siendo tarea de esta estación su reordenamiento.
En la técnica de circuito vital se establece una ruta previa al envio de los paquetes. Por ejemplo, supongamos que A tiene uno o mas mensajes que enviar a E. Primero envía un paquete especial de control, llamado Petición de llamada, a 4 solicitando una conexión lógica a E. El nodo 4 decide encaminar la solicitud y todos los paquetes siguientes hacia 5, quien a su vez decide dirigirlos hacia 6, el cual envía finalmente el paquete Petición de Llamada a E. Si esta estación acepta la conexión, envía un paquete Llamada Aceptada a 6. Este paquete se envía hacia A a través de los nodos 5 y 4. Las estaciones A y E pueden ya intercambiar datos sobre la ruta establecida. Dado que el camino es fijo mientras dura la conexión lógica, este es similar a un circuito en redes de conmutación de circuitos y se le llama circuito vital. Eventualmente, una de las estaciones finaliza la conexión con un paquete Petición de Liberación.
Una ventaja del empleo de la técnica de datagrama es que existe la fase de establecimiento de llamada. De esta forma, si una estación desea enviar solo uno o pocos paquetes el envio datagrama resultará mas rapido.
El protocolo de comunicaciones X .25 fue una de las primeras implementaciones de conmutación de paquetes y aún está en uso hoy en día.
La conmutación de paquetes fue creada originalmente para dividir mensajes grandes en segmentos más pequeños y más manejables para la transmisión sobre una WAN. Básicamente, la computadora transmisor" envía su mensa je sobre la LAN al componente de hardware/software conocido como router. El router entonces divide el archivo en piezas más manejables (conocidas como paquetes). Cada paquete obtiene su porción del mensaje original, también un número de segmentación e información de dirección. Cada paquete entonces es transmitido sobre el enlace físico al sistema de conmutación (releo), el cual escoge un cable para la transmisión desde el encabezado de la información del paquete. Esto establece una conexión virtual o circuito virtual. Luego, los paquetes son reensamblados en el router receptor.
Aquí están los pasos de la conmutación de paquetes X.25:

3.2.3) Frame Relay
La conmutación de paquetes fue creada originalmente para dividir mensajes grandes en segmentos más pequeños y más manejables para la transmisión sobre una WAN. Básicamente, la computadora transmisor" envía su mensa je sobre la LAN al componente de hardware/software conocido como router. El router entonces divide el archivo en piezas más manejables (conocidas como paquetes). Cada paquete obtiene su porción del mensaje original, también un número de segmentación e información de dirección. Cada paquete entonces es transmitido sobre el enlace físico al sistema de conmutación (releo), el cual escoge un cable para la transmisión desde el encabezado de la información del paquete. Esto establece una conexión virtual o circuito virtual. Luego, los paquetes son reensamblados en el router receptor.
Aquí están los pasos de la conmutación de paquetes X.25:
- Una computadora envía daros al router de forma normal a través del modelo OSI sobre la LAN.
- La información es reunida por el router (como el mensaje), pero el router luego desensambla el lote entero en paquetes revueltos. Por lo tanto, el router se conoce como un PAD (Ensamblador/desensamblador de paquetes).
- El PAD envía los paquetes a un CSVIDSU (Dispositivo de Intercambio de Datos Digital de Alta Velocidad) como información serial. El CSU/DSU es el equivalente del módem para la LAN encera. Se conoce como un DCE o Equipo de comunicación de daros. En este caso, el PAD (o router) es conocido con el DTE o Equipo terminal de daros.
- El CSU/DSU envía los paquetes al punto de demarcación (demarc) en la oficina o compañía. Muy a menudo, el CSU/DSU es el demarc, por otra parre conocido como el punto donde su responsabilidad como administrador termina y la responsabilidad del proveedor de telecomunicaciones o comunicación de datos empieza. El demarc podría también ser un dispositivo de interfaz de red o un simple enchufe de red.
- Esto entonces conduce a la oficina central de la compañía de teléfono que está soportando el servicio de X.25.
- La oficina central (C. O.) elige un cable y transmite a la oficina de conmutación, la cual entonces continúa a las líneas de electricidad y así sucesivamence. Cuando la oficina central hace eso, se le conoce como circuito virtual.
- La información termina en la oficina central receptora, la cual envía la información sobre otro circuito virtual para corregir la línea que conduce a la otra oficina.
- Esta luego conduce a su punto de demarcación (demarc), a su CSU/DSU y luego a su router receptor (PAD).
- El PAD receptor entonces buferea la información, la revisa, la recuenta y pone el paquete en secuencia.
- Entonces lo envía sobre la LAN en el modo regular del modelo OSI a la computadora receptora correcta.

PASOS DE CONMUTACIÓN DE PAQUETES X.25 (PUNTO 1 a PUNTO 4)
La "nube" es el área de la infraestructura de la compañía de teléfono que está entre el punto de demarcación de su oficina y la oficina receptora. Todas las oficinas centrales, oficinas de conmutación, posees de teléfono y líneas son paree de la nube.
Las características de X.25 incluyen lo siguiente:
- Usualmente es digita
- Usualmente es sincrónico. Esto significa que la conexión es controlada por un circuito de reloj así que ambos dispositivos X.25 saben cuándo transmitir daros sin tener colisiones.
- Involucra un máximo de línea de 56K o 64K.
- También es conocido como conmutación de paquetes de longitud variable.
- Un PAD decide cuál circuito de información va a tomar como parte del concepto del circuito virtual.
- Los paquetes usualmente tienen 128 bytes de datos reales, pero algunas configuraciones van !hasta 512 bytes.
Ahora, vamos a cubrir los componentes de X.25. Básicamente, un paquete X.25 está hecho de un overhead y datos. El Overhead es el encabezado del paquete e información de trailer combinada. Por lo ramo, si alguien pregunta cuáles son las dos partes del paquete, usted respondería el overhead y los daros. Sin embargo, si alguien pregunta acerca de las tres partes de un paquete, debería decir el encabezado, los datos y el trailer. El overhead no es información real. Es información enviada como impulsos eléctricos adicionales, pero no es paree del mensaje original. La información de encabezado incluye cosas como el flag del paquete, HDLC (Conrrol de enlace de daros de aleo nivel), la información desde, información con detección de errores, ere. El trailer incluye cosas como la revisión de redundancia cíclica (CRC), el cual revisa el tamaño exacto del paquete en la computadora destino.
3.2.3) Frame Relay
El Frame Re/ay es el avance de la conmutación de paquetes X.25. Es una forma más nueva de conmutación de paquetes diseñada para conexiones más rápidas. Con este sistema, los paquetes ahora son definidos como marcos (frames). Como X.25, Frame Re la y utiliza enlaces de transmisión solo cuando se necesitan. También utiliza un circuito virtual, pero uno que es más avanzado. Frame Relay creó la "red virtual" que reside en la nube. Muchos clientes utilizan el mismo grupo de cables o circuitos (conocidos como circuitos compartidos). Como las conexiones privadas (Tl ,etc.), el Frame Relay transmite muy rápido. Este podría emplear una conexión Tl, pero de una manera privada. El Tl es un transportador, una conexión física que tiene una casa de transferencia de datos de 1.544 Mbps. A diferencia de X.25, se necesita mucho menos procesamiento en Frame Relay. Dentro de los switches o PSEs, la mayoría del overhead es eliminado. La red solo busca la dirección en el marco (frame). A diferencia de las conexiones privadas TI dedicadas, Frame Relay utiliza una línea pública arrendada.
El Frame Relay fue creado para tomar ventaja de la infraestructura digital de alto desempeño y bajos errores ahora en su lugar y paro mejorar el servicio de transmisiones sincrónicas. Es una red mucho más simple comparada con una red de línea privada.
Las desventajas de Frame Relay son la disminución de velocidad y privacidad comparada con una interconexión de redes Tl privada. Las ventajas incluyen el bajo costo y la necesidad de menos equipo.
Ahora, discutamos algunas de las características de Frame Relay. Con Frame Relay se pueden ejecutar múltiples sesiones simultáneamente en el mismo enlace. Estas conexiones a la nube son conocidas como enlaces lógicos permanentes o circuitos virtuales permanentes (PVCs), no los confunda con la envoltura plástica en el cable de categoría 5. El PVC enlaza los sitios en la nube, esto lo lleva a cabo, una vez más, el PSE (intercambio de conmutación de paquetes). Es como una red T1 Privada, pero aquí el ancho de banda es compartido a cada PVC con otros clientes también. Por lo canto, se necesitan pocos roucers, CSU/DSUs y multiplexores por sitio. Un PVC siempre está disponible para que el tiempo de llamada del X.25 se elimine. La afinación constante que se necesita normalmente en las redes de malla T1 tampoco es necesaria.
Como cualquier comunicación, debe comprar el servicio Frame Relay de un proveedor de servicio de Internet o telecomunicaciones. Estos servicios son conocidos como líneas arrendadas. También con Frame Relay debe comprometerse a cierta cantidad de información sobre el tiempo. Es ce es un CIR (casa de información comprometida). El CIR es asignado a cada PVC que sirve la cuenca de la organización.

3.2.4) Portadoras T
El Frame Relay fue creado para tomar ventaja de la infraestructura digital de alto desempeño y bajos errores ahora en su lugar y paro mejorar el servicio de transmisiones sincrónicas. Es una red mucho más simple comparada con una red de línea privada.
Las desventajas de Frame Relay son la disminución de velocidad y privacidad comparada con una interconexión de redes Tl privada. Las ventajas incluyen el bajo costo y la necesidad de menos equipo.
Ahora, discutamos algunas de las características de Frame Relay. Con Frame Relay se pueden ejecutar múltiples sesiones simultáneamente en el mismo enlace. Estas conexiones a la nube son conocidas como enlaces lógicos permanentes o circuitos virtuales permanentes (PVCs), no los confunda con la envoltura plástica en el cable de categoría 5. El PVC enlaza los sitios en la nube, esto lo lleva a cabo, una vez más, el PSE (intercambio de conmutación de paquetes). Es como una red T1 Privada, pero aquí el ancho de banda es compartido a cada PVC con otros clientes también. Por lo canto, se necesitan pocos roucers, CSU/DSUs y multiplexores por sitio. Un PVC siempre está disponible para que el tiempo de llamada del X.25 se elimine. La afinación constante que se necesita normalmente en las redes de malla T1 tampoco es necesaria.
Como cualquier comunicación, debe comprar el servicio Frame Relay de un proveedor de servicio de Internet o telecomunicaciones. Estos servicios son conocidos como líneas arrendadas. También con Frame Relay debe comprometerse a cierta cantidad de información sobre el tiempo. Es ce es un CIR (casa de información comprometida). El CIR es asignado a cada PVC que sirve la cuenca de la organización.
3.2.4) Portadoras T
Una Portadora-T o sistema de acarreo de telecomunicaciones es un sistema de cableado de interfaces diseñado para llevar datos a aleas velocidades. El más común de estos es el TI. La casa de transferencia de daros básica del sistema de portadora-Tes de 64 Kbps, el cual es conocido como DSO, este es el esquema de señalización digital. Correspondientemente, DSJ sería el esquema de señalización digital para la Portadora-Tl. Los dos sistemas de Portadora-T más comunes son los siguientes:
Tl y T3 son los nombres utilizados en los Estados Unidos. En Japón son conocidos como J1/J3 y en Europa están denotados como El/E3.
Diferentes servicios se pueden ejecutar en un sistema de Portadora-T. Pueden ser Frame Relay, ISDN u otros servicios. De otra manera, una Portadora-T puede ser una conexión privada dedicada entre las LANs para formar una WAN completamente privada.

- T1: un circuito transportador que se pone a disposición de una compañía. Se puede ejecutar como un enlace dedicado de alea velocidad o tener otras tecnologías compartidas ejecutándose en la parte superior de él, como Frame Relay e ISDN. Está considerado a l. 544 Mbps, pero solo l. 5 36 Mbps son para datos. Los restantes 8 Kbps son para el crimming/overbead del Tl. Los 1. 5 36 Mbps están divididos en 24 canales iguales de 64 Kbps y pueden ser utilizados con un multiplexor.
- T3: siglas de for trunk Carrier 3. Este es el equivalente a 28 Tls. Está considerado a 44.736 Mbps, utiliza 672 64 Kbps canales B. T3 vendrá a la compañía con 224 cables aproximadamente y debe ser presionado en un DSX o dispositivo parecido.
Tl y T3 son los nombres utilizados en los Estados Unidos. En Japón son conocidos como J1/J3 y en Europa están denotados como El/E3.
Diferentes servicios se pueden ejecutar en un sistema de Portadora-T. Pueden ser Frame Relay, ISDN u otros servicios. De otra manera, una Portadora-T puede ser una conexión privada dedicada entre las LANs para formar una WAN completamente privada.

CONEXIÓN Y SERVICIO T1
3.2.5) Otras tecnologías WAN y conectividad a Internet
Aunque Frame Relay y las Portadoras-T. son tecnologías de conectividad WAN comunes, también hay otros tipos de conexiones por las que una compañía podría optar, cales como ISDN, ATM, SONET, cable o DSL.
La Red Digital de Servicios Integrados (ISDN): es una tecnología digital desarrollada para combatir las limitaciones de PSTN. Los usuarios que tienen ISDN pueden enviar datos, fax o hablar por teléfono, todos simultáneamente en una línea. ISDN puede ser dividido en dos categorías:
Muchas compañías utilizan esto para videoconferencias o como una conexión de acceso a Internet secundaria. La videoconferencia requiere de una línea PRI, debido a que BRl no tiene suficiente ancho de banda. Los conmutadores de daros utilizarán conexiones BRI si no se dispone de DSL o Internet por cable.
Modo de transferencia Asíncrona (ATM) es una tecnología de conmutación basada en celdas como opuesto a la tecnología de conmutación de paquetes. Las celdas involucradas en ATM son de longitud fija, normalmente de 53 octetos (o 53 8-bit bytes). ATM es utilizado como un backbone para ISDN.
OCx es el estándar para el rendimiento de datos en conexiones SONET. SONET es una abreviatura de Red Óptica Sincrónica. Transfiere múltiples corrientes de bits digitales sobre fibras ópticas. Las tasas presentadas en la siguiente lista son conocidas como tasas de señal de transporte sincrónicas:
Línea de Suscripción Digital (DSL): es una familia de tecnologías que proporcionan transmisiones de datos sobre redes telefónicas locales. Las variantes de DSL incluyen lo siguiente:
Cable de banda ancha (Broadba1ld): es ucilizado para Internet por cable y TV por cable. Opera a velocidades más altas que d DSL y puede subir a un promedio de 5 a 7 Mbps, aunque la conexión serial tiene la habilidad teórica de ir hasta 18 Mbps. DSLreporcs.com comúnmente muestra personas conectándose con cable a 10 Mbps.
POTS/PSTN significa Sistema telefónico antiguo y sencillo/red telefónica conmutada pública. Esta es la que utilizamos ahora para las líneas telefónicas "regulares", ha sido así desde la década del 40. POTS/PSTN es ahora digital en la oficina de conmutación y algunas oficinas centrales, pero hay líneas análogas en los hogares de las personas.
La Red Digital de Servicios Integrados (ISDN): es una tecnología digital desarrollada para combatir las limitaciones de PSTN. Los usuarios que tienen ISDN pueden enviar datos, fax o hablar por teléfono, todos simultáneamente en una línea. ISDN puede ser dividido en dos categorías:
- Tasa Básica de ISDN (BRI): este es 128 Kbps con dos canales iguales B a 64 Kbps cada uno para datos y un canal D de 16 kbps para la sincronización. Generalmente, los dispositivos que se conectan a las líneas BRI pueden manejar ocho conexiones simultáneamente a Internet.
- Tasa Principal de ISDN (PRI): este es 1.536 Mbps y se ejecuta en un circuito T-1. PRI tiene 23 canales iguales de 64 Kbps para daros, junco con un canal D a 64 Kbps para la sincronización.
Muchas compañías utilizan esto para videoconferencias o como una conexión de acceso a Internet secundaria. La videoconferencia requiere de una línea PRI, debido a que BRl no tiene suficiente ancho de banda. Los conmutadores de daros utilizarán conexiones BRI si no se dispone de DSL o Internet por cable.
Modo de transferencia Asíncrona (ATM) es una tecnología de conmutación basada en celdas como opuesto a la tecnología de conmutación de paquetes. Las celdas involucradas en ATM son de longitud fija, normalmente de 53 octetos (o 53 8-bit bytes). ATM es utilizado como un backbone para ISDN.
OCx es el estándar para el rendimiento de datos en conexiones SONET. SONET es una abreviatura de Red Óptica Sincrónica. Transfiere múltiples corrientes de bits digitales sobre fibras ópticas. Las tasas presentadas en la siguiente lista son conocidas como tasas de señal de transporte sincrónicas:
Nivel OC Tasa de Transmisión
OC-1 51.84 Mbps
OC-3 155.52 Mbps
OC-12 622.02 Mbps
OC-24 1.244 Gbps
OC-48 2.488 Gbps
OC-192 9.953 Gbps
lnterfáz de datos distribuidos por fibra (FDDI): es un estándar para la transmisión de datos en cables de fibra óptica a una tasa de alrededor de 100 Mbps. Utiliza la topología en anillo.
- xDSL es el estándar para las. distincas líneas de suscripción digital.
- ADSL (líneas de suscripción digital asimétricas) se pueden ejecutar en su línea telefónica casera de forma que puede hablar por teléfono y acceder a Internet al mismo tiempo. Sin embargo, algunas versiones lo limitan a 28,800 bps de velocidad de subida y la velocidad de descarga es variable, con un máximo de 7 Mbps. Usualmente no es tan rápido como el Internet por cable.
- SDSL (línea de suscripción digital simétrica): es instalada (usual m eme a compañías) como una línea separada y es más cara. Las tasas de transferencia de daros de SDSL pueden comprase para 384 K, 768 K, 1.1 M y 1.5 M. La velocidad de subida y descarga son las mismas o simétricas.
Cable de banda ancha (Broadba1ld): es ucilizado para Internet por cable y TV por cable. Opera a velocidades más altas que d DSL y puede subir a un promedio de 5 a 7 Mbps, aunque la conexión serial tiene la habilidad teórica de ir hasta 18 Mbps. DSLreporcs.com comúnmente muestra personas conectándose con cable a 10 Mbps.
POTS/PSTN significa Sistema telefónico antiguo y sencillo/red telefónica conmutada pública. Esta es la que utilizamos ahora para las líneas telefónicas "regulares", ha sido así desde la década del 40. POTS/PSTN es ahora digital en la oficina de conmutación y algunas oficinas centrales, pero hay líneas análogas en los hogares de las personas.
CAPITULO 4. REDES DE TIPO INTERRED O INTERNET
4.1) ¿Que es Internet?
En lugar de proporcionar una sentencia simple, intentaremos dar una aproximación descriptiva. Existen un par de formas de hacer esto. Una forma en describir los componentes hardware y software básico que lo forman. Otra forma es describir Internet en términos de infraestructura de red que proporciona servicios para aplicaciones distribuidas.
Internet publico es una red de computadores mundial, esto es, una red que conecta millones de dispositivos de cómputo a través del mundo. La mayoría de estos dispositivos de computo son los PC tradicionales de sobremesa, las estaciones de de trabajo basadas en UNIX , y los llamados servidores, que almacenan y transmiten información del tipo de paginas de web y mensajes de correo electrónico. Cada vez mas, dispositivos terminales no tradicionales de Internet, como asistentes digitales (PDA), televisores, computadores portátiles y tostadoras se están conectando a internet. En la jerga de Internet todos estos dispositivos se llaman host y sistemas terminales. Los sistemas terminales se conectan mediante enlace de comunicación. Distintos enlaces pueden transmitir datos a diferente velocidad, La tasa de transmisión de enlace se llama a menudo ancho de banda, y se mide normalmente en bits/segundo.
Los sistemas terminales normalmente no se enlazan directamente entre si mediante enlaces sencillos de comunicación, sino que se conectan unos a otros a través de dispositivos de conmutación llamados routers. Un router toma un trozo de información de los enlaces de comunicación de entrada. En la jerga de redes, al trozo de información se les conoce como paquete.
Los sistemas terminales, los routers, y otros elementos de internet, ejecutan protocolos que controlan el envio y la recepción de información de internet. TPC (protocolo de control de transmisión) e IP (protocolo Internet) son los dos protocolos mas importantes de Internet, los que estudiaremos con mayor profundidad en el punto 4.2.
El internet público es la red a la que normalmente uno se refiere a la Internet. Existen también muchas redes privadas, como redes corporativas o de gobierno, cuyos host no pueden intercambiar mensajes con host externos a la red privada (a menos que los mensajes pasen a través de los llamados contrafuegos, que restringen el flujo de mensajes a y desde la red). Estas redes privadas se conocen frecuentemente como intranets, ya que utilizan los mismos tipos de host, routers, enlaces y protocolos que Internet público.
A nivel técnico y de desarrollo, Internet ha sido posible gracias a la creación prueba e implementación de estándares de Internet. Estos estándares son desarrollados por el Internet Engineering Task Force (iETF). Los documentos estándares de IEFT se llaman RFC (solicitudes de comentarios). Las RFC tienden a ser completamente técnicas y detalladas. Definen protocolos como TCP, IP, HTTP (para la web) y SMTP (para estándares abiertos de correo electrónico. Hay mas de 3000 solicitudes de RFC diferentes.
4.2) El extremo de la red
En las secciones previas nos hemos introducido a lo que es el Internet. Ahora vamos a profundizar un poco mas en los componentes de una red (y de Internet en particular).En esta sección nos enfocaremos en el extremo de la red, y nos fijaremos los componentes con los que estamos mas familiarizados.
En las secciones previas nos hemos introducido a lo que es el Internet. Ahora vamos a profundizar un poco mas en los componentes de una red (y de Internet en particular).En esta sección nos enfocaremos en el extremo de la red, y nos fijaremos los componentes con los que estamos mas familiarizados.
4.2.1) Sistemas terminales, clientes y servidores
En la jerga de redes, a los computadores conectados a Internet se les denomina a menudo sistemas terminales. Reciben este nombre porque están situados en el extremo de Internet. Entre los sistemas terminales de Internet se incluyen muchos tipos diferentes de computadoras. Los usuarios finales interactuan directamente con algunos de estos computadores, como lo son computadores de sobremesa (personales tipo PC, Mac o estaciones de trabajo basadas en UNIX de sobremesa) y los computadores móviles (computadores portátiles y agendas portátiles(PDA)con conexiones a Internet sin cables). Dentro de los sistemas terminales de Internet también se incluyen computadores con los que los usuarios finales no interaccionan directamente, como los servidores web y de correo electrónico. Además, un número creciente de dispositivos alternativos, como clientes ligeros y aparatos domésticos, TV Web y set top boxes o cámaras digitales, están siendo conectados a Internet como sistemas finales. Los sistemas terminales son llamados también anfitriones (host), porque alojan programas de ejecución, como navegadores web, lectores de correo electrónico, o servidores de correo.
Los anfitriones se dividen, a veces, en dos categorías: clientes y servidores. Informalmente los clientes suelen ser computadores personales de mesa (PC) o portátiles, PDA y otros, mientras que los servidores suelen ser maquinas mas potentes que alojan servidores, como servidores web o de correo. En el contexto de software de redes, hay otra definición de cliente y servidor. Un programa cliente es un programa que se ejecuta en un sistema terminal que solicita y recibe un servicio de un programa servidor que se ejecuta en otro sistema terminal. Este modelo cliente /servidor es indudablemente la estructura mas predominante en las aplicaciones Internet. La Web, el correo electrónico, la transferencia de archivos, la entrada remota, los grupos de noticias y muchas otras aplicaciones populares, adoptan el modelo cliente/servidor. Puesto que un programa cliente normalmente se ejecuta en un computador y el servidor en otro, las aplicaciones internet cliente/servidor son por definición, aplicaciones distributivas.
En la jerga de redes, a los computadores conectados a Internet se les denomina a menudo sistemas terminales. Reciben este nombre porque están situados en el extremo de Internet. Entre los sistemas terminales de Internet se incluyen muchos tipos diferentes de computadoras. Los usuarios finales interactuan directamente con algunos de estos computadores, como lo son computadores de sobremesa (personales tipo PC, Mac o estaciones de trabajo basadas en UNIX de sobremesa) y los computadores móviles (computadores portátiles y agendas portátiles(PDA)con conexiones a Internet sin cables). Dentro de los sistemas terminales de Internet también se incluyen computadores con los que los usuarios finales no interaccionan directamente, como los servidores web y de correo electrónico. Además, un número creciente de dispositivos alternativos, como clientes ligeros y aparatos domésticos, TV Web y set top boxes o cámaras digitales, están siendo conectados a Internet como sistemas finales. Los sistemas terminales son llamados también anfitriones (host), porque alojan programas de ejecución, como navegadores web, lectores de correo electrónico, o servidores de correo.
Los anfitriones se dividen, a veces, en dos categorías: clientes y servidores. Informalmente los clientes suelen ser computadores personales de mesa (PC) o portátiles, PDA y otros, mientras que los servidores suelen ser maquinas mas potentes que alojan servidores, como servidores web o de correo. En el contexto de software de redes, hay otra definición de cliente y servidor. Un programa cliente es un programa que se ejecuta en un sistema terminal que solicita y recibe un servicio de un programa servidor que se ejecuta en otro sistema terminal. Este modelo cliente /servidor es indudablemente la estructura mas predominante en las aplicaciones Internet. La Web, el correo electrónico, la transferencia de archivos, la entrada remota, los grupos de noticias y muchas otras aplicaciones populares, adoptan el modelo cliente/servidor. Puesto que un programa cliente normalmente se ejecuta en un computador y el servidor en otro, las aplicaciones internet cliente/servidor son por definición, aplicaciones distributivas.
4.2.2) Servicio sin conexión y orientado a conexión
Los sistemas terminales utilizan Internet para comunicarse con otros sistemas . Específicamente, los programas de sistemas terminales utilizan los servicios Internet para enviarse mensajes entre ellos. Los enlaces, routers y otras partes de Internet proporcionan el medio para transportar estos mensajes entre los programas de los sistemas terminales.
Las redes TCP/IP, y en particular Internet, proporcionan dos tipos de servicios a las aplicaciones de los dos sistemas terminales: servicio sin conexión y servicio orientado a la conexión. Un desarrollador que cree una aplicación internet debe diseñar la aplicación para utilizar uno de estos dos servicios.
Cuando una aplicación utiliza un servicio orientado a conexión, el programa cliente y el servidor se envían paquetes de control antes de enviar paquetes con datos reales. El llamado procedimiento de acuerdo alerta al cliente y al servidor, permitiendo prepararse para una avalancha de paquetes. Una vez acabado el procedimiento de acuerdo, se dice que se ha establecido una conexión entre los dos sistemas terminales. ¿Pero porque se utiliza la expresión "servicio orientado a conexión", y no simplemente "servicio con conexión"? Esta terminología se debe al hecho de que los sistemas terminales están conectados de forma ligera.
El servicio orientado a conexión de Internet llega ligado a otros servicios distintos, como la transferencia fiable de datos, el control del flujo y el control de gestión. Con la expresión "transferencia fiable de datos", queremos decir que una aplicación puede confiar en la conexión para entregar todos sus datos sin error y en el orden adecuado. La fiabilidad en Internet se consigue a través del uso de reconocimientos y retransmisiones.
Los sistemas terminales utilizan Internet para comunicarse con otros sistemas . Específicamente, los programas de sistemas terminales utilizan los servicios Internet para enviarse mensajes entre ellos. Los enlaces, routers y otras partes de Internet proporcionan el medio para transportar estos mensajes entre los programas de los sistemas terminales.
Las redes TCP/IP, y en particular Internet, proporcionan dos tipos de servicios a las aplicaciones de los dos sistemas terminales: servicio sin conexión y servicio orientado a la conexión. Un desarrollador que cree una aplicación internet debe diseñar la aplicación para utilizar uno de estos dos servicios.
Cuando una aplicación utiliza un servicio orientado a conexión, el programa cliente y el servidor se envían paquetes de control antes de enviar paquetes con datos reales. El llamado procedimiento de acuerdo alerta al cliente y al servidor, permitiendo prepararse para una avalancha de paquetes. Una vez acabado el procedimiento de acuerdo, se dice que se ha establecido una conexión entre los dos sistemas terminales. ¿Pero porque se utiliza la expresión "servicio orientado a conexión", y no simplemente "servicio con conexión"? Esta terminología se debe al hecho de que los sistemas terminales están conectados de forma ligera.
El servicio orientado a conexión de Internet llega ligado a otros servicios distintos, como la transferencia fiable de datos, el control del flujo y el control de gestión. Con la expresión "transferencia fiable de datos", queremos decir que una aplicación puede confiar en la conexión para entregar todos sus datos sin error y en el orden adecuado. La fiabilidad en Internet se consigue a través del uso de reconocimientos y retransmisiones.
4.3) Protocolo de Internet
Como administrador de la red, casi siempre utilizará el Protocolo de Control de Transmisión/Protocolo de Internet (TCP/IP). La mayoría de las tecnologías lo llaman simplemente como protocolo de Internet o IP. Aun cuando el nuevo IPv6 tiene muchas ventajas sobre su predecesor, IPv4 se sigue utilizando en la mayoría de las redes de área local.
Como administrador de la red, casi siempre utilizará el Protocolo de Control de Transmisión/Protocolo de Internet (TCP/IP). La mayoría de las tecnologías lo llaman simplemente como protocolo de Internet o IP. Aun cuando el nuevo IPv6 tiene muchas ventajas sobre su predecesor, IPv4 se sigue utilizando en la mayoría de las redes de área local.
4.3.1) IPv4 y su categorización
El protocolo Internet versión 4 o IPv4 es el más utilizado. El IP reside en la capa de red del modelo OSI y las direcciones IP consisten de cuatro números, cada uno entre O y 255. La suite de protocolo está integrada en la mayoría de los sistemas operativos y se utiliza en la mayoría de las conexiones a Internet en los Estados Unidos y muchos otros países. Como se mencionó en la lección 1, está compuesto de una porción de red y una porción de host, los cuales son definidos por la máscara de subred. Para que una dirección IP funcione, debe haber una dirección IP apropiadamente configurada y una máscara de subred compatible. Para conectase a Internet, también necesita una dirección de puerta de enlace y una dirección de servidor DNS. Ejemplos avanzados de configuración IP incluyen el subnereo, la traducción de dirección de red (NAT) y el enrutamiento de interdominio sin clases (CTDR).
Las direcciones IPv4 han sido categorizadas en cinco clases de IP. Algunas están reservadas para uso privado, mientras que el resto se utiliza por conexiones públicas. Este sistema de clasificación ayuda a definir cuáles redes se pueden utilizar en una LAN y qué direcciones IP pueden ser utilizadas en la Internet.
Al sistema de clasificación de IPv4 se le conoce como la arquitectura de red con clases y está dividido en cinco secciones, eres de las cuales son utilizadas por hosts en redes (clases A, By C). El primer octeto de la dirección IP define a cuál clase pertenece.


El protocolo Internet versión 4 o IPv4 es el más utilizado. El IP reside en la capa de red del modelo OSI y las direcciones IP consisten de cuatro números, cada uno entre O y 255. La suite de protocolo está integrada en la mayoría de los sistemas operativos y se utiliza en la mayoría de las conexiones a Internet en los Estados Unidos y muchos otros países. Como se mencionó en la lección 1, está compuesto de una porción de red y una porción de host, los cuales son definidos por la máscara de subred. Para que una dirección IP funcione, debe haber una dirección IP apropiadamente configurada y una máscara de subred compatible. Para conectase a Internet, también necesita una dirección de puerta de enlace y una dirección de servidor DNS. Ejemplos avanzados de configuración IP incluyen el subnereo, la traducción de dirección de red (NAT) y el enrutamiento de interdominio sin clases (CTDR).
Las direcciones IPv4 han sido categorizadas en cinco clases de IP. Algunas están reservadas para uso privado, mientras que el resto se utiliza por conexiones públicas. Este sistema de clasificación ayuda a definir cuáles redes se pueden utilizar en una LAN y qué direcciones IP pueden ser utilizadas en la Internet.
Al sistema de clasificación de IPv4 se le conoce como la arquitectura de red con clases y está dividido en cinco secciones, eres de las cuales son utilizadas por hosts en redes (clases A, By C). El primer octeto de la dirección IP define a cuál clase pertenece.

Las direcciones de red de Clase A se utilizan por el gobierno, ISPs, grandes corporaciones y grandes universidades. Las direcciones de Clase B son utilizadas por compañías medianas e ISPs más pequeños. Las direcciones de red de Clase e son Utilizadas por pequeñas oficinas y oficinas caseras.
En la tabla, el término nodo es sinónimo de host." Si una dirección IP es de Clase A, el primer octeto está considerado para ser la porción de "red". Los otros tres octetos son entonces para porciones de dirección, de nodo o host. Así que, una computadora podría estar en la red 11 y tener una ID de host individual de 38.250.1, haciendo la dirección IP completa en 11.38.250.1. Mirando la tabla, puede observar un patrón. En particular, las direcciones de Clase B utilizan dos octetos para la porción de red (por ejemplo, 128.1 ). Los otros dos octetos están en la porción de host. Mientas tamo, las direcciones de Clase C utilizan los primeros tres octetos como la porción de red. Aquí, el último octeto es la porción de host.
Hay otras acotaciones que necesitamos hacer a esta tabla.
Primero, como se muestra, el rango para la Clase A es 0- 127. Sin embargo, el número de red 127 no es utilizado por los hosts como dirección IP lógica. En su lugar, esa red se emplea para la dirección IP de loopback, lo cual permite hacer pruebas.
Segundo, como puede observar en la Tabla 4- 1, vea la máscara de subred por defecto para cada clase. Observe como ascienden en forma correspondiente a las porciones de red/nodos. Memorice la mascara de subred por defecto para las Clases A, B y C.
Tercero, come en cuenta que el número rotal de direcciones utilizables siempre será dos menos que la cantidad matemática. Por ejemplo, en una red Clase C tal como 192.168.50.0, hay 256 valores matemáticos: los números van del 0 al 255. Sin embargo, la primera y última dirección no se pueden utilizar. El número 0 y el número 255 no se pueden utilizar como direcciones IP lógicas para host debido a que ya se están utilizando automáticamente.
Siguiente, la Clase D y Clase E no son utilizadas por host normales. Por lo ramo, no se les da una clasificación de red/nodo y como resultado, no se les da un número específico de redes o total de hosts que puedan utilizar. En su lugar, la Clase Des utilizada para lo que se conoce como multicasting, transmitiendo información a múltiples computadoras (o routers). La Clase E fue reservada para uso futuro, pero en lugar de eso, dio paso a la IPv6.
Finalmente, intente tener el hábito de convertir octetos de IP a su forma binaria.

4.3.2) Traducción de dirección de red
La Traducción de dirección de red o NAT es el proceso de modificar una dirección IP mientras esta transita a través de un router, computadora, o dispositivo similar. Esto se refiere a que un espacio de dirección (privado) se pueda remapear a otro espacio de dirección o cal vez a una sola dirección IP pública. Este proceso se conoce como enmascaramiento IP y fue originalmente implementado dado al problema de la escasez de direcciones IPv4. Hoy en día, la NAT esconde la dirección IP interna privada de una persona, haciéndola más segura. Algunos roucers solo permiten NAT básicas, lo cual lleva a cabo solo traducción de dirección lP. Sin embargo, los routers más avanzados permiten la traducción de dirección de puerto (PAT), un subconjunto de NAT, el cual traduce cinco direcciones IP y números de puerto. Una implementación de NAT en un firewall esconde coda una red de direcciones IP (por ejemplo, la red 192.168.)0.0) detrás de una sola dirección IP desplegada públicamente. Muchos routers SOHO, servidores y dispositivos similares ofrecen esta tecnología para proteger las computadoras de una compañía en una LAN de o o intrusiones externas.
La siguiente figura ilustra cómo se puede implementar una NAT con algunas direcciones IP ficticias. Aquí, el router tiene dos conexiones de red. Una va a la LAN, 192.168.50.254 y es una dirección IP privada. Esto también es conocido como una dirección Ethernet y algunas veces se define como E^0 o la primera dirección Ethernet. La otra conexión va a Internet o a la WAN, 64.51.216.27 y es una dirección pública. Algunas veces, esto será definido como S^0, lo cual denota una dirección serial (común para proveedores como Cisco). Así que el router está empleando NAT para proteger a todas las computadoras de la organización (y switches) en la LAN de posibles ataques iniciados por personas maliciosas en Internet o en otras ubicaciones fuera de la LAN.

La Traducción de dirección de red o NAT es el proceso de modificar una dirección IP mientras esta transita a través de un router, computadora, o dispositivo similar. Esto se refiere a que un espacio de dirección (privado) se pueda remapear a otro espacio de dirección o cal vez a una sola dirección IP pública. Este proceso se conoce como enmascaramiento IP y fue originalmente implementado dado al problema de la escasez de direcciones IPv4. Hoy en día, la NAT esconde la dirección IP interna privada de una persona, haciéndola más segura. Algunos roucers solo permiten NAT básicas, lo cual lleva a cabo solo traducción de dirección lP. Sin embargo, los routers más avanzados permiten la traducción de dirección de puerto (PAT), un subconjunto de NAT, el cual traduce cinco direcciones IP y números de puerto. Una implementación de NAT en un firewall esconde coda una red de direcciones IP (por ejemplo, la red 192.168.)0.0) detrás de una sola dirección IP desplegada públicamente. Muchos routers SOHO, servidores y dispositivos similares ofrecen esta tecnología para proteger las computadoras de una compañía en una LAN de o o intrusiones externas.
La siguiente figura ilustra cómo se puede implementar una NAT con algunas direcciones IP ficticias. Aquí, el router tiene dos conexiones de red. Una va a la LAN, 192.168.50.254 y es una dirección IP privada. Esto también es conocido como una dirección Ethernet y algunas veces se define como E^0 o la primera dirección Ethernet. La otra conexión va a Internet o a la WAN, 64.51.216.27 y es una dirección pública. Algunas veces, esto será definido como S^0, lo cual denota una dirección serial (común para proveedores como Cisco). Así que el router está empleando NAT para proteger a todas las computadoras de la organización (y switches) en la LAN de posibles ataques iniciados por personas maliciosas en Internet o en otras ubicaciones fuera de la LAN.

4.3.3) Enrutamiento de interdominio sin clases
El enrutamiento interdominio sin clases (CIDR) es una manera de asignación de direcciones IP y enrutamiento de paquetes de protocolo Internet. Estaba destinado a remplazar la anterior arquitectura de direccionamiento IP con clases en un intento de retardar la escasez de direcciones IPv4. El enrutamiento interdominio sin clases está
basado en el enmascarado de subred de longitud variable (VLSM), el cual permite a una red ser dividida en subredes de diferentes tamaños para realizar una red lP que haya sido considerada previamente como una clase A y que se vea como una Clase B o C. Esto puede ayudar a los administradores de red a utilizar eficientemente subredes sin desperdiciar direcciones IP.
Un ejemplo de CIDR sería el número de red IP 192.168.0.0116. El /16 significa que la máscara de subred tiene 16 bies enmascarados (o 1s) lo que da 255.255.0.0. Usualmente, sería una máscara de subred de Clase B por defecto, pero debido a que estamos utilizándola en conjunción con lo que solía ser ·un número de red de Clase C, absolutamente todo el conjunto queda sin clase.
El enrutamiento interdominio sin clases (CIDR) es una manera de asignación de direcciones IP y enrutamiento de paquetes de protocolo Internet. Estaba destinado a remplazar la anterior arquitectura de direccionamiento IP con clases en un intento de retardar la escasez de direcciones IPv4. El enrutamiento interdominio sin clases está
basado en el enmascarado de subred de longitud variable (VLSM), el cual permite a una red ser dividida en subredes de diferentes tamaños para realizar una red lP que haya sido considerada previamente como una clase A y que se vea como una Clase B o C. Esto puede ayudar a los administradores de red a utilizar eficientemente subredes sin desperdiciar direcciones IP.
Un ejemplo de CIDR sería el número de red IP 192.168.0.0116. El /16 significa que la máscara de subred tiene 16 bies enmascarados (o 1s) lo que da 255.255.0.0. Usualmente, sería una máscara de subred de Clase B por defecto, pero debido a que estamos utilizándola en conjunción con lo que solía ser ·un número de red de Clase C, absolutamente todo el conjunto queda sin clase.
4.3.4) IPv6
IPv6 es la nueva generación de direccionamiento lP para Internet, pero también puede ser utilizado en redes de oficinas pequeñas y redes caseras. Fue diseñado para vencer las limitaciones de IPv4, incluyendo espacios de dirección y seguridad .
lPv6 ha sido definido por más de una década y lentamente ha ganado aceptación en el mundo de las redes, aunque aún se considera que está en una etapa temprana. La razón número uno para utilizar IPv6 es el espacio para dirección. IPv6 es un sistema de 128-bit, mientras que su todavía dominante predecesor IPv4 es un sistema de solamente 32-bit. ¿Qué significa esto? Bien, mientras que IPv4 puede tener aproximadamente 4 billones de direcciones IP en todo el sistema, IPv6 puede tener 340 undecillones de direcciones (340 con 36 ceros).
Por supuesto, varias limitaciones en el sistema reducirán ese número, pero el resultado final aún es mucho más grande que en el sistema IPv4. Sin embargo, otra razón para utilizar IPv6 es la avanzada seguridad integrada; por ejemplo, IPsec es un componente fundamental del IPv6 (discutiremos IPSec a profundidad en la Lección 6). IPv6 también tiene muchos avances y una mayor simplificación cuando se trata de asignación de direcciones.
IPv6 también soporta jumbogramas. Estos son paquetes mucho más grandes de lo que IPv4 puede manejar. Normalmente, los paquetes IPv4 tienen alrededor de 1,500 bytes de tamaño. Pero pueden ser tan grandes como 65,535 bytes. En comparación, los paquetes IPv6 pueden ser de hasta 4 billones de bytes.
Ya mencionamos que las direcciones de IPv6 son números de 128-bit. También tienen formato hexadecimal y están divididas en ocho grupos de cuatro números cada uno, cada grupo está separado por dos puntos ":". Estos separadores de dos puntos":" contrastan con la notación de punto decimal de IPv4. En Windows, las direcciones IPv6 son asignadas automáticamente y autoconfiguradas y son conocidas como direcciones de enlace local.
Hay tres tipos principales de direcciones IPv6:
IPv6 es la nueva generación de direccionamiento lP para Internet, pero también puede ser utilizado en redes de oficinas pequeñas y redes caseras. Fue diseñado para vencer las limitaciones de IPv4, incluyendo espacios de dirección y seguridad .
lPv6 ha sido definido por más de una década y lentamente ha ganado aceptación en el mundo de las redes, aunque aún se considera que está en una etapa temprana. La razón número uno para utilizar IPv6 es el espacio para dirección. IPv6 es un sistema de 128-bit, mientras que su todavía dominante predecesor IPv4 es un sistema de solamente 32-bit. ¿Qué significa esto? Bien, mientras que IPv4 puede tener aproximadamente 4 billones de direcciones IP en todo el sistema, IPv6 puede tener 340 undecillones de direcciones (340 con 36 ceros).
Por supuesto, varias limitaciones en el sistema reducirán ese número, pero el resultado final aún es mucho más grande que en el sistema IPv4. Sin embargo, otra razón para utilizar IPv6 es la avanzada seguridad integrada; por ejemplo, IPsec es un componente fundamental del IPv6 (discutiremos IPSec a profundidad en la Lección 6). IPv6 también tiene muchos avances y una mayor simplificación cuando se trata de asignación de direcciones.
IPv6 también soporta jumbogramas. Estos son paquetes mucho más grandes de lo que IPv4 puede manejar. Normalmente, los paquetes IPv4 tienen alrededor de 1,500 bytes de tamaño. Pero pueden ser tan grandes como 65,535 bytes. En comparación, los paquetes IPv6 pueden ser de hasta 4 billones de bytes.
Ya mencionamos que las direcciones de IPv6 son números de 128-bit. También tienen formato hexadecimal y están divididas en ocho grupos de cuatro números cada uno, cada grupo está separado por dos puntos ":". Estos separadores de dos puntos":" contrastan con la notación de punto decimal de IPv4. En Windows, las direcciones IPv6 son asignadas automáticamente y autoconfiguradas y son conocidas como direcciones de enlace local.
Hay tres tipos principales de direcciones IPv6:
- Dirección Unícast: esta es una sola dirección en una sola interfaz. Hay dos tipos de direcciones unicast. La primera, direcciones de unicast globales son ruteables y desplegables directamente a Internet. Estas direcciones empiezan en el rango 2000. El otro tipo es la ya mencionada dirección de enlace local. Estas están divididas en dos subtipos, la dirección auto configurada de Windows, la cual comienza en FE80, FE90, FEA0 y FEB0 y la dirección de loopback, la cual es conocida como ::1, donde ::1 es el equivalente de IPv4 para 127 .0.0.1.
- Dirección Anycast: estas son direcciones asignadas a un grupo de interfaces, más probablemente en host separados. Los paquetes que son enviados a estas direcciones se entregan solo a una de las interfaces, generalmente, la primera o más cercana disponible. Estas direcciones son utilizadas en sistemas de conmutación por error.
- Dirección Multicast: estas direcciones también son asignadas a un grupo de interfaces y son más probables en hosts separados, pero los paquetes enviados a dicha dirección son entregados a todas las interfaces del grupo. Esto es similar a la dirección de broadcast de IPv4 (tal como 192.168.1.255). Las direcciones Multicast no sufren de tormentas de broadcast de la manera en que su contraparte lo hace.
CAPITULO 5. MODELOS DE REFERENCIA
Ahora que hemos analizado en lo abstracto las redes basadas en capas, es tiempo de ver algunos ejemplos.
Analizaremos dos arquitecturas de redes importantes: el modelo de referencia OSI y el modelo de referencia TCP/IP. Aunque ya casi no se utilizan los protocolos asociados con el modelo OSI, el modelo en sí es bastante general y sigue siendo válido; asimismo, las características en cada nivel siguen siendo muy importantes. El modelo TCP/IP tiene las propiedades opuestas: el modelo en sí no se utiliza mucho, pero los protocolos son usados ampliamente. Por esta razón veremos ambos elementos con detalle. Además, algunas veces podemos aprender más de los fracasos que de los éxitos.
5.1) Modelo de referencia OSI
Este modelo se basa en una propuesta desarrollada por la Organización Internacional de Normas (ISO) como el primer paso hacia la estandarización internacional de los protocolos utilizados en las diversas capas. Este modelo se revisó en 1995 y se le llama Modelo de referencia OSI (Interconexión de Sistemas Abiertos, Open Systems Interconnection) de la iso puesto que se ocupa de la conexión de sistemas abiertos; esto es, sistemas que están abiertos a la comunicación con otros sistemas. Para abreviar, lo llamaremos modelo OSI.
El modelo OSI tiene siete capas. Los principios que se aplicaron para llegar a las siete capas se pueden resumir de la siguiente manera:
- Se debe crear una capa en donde se requiera un nivel diferente de abstracción.
- Cada capa debe realizar una función bien definida.
- La función de cada capa se debe elegir teniendo en cuenta la definición de protocolos estandarizados internacionalmente.
- Es necesario elegir los límites de las capas de modo que se minimice el flujo de información a través de las interfaces.
- La cantidad de capas debe ser suficiente como para no tener que agrupar funciones distintas en la misma capa; además, debe ser lo bastante pequeña como para que la arquitectura no se vuelva inmanejable.
A continuación mostramos el modelo OSI (sin el medio físico):

5.1.1) Capas de modelo OSI
El modelo OSI fue creado como un conjunto de siete capas o niveles, cada uno de los cuales hospeda diferentes
protocolos dentro de uno o varias suites de protocolos, el más común es TCP/IP. El modelo OSI categoriza cómo
ocurren las transacciones TCP/IP y esto es invaluable cuando viene la instalación, configuración, mantenimiento y especialmente la resolución de problemas de red.
Algunas veces una suite de protocolos, cal como TCP/IP, es definido como Pila de protocolos. El modelo OSI muestra cómo trabaja la pila de protocolos en diferentes niveles de transmisión (eso es, cómo se apilan contra el modelo}. Como se mencionó anteriormente, una LAN requiere computador-as con adaptadores de red. Estos deben estar conectados juntos de alguna manera para facilitar la transferencia de daros. Es importante definir cómo las computadoras están conectadas juntas y también cómo transmiten datos. Las capas del modelo OSI hacen justo eso. Lo siguiente es una breve descripción de cada capa:
El modelo OSI fue creado como un conjunto de siete capas o niveles, cada uno de los cuales hospeda diferentes
protocolos dentro de uno o varias suites de protocolos, el más común es TCP/IP. El modelo OSI categoriza cómo
ocurren las transacciones TCP/IP y esto es invaluable cuando viene la instalación, configuración, mantenimiento y especialmente la resolución de problemas de red.
Algunas veces una suite de protocolos, cal como TCP/IP, es definido como Pila de protocolos. El modelo OSI muestra cómo trabaja la pila de protocolos en diferentes niveles de transmisión (eso es, cómo se apilan contra el modelo}. Como se mencionó anteriormente, una LAN requiere computador-as con adaptadores de red. Estos deben estar conectados juntos de alguna manera para facilitar la transferencia de daros. Es importante definir cómo las computadoras están conectadas juntas y también cómo transmiten datos. Las capas del modelo OSI hacen justo eso. Lo siguiente es una breve descripción de cada capa:
- Capa 1- Capa Física: este es el medio físico y eléctrico para transferir datos. No está limitado a cables, conectores, paneles de conexión, cajas de conexión, concentradores y unidades de acceso multiestación (.MAU's). Esta capa también es conocida como la planta física. Los conceptos relacionados con la capa física incluyen topologías, codificación análoga contra digital, sincronización de bits, banda base contra banda ancha, multiplexado y transferencia de datos serial (lógica de 5 volts}. Si puede tocar un elemento de red, es ce es una paree de la capa física, lo cual hace a esta capa más fácil de comprender. La unidad de medida de esta capa son los bits.
- Capa 2-Capa de Enlace de Datos (DLL): esta capa establece, mantiene y decide cómo es lograda la transferencia a través de la capa física. Los dispositivos que existen en esta capa ([)Ll..) son las tarjetas de interfaz de red y los puentes. Esta capa también asegura transmisión libre de errores sobre la capa física bajo transmisiones LAN. Lo hace a través de las direcciones físicas (la dirección hexadecimal que está pegada en la ROM de la NIC), conocida también como dirección MAC (que se discutirá después en esta lección). Casi cualquier dispositivo que hace una conexión física a una red y tiene la habilidad de mover información está en la capa de enlace de datos. La unidad de medida de esta capa son los Marcos (Frames).
- Capa 3-Capa de red: esta capa está dedicada a enrutar e intercambiar información a diferentes redes, LANs o interconexión de redes. Esta puede ser en una LAN o WAN (red de área amplia). Los dispositivos que existen en la capa de red son routers y switches IP. En este punto, estamos entrando a direccionamiento lógico de anfitriones (hosts). En lugar de direcciones físicas, el sistema de direccionamiento de la computadora es almacenado en el sistema operativo, por ejemplo, direcciones IP. Ahora puede ver que una computadora típica en realidad tiene dos direcciones: una física o dirección basada en hardware tal como la dirección MAC, y una lógica o dirección basada en software cal como una dirección IP. Paree del e ruco en redes es asegurarse que las dos direcciones se llevan bien. La unidad de medida utilizada en esta capa son los paquetes.
- Capa 4-Capa de transporte: esta capa asegura transmisiones libres de errores entre anfitriones (hosts) a a través de direccionamiento lógico. Por lo tanto, maneja la transmisión de mensajes a través de las capas que van de la 1 a la 3. Los protocolos en esta Capa se dividen en mensajes, los envía a través de la subred y asegura su correcto montaje en el lado receptor, asegurándose que no hay mensajes duplicados o perdidos. Esca capa contiene tanto conexión orientada como sistemas sin conexión. Los puertos de entrada y salida son controlados por esta capa. Cuando usted piensa en "puercos", piensa en la capa de transporte. La unidad de medida utilizada en esta capa algunas veces se define como segmentos o mensajes. Todas las capas por encima de esta utilizan los términos "datos" y " mensajes".
- Capa 5-Capa de Sesión: esta capa controla el establecimiento, terminación y sincronización de sesiones dentro del Sistema Operativo sobre la red y entre anfitriones (hosts), por ejemplo, cuando inicia (log on) y termina sesión (log off). Esta es la capa que controla la base de datos de nombre y direcciones para el Sistema Operativo o Sistema Operativo en Red. NetBIOS (Sistema Básico de Entrada y Salida de red) trabaja en esta capa.
- Capa 6-Capa de Presentación: esta capa traduce el formato de datos de transmisor al receptor en los varios Sistemas Operativos que puedan ser usados. los conceptos incluyen conversión de código, compresión de datos y encriptación de archivos. Los redirectores trabajan en esta capa, tal como las unidades de red mapeadas que habilitan a la computadora para acceder a archivos compartidos en una computadora remota.
- Capa 7- Capa de aplicación: esta capa es donde comienza la creación de mensajes y, por lo tanto, la creación de paquetes. El acceso a base de datos está en este nivel. Los protocolos de usuario final tales como FTP, SMTP, Telnet y RAS trabajan en esta capa. Por ejemplo, suponga que está utilizando Ourlook Express. Usted teclea un mensaje y hace clie en Enviar. Esto inicializa SMTP (protocolo simple de transferencia de correo) y otros protocolos, SMTP envía el mensaje de correo a través de las otras capas, dividiéndose en paquetes en la capa de red y así sucesivamente. Esca capa no es la aplicación en sí, sino los protocolos que son iniciados por esta capa.
5.1.2) Subredes de comunicaciones
La subred de comunicaciones es la entraña de las transmisiones del modelo OSI, consistentes de las capas 1 a la 3. Sin importar qué tipo de transmisión de dates ocurra en la red, se utilizará la subred de comunicaciones.
La subred de comunicaciones es la entraña de las transmisiones del modelo OSI, consistentes de las capas 1 a la 3. Sin importar qué tipo de transmisión de dates ocurra en la red, se utilizará la subred de comunicaciones.
5.1.3) Switcheo de capa 2 y 3
La capa de enlace de datos es también donde residen los switches de la capa 2. Un switch de capa 2 es el tipo más común de switch utilizado en una LAN. Estos switches están basados en hardware y utilizan la dirección MAC del adaptador de red de cada host cuando está decidiendo hacia dónde dirigir los marcos de datos, cada puerto en el switch es mapeado a una dirección MAC específica de la computadora que está conectada físicamente a él. Los switches de capa 2 normalmente no modifican marcos conforme pasan a través del switch en su camino de una computadora a otra. Cada puerco en un switch está considerado como su propio segmento. Esto significa que cada computadora conectada a un switch de capa 2 tiene su propio ancho de banda utilizable, que corresponde a la tasa del switch: 10 Mbps, 100 Mbps, 1 Gbps, etcétera.
La seguridad es una preocupación con los switches de capa 2. Los switches tienen una memoria que está reservada para almacenar la dirección MAC a la tabla de traducción de puerro, conocida como rabia de memoria de contenido direccionable o rabia CAM. Esta tabla puede ser comprometida con un ataque de desbordamiento MAC. Tal ataque enviará numerosos paquetes. al switch, cada uno de los cuales tiene una dirección MAC origen diferente, en un intento por utilizar la memoria del switch. Si esto tiene éxito, el switch cambiará el estado a lo que se conoce como modo failopen. En este punto, el switch transmitirá datos a todos los puercos de la forma en que lo hace un hub. Esto significa dos cosas: primero, ese ancho de banda será dramáticamente reducido y, segundo, que una persona maliciosa podría ahora utilizar un analizador de protocolo para capturar la información de cualquier otra computadora en la red.
El switcheo de capa 2 puede también permitir que se implemente una LAN Virtual (VLAN). Una VLAN se implementa para segmentar la red, reducir colisiones, organizar la red, impulsar el desempeño y, con suerte, incrementar la seguridad. Es importante ubicar enchufes de red físicos en ubicaciones seguras cuando se trata de VLANs que tienen acceso a datos confidenciales. También hay tipos lógicos de VLANs como la VLAN basada en protocolo y la VLAN basada en direcciones MAC, las cuales tienen un gran conjunto de precauciones de seguridad separadas. El estándar más común asociado con VLANs es el IEEE 802.1Q. Este modifica marcos Ethernet al "etiquetarlos" (cagging) con la información VLAN apropiada. Las VLANs son utilizadas para restringir el acceso a recursos de red, pero esto puede ser anulado a través del uso de un salto de VLAN. El salto de VLAN puede ser evitado actualizando el firmware o software, seleccionando una VLAN sin utilizar como la VLAN predeterminada para codas las líneas y rediseñando la VLAN si múltiples emplean varios switches 802.1Q.
Puntos de acceso inalámbricos, puentes, switches de capa 2 y los adaptadores de red residen en la capa de enlace de datos.
Los switches también residen en la capa de red. Un switch de capa 3 difiere del switch de capa 2 en que este determina rutas para los daros utilizando el direccionamiento lógico (dirección IP) en lugar de direccionamiento físico (direcciones MAC). Los switches de capa 3 son similares a los routers, es como el ingeniero de red implementa el switch lo que lo hace diferente. Los switches de capa 3 reenvían paquetes, mientras que los switches de capa 2 reenvían marcos. Los switches de capa 3 son regularmente switches administrados, el ingeniero de redes puede administrarlos util izando el Protocolo Simple de Administración de Red (SNMP) entre otras herramientas. Esto le permite al ingeniero de redes analizar todos los paquetes que pasan a través del switch, lo cual no puede hacerse con un switch de capa 2. Un switch de capa 2 es más como una versión avanzada de un puente, mientras que un switch de capa 3 es más parecido a un router. Los switches de capa 3 son utilizados en ambientes ocupados en los cuales múltiples redes IP necesitan conectase.
La capa de enlace de datos es también donde residen los switches de la capa 2. Un switch de capa 2 es el tipo más común de switch utilizado en una LAN. Estos switches están basados en hardware y utilizan la dirección MAC del adaptador de red de cada host cuando está decidiendo hacia dónde dirigir los marcos de datos, cada puerto en el switch es mapeado a una dirección MAC específica de la computadora que está conectada físicamente a él. Los switches de capa 2 normalmente no modifican marcos conforme pasan a través del switch en su camino de una computadora a otra. Cada puerco en un switch está considerado como su propio segmento. Esto significa que cada computadora conectada a un switch de capa 2 tiene su propio ancho de banda utilizable, que corresponde a la tasa del switch: 10 Mbps, 100 Mbps, 1 Gbps, etcétera.
La seguridad es una preocupación con los switches de capa 2. Los switches tienen una memoria que está reservada para almacenar la dirección MAC a la tabla de traducción de puerro, conocida como rabia de memoria de contenido direccionable o rabia CAM. Esta tabla puede ser comprometida con un ataque de desbordamiento MAC. Tal ataque enviará numerosos paquetes. al switch, cada uno de los cuales tiene una dirección MAC origen diferente, en un intento por utilizar la memoria del switch. Si esto tiene éxito, el switch cambiará el estado a lo que se conoce como modo failopen. En este punto, el switch transmitirá datos a todos los puercos de la forma en que lo hace un hub. Esto significa dos cosas: primero, ese ancho de banda será dramáticamente reducido y, segundo, que una persona maliciosa podría ahora utilizar un analizador de protocolo para capturar la información de cualquier otra computadora en la red.
El switcheo de capa 2 puede también permitir que se implemente una LAN Virtual (VLAN). Una VLAN se implementa para segmentar la red, reducir colisiones, organizar la red, impulsar el desempeño y, con suerte, incrementar la seguridad. Es importante ubicar enchufes de red físicos en ubicaciones seguras cuando se trata de VLANs que tienen acceso a datos confidenciales. También hay tipos lógicos de VLANs como la VLAN basada en protocolo y la VLAN basada en direcciones MAC, las cuales tienen un gran conjunto de precauciones de seguridad separadas. El estándar más común asociado con VLANs es el IEEE 802.1Q. Este modifica marcos Ethernet al "etiquetarlos" (cagging) con la información VLAN apropiada. Las VLANs son utilizadas para restringir el acceso a recursos de red, pero esto puede ser anulado a través del uso de un salto de VLAN. El salto de VLAN puede ser evitado actualizando el firmware o software, seleccionando una VLAN sin utilizar como la VLAN predeterminada para codas las líneas y rediseñando la VLAN si múltiples emplean varios switches 802.1Q.
Puntos de acceso inalámbricos, puentes, switches de capa 2 y los adaptadores de red residen en la capa de enlace de datos.
Los switches también residen en la capa de red. Un switch de capa 3 difiere del switch de capa 2 en que este determina rutas para los daros utilizando el direccionamiento lógico (dirección IP) en lugar de direccionamiento físico (direcciones MAC). Los switches de capa 3 son similares a los routers, es como el ingeniero de red implementa el switch lo que lo hace diferente. Los switches de capa 3 reenvían paquetes, mientras que los switches de capa 2 reenvían marcos. Los switches de capa 3 son regularmente switches administrados, el ingeniero de redes puede administrarlos util izando el Protocolo Simple de Administración de Red (SNMP) entre otras herramientas. Esto le permite al ingeniero de redes analizar todos los paquetes que pasan a través del switch, lo cual no puede hacerse con un switch de capa 2. Un switch de capa 2 es más como una versión avanzada de un puente, mientras que un switch de capa 3 es más parecido a un router. Los switches de capa 3 son utilizados en ambientes ocupados en los cuales múltiples redes IP necesitan conectase.
5.1.4) Capas superiores de OSI
Las capas superiores de OSI son las capas 4 hasta la 7, las capas de transporte, sesión, presentación y aplicación. Esta es la parte del modelo OSI que trata con los protocolos como el HTTP, FTP y protocolos de correo. La compresión, encriptación y creación de sesiones también son clasificadas en estas capas.
La capa 4 gobierna la transmisión de paquetes a través de subredes de comunicaciones. Dos protocolos comunes TCP/IP que son utilizados en esta capa incluyen al Protocolo de Control de Transmisión (TCP), el cual es un protocolo orientado a la conexión y el Protocolo de Datagrama de Usuario (UDP), el cual es sin conexión. Un ejemplo de una aplicación que utiliza TCP es un navegador web y un ejemplo de una aplicación que utiliza UDP es el streaming. Cuando descarga una página web, no querrá perder ningún paquete de información debido a que los gráficos podrían aparecer dañados, cierto texto podría no leerse correctamente, etc. Utilizando TCP, nos aseguramos que los datos llegan a su destino final. Si un paquete se pierde a lo largo del camino, este será reiniciado hasta que la compuradora destino reconozca la encrega o termine la sesión. Pero con streaming,
estaremos mirando o escuchando en tiempo real. Así que, si un paquete se pierde, no nos importa mucho, debido a que el marco del tiempo de vídeo o música )'a ha pasado. Una vez que el paquete se pierde, no queremos realmente recuperarlo. Por supuesto, si la pérdida del paquete se hace muy severa, el streaming será incomprensible.
La capa 4 también se encarga de los puerros que utiliza una computadora para la transmisión de datos. Los Puertos actúan como extremos (end points) de comunicaciones lógicas para computadoras. Hay un total de 65,536 puertos, numerados entre el O y 65,535. Están definidos por la autoridad de Números Asignados para Internet o lANA y se dividen en categorías:

Los números de Puerro corresponden a aplicaciones específicas, por ejemplo, el Puerco 80 es utilizado por navegadores web vía el protocolo HTTP. Es importante comprender la diferencia entre puertos de entrada y salida:
Las capas superiores de OSI son las capas 4 hasta la 7, las capas de transporte, sesión, presentación y aplicación. Esta es la parte del modelo OSI que trata con los protocolos como el HTTP, FTP y protocolos de correo. La compresión, encriptación y creación de sesiones también son clasificadas en estas capas.
La capa 4 gobierna la transmisión de paquetes a través de subredes de comunicaciones. Dos protocolos comunes TCP/IP que son utilizados en esta capa incluyen al Protocolo de Control de Transmisión (TCP), el cual es un protocolo orientado a la conexión y el Protocolo de Datagrama de Usuario (UDP), el cual es sin conexión. Un ejemplo de una aplicación que utiliza TCP es un navegador web y un ejemplo de una aplicación que utiliza UDP es el streaming. Cuando descarga una página web, no querrá perder ningún paquete de información debido a que los gráficos podrían aparecer dañados, cierto texto podría no leerse correctamente, etc. Utilizando TCP, nos aseguramos que los datos llegan a su destino final. Si un paquete se pierde a lo largo del camino, este será reiniciado hasta que la compuradora destino reconozca la encrega o termine la sesión. Pero con streaming,
estaremos mirando o escuchando en tiempo real. Así que, si un paquete se pierde, no nos importa mucho, debido a que el marco del tiempo de vídeo o música )'a ha pasado. Una vez que el paquete se pierde, no queremos realmente recuperarlo. Por supuesto, si la pérdida del paquete se hace muy severa, el streaming será incomprensible.
La capa 4 también se encarga de los puerros que utiliza una computadora para la transmisión de datos. Los Puertos actúan como extremos (end points) de comunicaciones lógicas para computadoras. Hay un total de 65,536 puertos, numerados entre el O y 65,535. Están definidos por la autoridad de Números Asignados para Internet o lANA y se dividen en categorías:

Los números de Puerro corresponden a aplicaciones específicas, por ejemplo, el Puerco 80 es utilizado por navegadores web vía el protocolo HTTP. Es importante comprender la diferencia entre puertos de entrada y salida:
- Puertos de entrada: estos son usados cuando otra computadora quiere conectarse a un servicio o aplicación que se ejecuta en su computadora. Los servidores utilizan puercos de entrada principalmente para poder aceptar conexiones entrantes y servir daros. Las direcciones IP y números de puercos se combinan, por ejemplo, un puerro/IP de un servidor 66.249.91.104:80 es la dirección IP 66.249.91.104 con el puerto número 80 abierto con el fin de aceptar peticiones de páginas web entrantes.
- Puertos de salida: estos son utilizados cuando su computadora quiere conectarse a un servicio o aplicación en otra computadora. Las computadoras cliente principalmente utilizan puerros de salida y se asignan dinámicamente por el sistema operativo.
5.2) Modelo de referencia TPC/IP
El modelo TCP/IP (o TCP) es similar al modelo OSI. A menudo es utilizado por fabricantes de software que no se centran canto en cómo la información es enviada sobre el medio físico o cómo el enlace de daros es realmente hecho. Este modelo está compuesto por solo cuatro capas.
Aunque el modelo OSI es un modelo de referencia, el modelo TCP/IP (también conocido como modelo DoD o modelo de Internet) es más descriptivo, definiendo principios como "extremo a extremo" y "robustez", lo cual describe fuentes conexiones endpoint y una transmisión de daros conservadora. Este modelo es sostenido por la Fuerza de Tareas de Ingeniería de lntemet (IETF). Los cuatro capas del modelo TCP/IP son las siguientes:
La capa física de OSI se omite por completo y la capa de aplicación comprime las capas de aplicación, presentación y sesión de OSI. Los programadores utilizan el modelo TCP/IP más a menudo que el modelo OSI, mientras que los administradores de red usual menee se benefician a un grado más aleo del modelo OSI. Los programadores generalmente están interesados en las interfaces hechas para capas de aplicación y transpone. Cualquier cosa por debajo de la capa de transpone es cuidado por la pila TCP/IP dentro del sistema operativo, la cual no es modificable. Los programas pueden desarrollarse para que utilicen la pila TCP, pero no para modificara.
El modelo TCP/IP (o TCP) es similar al modelo OSI. A menudo es utilizado por fabricantes de software que no se centran canto en cómo la información es enviada sobre el medio físico o cómo el enlace de daros es realmente hecho. Este modelo está compuesto por solo cuatro capas.
Aunque el modelo OSI es un modelo de referencia, el modelo TCP/IP (también conocido como modelo DoD o modelo de Internet) es más descriptivo, definiendo principios como "extremo a extremo" y "robustez", lo cual describe fuentes conexiones endpoint y una transmisión de daros conservadora. Este modelo es sostenido por la Fuerza de Tareas de Ingeniería de lntemet (IETF). Los cuatro capas del modelo TCP/IP son las siguientes:
- Capa 1: Capa de enlace de daros (también conocida simplemente como capa de enlace)
- Capa 2: Capa de red (también conocida como Capa de Internet)
- Capa 3: Capa de Transporte
- Capa 4: Capa de Aplicación
La capa física de OSI se omite por completo y la capa de aplicación comprime las capas de aplicación, presentación y sesión de OSI. Los programadores utilizan el modelo TCP/IP más a menudo que el modelo OSI, mientras que los administradores de red usual menee se benefician a un grado más aleo del modelo OSI. Los programadores generalmente están interesados en las interfaces hechas para capas de aplicación y transpone. Cualquier cosa por debajo de la capa de transpone es cuidado por la pila TCP/IP dentro del sistema operativo, la cual no es modificable. Los programas pueden desarrollarse para que utilicen la pila TCP, pero no para modificara.
5.2.1) Comandos básicos TCP/IP
Ipconfig y ping son unos de los mejores amigos del administrador de la red. Estos comandos básicos pueden ayudarle a analizar y solucionar problemas que puedan surgir en las redes. Además ofrecen un cierro nivel configurativo así como la habilidad para crear una base de referencia de desempeño. Estos comandos se utilizan en el símbolo del sistema de Windows, una herramienta con la cual todo administrador de una red debería estar familiarizado.
Para poder entender cómo trabajar con TCP/IP en línea de comandos, primero es necesario discutir cómo acceder al símbolo del sistema como administrador. Es importante explorar algunas formas para hacer que la línea de comandos funcione para usted así como la manera de ver los archivos de ayuda.
El símbolo de sistema de Windows es una versión de Microsoft de una interfaz de línea de comandos o CLI. De la misma forma en la cual puede realizar cualquier cosa en el GUI, también puede hacerlo en el símbolo del sistema y en el caso de los comandos TCP/IP, el símbolo del sistema puede ser más efectivo. El símbolo del sistema de hoy es el archivo ejecutable cmd.exe. Se encuentra localizado en C:\ Windows\system32. El antiguo
command .com no es recomendable cuando se utilizan comandos TCP/IP.
Ipconfig y ping son unos de los mejores amigos del administrador de la red. Estos comandos básicos pueden ayudarle a analizar y solucionar problemas que puedan surgir en las redes. Además ofrecen un cierro nivel configurativo así como la habilidad para crear una base de referencia de desempeño. Estos comandos se utilizan en el símbolo del sistema de Windows, una herramienta con la cual todo administrador de una red debería estar familiarizado.
Para poder entender cómo trabajar con TCP/IP en línea de comandos, primero es necesario discutir cómo acceder al símbolo del sistema como administrador. Es importante explorar algunas formas para hacer que la línea de comandos funcione para usted así como la manera de ver los archivos de ayuda.
El símbolo de sistema de Windows es una versión de Microsoft de una interfaz de línea de comandos o CLI. De la misma forma en la cual puede realizar cualquier cosa en el GUI, también puede hacerlo en el símbolo del sistema y en el caso de los comandos TCP/IP, el símbolo del sistema puede ser más efectivo. El símbolo del sistema de hoy es el archivo ejecutable cmd.exe. Se encuentra localizado en C:\ Windows\system32. El antiguo
command .com no es recomendable cuando se utilizan comandos TCP/IP.
5.2.2) Comandos avanzados TCP/IP
Los comandos TCP/IP avanzados como netstat, nbtscat y tracert le permiten analizar más facetas de una conexión TCP/IP que los comandos ipconfig y ping. Además, FTP, Telnet, necsh y route le permiten realizar más tareas que solo analizar un sistema, ya que le pueden ayudar a configurarlo.
Los comandos TCP/IP avanzados como netstat, nbtscat y tracert le permiten analizar más facetas de una conexión TCP/IP que los comandos ipconfig y ping. Además, FTP, Telnet, necsh y route le permiten realizar más tareas que solo analizar un sistema, ya que le pueden ayudar a configurarlo.
CAPITULO 6. REDES ALÁMBRICAS E INALÁMBRICAS
El cableado instalado apropiadamente y las redes inalámbricas son las claves para una planta física eficiente, el cable físico y las conexiones inalámbricas son el núcleo de una red rápida.
Las redes alámbricas siguen siendo el tipo más común de conexión física que se realiza en las computadoras. Aunque las redes inalámbricas hao hecho avances en muchas organizaciones, aún prevalecen las conexiones alámbricas. La mayoría de las computadoras utilizan cableado de par trenzado para sus conexiones físicas.
6.1.1) Identificar y trabajar con cable de par trenzado
El cable de par trenzado es el más utilizado en redes de área local. Es relativamente fácil trabajarlo, flexible, eficiente y rápido. Como administrador de red, debería saber cómo identificar los diferentes tipos de cableado de par trenzado, así como instalar cableado de par trenzado de forma temporal y permanente. Es importante saber como probar los cables de par trenzado en caso de alguna falla o para probar que las nuevas instalaciones trabajan apropiadamente.
Un solo par trenzado tiene ochos cables o hilos, los cuales son conductores de cobre que transmiten señales eléctricas. Los cables están agrupados en cuatro pares: azul, naranja, verde y café. Cada par de cables está trenzado a lo largo de todo el cable. La razón por la que los cables están trenzados es para reducir la diafonía e interferencia.

Hay dos tipos de cables de conexión de red con los que podría trabajar. El primero es un cable directo (stmight through). Este es el tipo más común de cable de conexión y el que usted debería utilizar para conectar una computadora a un dispositivo de conexión central como un switch. Se llama "directo" debido a que los cables de cada extremo están orientados de la misma manera. Generalmente, es un 568B en cada extremo. Sin embargo, hay otro tipo de cable de conexión, el cable cruzado.
Generalmente, Ethernet transmite señales de datos en los cables naranja y verde, es decir, en los pines uno, dos, tres y seis. Otras tecnologías utilizan diferentes pares o posiblemente los cuatro pares de cables. Regularmente, las redes de par trenzado están cableadas con el estándar 568B. Esto significa que codo el equipo de cableado debe cumplir con el estándar 568B, incluyendo los paneles de conexión, enchufes RJ45, cables de conexión y la terminación de cableado a cada uno de esos dispositivos.
La interferencia puede ser un problema real con las redes de par trenzado o cualquier otro cipo de red. La interferencia es cualquier cosa que interrumpa o modifique una señal que va viajando a través de un cable. Hay muchos tipos de interferencia, pero sólo hay algunas que debería conocer para el examen, incluyendo los siguientes:
Otro tipo común de interferencia es la diafonía. La diafonía es cuando la señal que es transmitida en cable de cobre o par de cables crea un efecto indeseado en otro cable o par de cables. Esto ocurre cuando las líneas de teléfono se ubican muy cerca una de la otra. Debido a que las líneas están demasiado cerca, la señal podría saltar de una línea a la otra de manera intermitente. Si alguna vez ha escuchado otra conversación mientras habla por teléfono en su hogar (y no de un teléfono celular), entonces ha sido víctima de la diafonía.
Cuando se trata de cableado de par trenzado, la diafonía se divide en dos categorías: Paradiafonía (NEXT) y telediafimía (FEXT). La NEXT ocurre cuando hay una interferencia medida entre dos pares en un solo cable, medida en el extremo del cable más cercano al transmisor. La FEXT ocurre cuando hay una interferencia similar, medida en el extremo del cable más lejano al transmisor. Si la diafonía es un problema, a pesar de emplearse cable de par trenzado e implementarse las transmisiones de datos digitales, se puede utilizar cable par trenzado blindado (STP). Normalmente, las compañías optan por cableado de par trenzado regular, el cual es par trenzado sin blindaje (también conocido como UTP), pero algunas veces, hay demasiada interferencia en el ambiente para enviar información efectivamente y se debe utilizar STP.
Aunque las características de ancho de banda de la cinta magnética son excelentes, las características de retardo son pobres. El tiempo de transmisión se mide en minutos u horas, no en milisegundos. Para muchas aplicaciones se necesita una conexión en línea. Uno de los medios de transmisión más antiguos y todavía el más común es el par trenzado.
Par trenzado
Un par trenzado consta de dos cables de cobre aislados, por lo general de 1 mm de grosor. Los cables están trenzados en forma helicoidal, justo igual que una molécula de ADN. El trenzado se debe a que dos cables paralelos constituyen una antena simple. Cuando se trenzan los cables, las ondas de distintos trenzados se cancelan y el cable irradia con menos efectividad. Por lo general una señal se transmite como la diferencia en el voltaje entre los dos cables en el par. Esto ofrece una mejor inmunidad al ruido externo, ya que éste tiende a afectar ambos cables en la misma proporción y en consecuencia, el diferencial queda sin modificación.
La aplicación más común del par trenzado es el sistema telefónico. Casi todos los teléfonos se conectan a la central telefónica mediante un par trenzado. Tanto las llamadas telefónicas como el acceso ADSL a Internet se llevan a cabo mediante estas líneas. Se pueden tender varios kilómetros de par trenzado sin necesidad de amplificación, pero en distancias mayores la señal se atenúa demasiado y se requieren repetidores. Cuando muchos pares trenzados se tienden en paralelo a una distancia considerable, como los cables que van de un edificio de apartamentos a la central telefónica, se agrupan en un haz y se cubren con una funda protectora. Los pares en estos haces interferirían unos con otros si no estuvieran trenzados. En algunas partes del mundo en donde las líneas telefónicas penden de postes sobre la tierra, es común ver haces de varios centímetros de diámetro.
Los pares trenzados se pueden usar para transmitir la información analógica o digital. El ancho de banda depende del grosor del cable y de la distancia que recorre, pero en muchos casos se pueden lograr varios mega bits/seg durante pocos kilómetros. Debido a su adecuado desempeño y bajo costo, los pares trenzados se utilizan mucho y es probable que se sigan utilizando durante varios años más. Existen diversos tipos de cableado de par trenzado. El que se utiliza con mayor frecuencia en muchos edificios de oficinas se llama cable de categoría 5, o “cat 5”. Un par trenzado de categoría 5 consta de dos cables aislados que se trenzan de manera delicada. Por lo general se agrupan cuatro de esos pares en una funda de plástico para protegerlos y mantenerlos juntos.
 Los enlaces que se pueden utilizar en ambas direcciones al mismo tiempo, como un camino con dos carriles, se llaman enlaces full-dúplex. En contraste, los enlaces que se pueden utilizar en cualquier dirección, pero sólo una a la vez, como una vía de ferrocarril de un solo sentido, se llaman enlaces half-dúplex. Hay una tercera categoría que consiste en enlaces que permiten tráfico sólo en una dirección, como una calle de un solo sentido. A éstos se les conoce como enlaces simplex.
Los enlaces que se pueden utilizar en ambas direcciones al mismo tiempo, como un camino con dos carriles, se llaman enlaces full-dúplex. En contraste, los enlaces que se pueden utilizar en cualquier dirección, pero sólo una a la vez, como una vía de ferrocarril de un solo sentido, se llaman enlaces half-dúplex. Hay una tercera categoría que consiste en enlaces que permiten tráfico sólo en una dirección, como una calle de un solo sentido. A éstos se les conoce como enlaces simplex.
A los tipos de cables hasta la categoría 6 se les conoce como UTP (Par Trenzado sin Blindaje, del inglés Unshielded Twisted Pair), ya que están constituidos tan sólo de alambres y aislantes. En contraste, los cables de categoría 7 tienen blindaje en cada uno de los pares trenzados por separado, así como alrededor de todo el cable (pero dentro de la funda protectora de plástico). El blindaje reduce la susceptibilidad a interferencias externas y la diafonía con otros cables cercanos para cumplir con las especificaciones más exigentes de rendimiento. Estos cables son parecidos a los de par trenzado con blindaje de alta calidad pero voluminosos y costosos, que IBM introdujo a principios de la década de 1980, pero que nunca fueron populares fuera de las instalaciones de IBM.
Cable coaxial
El cable coaxial es otro medio de transmisión común. Este cable tiene mejor blindaje y mayor ancho de banda que los pares trenzados sin blindaje, por lo que puede abarcar mayores distancias a velocidades más altas. Hay dos tipos de cable coaxial que se utilizan ampliamente. El de 50 ohms es uno de ellos y se utiliza por lo general cuando se tiene pensado emplear una transmisión digital desde el inicio. El otro tipo es el de 75 ohms y se utiliza para la transmisión analógica y la televisión por cable. Esta distinción se basa en factores históricos más que técnicos.
Un cable coaxial consiste en alambre de cobre rígido como núcleo, rodeado por un material aislante. El aislante está forrado de un conductor cilíndrico, que por lo general es una malla de tejido fuertemente trenzado. El conductor externo está cubierto con una funda protectora de plástico.
 Gracias a su construcción y blindaje, el cable coaxial tiene una buena combinación de un alto ancho de banda y una excelente inmunidad al ruido. El ancho de banda posible depende de la calidad y la longitud del cable. Los cables modernos tienen un ancho de banda de hasta unos cuantos GHz. Los cables coaxiales solían utilizarse mucho dentro del sistema telefónico para las líneas de larga distancia, pero ahora se reemplazaron en su mayoría por fibra óptica en las rutas de largo recorrido. Sin embargo, el cable coaxial se sigue utilizando mucho para la televisión por cable y las redes de área metropolitana.
Gracias a su construcción y blindaje, el cable coaxial tiene una buena combinación de un alto ancho de banda y una excelente inmunidad al ruido. El ancho de banda posible depende de la calidad y la longitud del cable. Los cables modernos tienen un ancho de banda de hasta unos cuantos GHz. Los cables coaxiales solían utilizarse mucho dentro del sistema telefónico para las líneas de larga distancia, pero ahora se reemplazaron en su mayoría por fibra óptica en las rutas de largo recorrido. Sin embargo, el cable coaxial se sigue utilizando mucho para la televisión por cable y las redes de área metropolitana.
El cable de par trenzado es el más utilizado en redes de área local. Es relativamente fácil trabajarlo, flexible, eficiente y rápido. Como administrador de red, debería saber cómo identificar los diferentes tipos de cableado de par trenzado, así como instalar cableado de par trenzado de forma temporal y permanente. Es importante saber como probar los cables de par trenzado en caso de alguna falla o para probar que las nuevas instalaciones trabajan apropiadamente.
Un solo par trenzado tiene ochos cables o hilos, los cuales son conductores de cobre que transmiten señales eléctricas. Los cables están agrupados en cuatro pares: azul, naranja, verde y café. Cada par de cables está trenzado a lo largo de todo el cable. La razón por la que los cables están trenzados es para reducir la diafonía e interferencia.

Generalmente, Ethernet transmite señales de datos en los cables naranja y verde, es decir, en los pines uno, dos, tres y seis. Otras tecnologías utilizan diferentes pares o posiblemente los cuatro pares de cables. Regularmente, las redes de par trenzado están cableadas con el estándar 568B. Esto significa que codo el equipo de cableado debe cumplir con el estándar 568B, incluyendo los paneles de conexión, enchufes RJ45, cables de conexión y la terminación de cableado a cada uno de esos dispositivos.
La interferencia puede ser un problema real con las redes de par trenzado o cualquier otro cipo de red. La interferencia es cualquier cosa que interrumpa o modifique una señal que va viajando a través de un cable. Hay muchos tipos de interferencia, pero sólo hay algunas que debería conocer para el examen, incluyendo los siguientes:
- Interferencia Electromagnética (EMJ): esta es una perturbación que puede afectar circuitos eléctricos, dispositivos y cables, debido a la conducción electromagnética y posible radiación. Casi cualquier tipo de dispositivo eléctrico causa E.Ml: TV, unidades de aire acondicionado, motores, cables eléctricos sin blindaje (Romex),etc. Los cables de cobre y los dispositivos de red deberían mantenerse alejados de esos dispositivos eléctricos y cables. Si esto no es posible, se pueden utilizar cables blindados, por ejemplo cables de par trezado blindados (STP). Los cables STP tienen un blindaje de aluminio dentro de la envoltura de plástico que rodea los pares de cables. Otra opción es que el dispositivo que emana EMI esté blindado. Por ejemplo, una unidad de aire acondicionado podría encajonarse con un blindaje de aluminio para tratar de contener la EMI generada por el motor de la unidad de AC a lo más mínimo. Además, los cables eléctricos deberían ser BX (encerrados en mera!) y no Romex (no encerrados en mera!); de hecho, en muchas parees del mundo se deben cumplir con estas especificaciones en los edificios de construcción.
- interferencia de Frecuencia de Radio (RFI): es ta interferencia se puede originar a partir de transmisiones AM/FM y corres de teléfono de celulares. A menudo es considerado como paree de la familia EMI y es algunas veces referenciado como EMI. Mientras más cerca esté la locación de una de estas corres, la posibilidad de interferencia es mayor. Los métodos mencionados en el aparrado EMI se pueden emplear para evitar las RFJ. Además, se pueden instalar filtros en la red para eliminar las frecuencias de señal que se transmitan por una torre de radio, aunque estas generalmente no afectan a las redes alámbricas Ethernet estándar.
Otro tipo común de interferencia es la diafonía. La diafonía es cuando la señal que es transmitida en cable de cobre o par de cables crea un efecto indeseado en otro cable o par de cables. Esto ocurre cuando las líneas de teléfono se ubican muy cerca una de la otra. Debido a que las líneas están demasiado cerca, la señal podría saltar de una línea a la otra de manera intermitente. Si alguna vez ha escuchado otra conversación mientras habla por teléfono en su hogar (y no de un teléfono celular), entonces ha sido víctima de la diafonía.
Cuando se trata de cableado de par trenzado, la diafonía se divide en dos categorías: Paradiafonía (NEXT) y telediafimía (FEXT). La NEXT ocurre cuando hay una interferencia medida entre dos pares en un solo cable, medida en el extremo del cable más cercano al transmisor. La FEXT ocurre cuando hay una interferencia similar, medida en el extremo del cable más lejano al transmisor. Si la diafonía es un problema, a pesar de emplearse cable de par trenzado e implementarse las transmisiones de datos digitales, se puede utilizar cable par trenzado blindado (STP). Normalmente, las compañías optan por cableado de par trenzado regular, el cual es par trenzado sin blindaje (también conocido como UTP), pero algunas veces, hay demasiada interferencia en el ambiente para enviar información efectivamente y se debe utilizar STP.
Aunque las características de ancho de banda de la cinta magnética son excelentes, las características de retardo son pobres. El tiempo de transmisión se mide en minutos u horas, no en milisegundos. Para muchas aplicaciones se necesita una conexión en línea. Uno de los medios de transmisión más antiguos y todavía el más común es el par trenzado.
Par trenzado
Un par trenzado consta de dos cables de cobre aislados, por lo general de 1 mm de grosor. Los cables están trenzados en forma helicoidal, justo igual que una molécula de ADN. El trenzado se debe a que dos cables paralelos constituyen una antena simple. Cuando se trenzan los cables, las ondas de distintos trenzados se cancelan y el cable irradia con menos efectividad. Por lo general una señal se transmite como la diferencia en el voltaje entre los dos cables en el par. Esto ofrece una mejor inmunidad al ruido externo, ya que éste tiende a afectar ambos cables en la misma proporción y en consecuencia, el diferencial queda sin modificación.
La aplicación más común del par trenzado es el sistema telefónico. Casi todos los teléfonos se conectan a la central telefónica mediante un par trenzado. Tanto las llamadas telefónicas como el acceso ADSL a Internet se llevan a cabo mediante estas líneas. Se pueden tender varios kilómetros de par trenzado sin necesidad de amplificación, pero en distancias mayores la señal se atenúa demasiado y se requieren repetidores. Cuando muchos pares trenzados se tienden en paralelo a una distancia considerable, como los cables que van de un edificio de apartamentos a la central telefónica, se agrupan en un haz y se cubren con una funda protectora. Los pares en estos haces interferirían unos con otros si no estuvieran trenzados. En algunas partes del mundo en donde las líneas telefónicas penden de postes sobre la tierra, es común ver haces de varios centímetros de diámetro.
Los pares trenzados se pueden usar para transmitir la información analógica o digital. El ancho de banda depende del grosor del cable y de la distancia que recorre, pero en muchos casos se pueden lograr varios mega bits/seg durante pocos kilómetros. Debido a su adecuado desempeño y bajo costo, los pares trenzados se utilizan mucho y es probable que se sigan utilizando durante varios años más. Existen diversos tipos de cableado de par trenzado. El que se utiliza con mayor frecuencia en muchos edificios de oficinas se llama cable de categoría 5, o “cat 5”. Un par trenzado de categoría 5 consta de dos cables aislados que se trenzan de manera delicada. Por lo general se agrupan cuatro de esos pares en una funda de plástico para protegerlos y mantenerlos juntos.
A los tipos de cables hasta la categoría 6 se les conoce como UTP (Par Trenzado sin Blindaje, del inglés Unshielded Twisted Pair), ya que están constituidos tan sólo de alambres y aislantes. En contraste, los cables de categoría 7 tienen blindaje en cada uno de los pares trenzados por separado, así como alrededor de todo el cable (pero dentro de la funda protectora de plástico). El blindaje reduce la susceptibilidad a interferencias externas y la diafonía con otros cables cercanos para cumplir con las especificaciones más exigentes de rendimiento. Estos cables son parecidos a los de par trenzado con blindaje de alta calidad pero voluminosos y costosos, que IBM introdujo a principios de la década de 1980, pero que nunca fueron populares fuera de las instalaciones de IBM.
Cable coaxial
El cable coaxial es otro medio de transmisión común. Este cable tiene mejor blindaje y mayor ancho de banda que los pares trenzados sin blindaje, por lo que puede abarcar mayores distancias a velocidades más altas. Hay dos tipos de cable coaxial que se utilizan ampliamente. El de 50 ohms es uno de ellos y se utiliza por lo general cuando se tiene pensado emplear una transmisión digital desde el inicio. El otro tipo es el de 75 ohms y se utiliza para la transmisión analógica y la televisión por cable. Esta distinción se basa en factores históricos más que técnicos.
Un cable coaxial consiste en alambre de cobre rígido como núcleo, rodeado por un material aislante. El aislante está forrado de un conductor cilíndrico, que por lo general es una malla de tejido fuertemente trenzado. El conductor externo está cubierto con una funda protectora de plástico.
6.1.2) Identificar y trabajar con cable de fibra óptica
En la carrera continua entre la computación y la comunicación, tal vez gane la comunicación debido a las redes de fibra óptica. La implicación de esto sería en esencia un ancho de banda infinito y un nuevo acuerdo convencional para establecer que las computadoras son irremediablemente lentas, de modo que las redes deben tratar de evitar las tareas de cómputo a toda costa, sin importar qué tanto ancho de banda se desperdicie. Este cambio tardará un tiempo en penetrar en una generación de científicos e ingenieros en computación acostumbrados a pensar en términos de los bajos límites de Shannon impuestos por el cobre.
La fibra óptica se utiliza para la transmisión de larga distancia en las redes troncales, las redes LAN de alta velocidad (aunque hasta ahora el cobre siempre ha logrado ponerse a la par) y el acceso a Internet de alta velocidad como FTTH (Fibra para el Hogar, Fiber To The Home). Un sistema de transmisión óptico tiene tres componentes clave: la fuente de luz, el medio de transmisión y el detector. Por convención, un pulso de luz indica un bit 1 y la ausencia de luz indica un bit 0. El medio de transmisión es una fibra de vidrio ultra delgada. El detector genera un pulso eléctrico cuando la luz incide en él. Al conectar una fuente de luz a un extremo de una fibra óptica y un detector al otro extremo, tenemos un sistema de transmisión de datos unidireccional que acepta una señal eléctrica, la convierte y la transmite mediante pulsos de luz, y después reconvierte la salida a una señal eléctrica en el extremo receptor. Este sistema de transmisión tendría fugas de luz y sería inútil en la práctica si no fuera por un interesante principio de la física. Cuando un rayo de luz pasa de un medio a otro (por ejemplo, de sílice fundida al aire), el rayo se refracta (dobla) en el límite la sílice y el aire.
Aquí vemos un rayo de luz que incide en el límite a un ángulo α1 que emerge con un ángulo β1. El grado de refracción depende de las propiedades de los dos medios (en especial, de sus índices de refracción). Para ángulos de incidencia por encima de cierto valor crítico, la luz se refracta de regreso a la sílice; nada de ella escapa al aire. Se dice que cada rayo tiene un modo distinto, por lo que una fibra con esta propiedad se llama fibra multimodal.
Pero si el diámetro de la fibra se reduce a unas cuantas longitudes de onda de luz, la fibra actúa como una guía de ondas y la luz se puede propagar sólo en línea recta, sin rebotar, con lo que se obtiene una fibra monomodo. Estas fibras son más costosas pero se utilizan mucho para distancias más largas. Las fibras monomodo disponibles en la actualidad pueden transmitir datos a 100 Gbps por 100 km sin necesidad de amplificación. Incluso se han logrado tasas de datos más altas en el laboratorio, para distancias más cortas.
Transmisión de luz a través de fibras
Las fibras ópticas están hechas de vidrio, que a su vez se fabrica a partir de la arena, una materia prima de bajo costo disponible en cantidades ilimitadas. La fabricación del vidrio era conocida por los antiguos egipcios, pero su vidrio no podía ser mayor de 1 mm de grosor para que la luz pudiera atravesarlo. Durante el Renacimiento se desarrolló un vidrio lo bastante transparente como para usarlo en las ventanas. El vidrio utilizado para las fibras ópticas modernas es tan transparente que si los océanos estuvieran llenos de él en vez de agua, el lecho marino sería tan visible desde la superficie como lo es el suelo desde un avión en un día claro.
La atenuación de la luz que pasa por el vidrio depende de la longitud de onda de la luz (así como de algunas propiedades físicas del vidrio). Se define como la relación entre la potencia de la señal de entrada y la de salida. Para el tipo de vidrio que se utiliza en las fibras ópticas.
La longitud de los pulsos de luz que se transmiten por una fibra aumenta conforme se propagan. A este fenómeno se le conoce como dispersión cromática. Su magnitud depende de la longitud de onda. Una forma de evitar que se traslapen estos pulsos dispersos es aumentar la distancia entre ellos, pero esto se puede hacer sólo si se reduce la tasa de transmisión. Por fortuna se descubrió que si se da a los pulsos una forma especial relacionada con el recíproco del coseno hiperbólico, se cancelan casi todos los efectos de la dispersión y es posible enviar pulsos a miles de kilómetros sin una distorsión apreciable de la forma. Estos pulsos se llaman solitones. Se está realizando una cantidad considerable de investigaciones para sacar los solitones del laboratorio y llevarlos al campo.
Cables de fibras
Los cables de fibra óptica son similares a los coaxiales, excepto por el trenzado. En la figura 2-8(a) aparece una fibra óptica individual, vista de lado. Al centro se encuentra el núcleo de vidrio, a través del cual se propaga la luz. En las fibras multimodales, el núcleo es por lo general de 50 micras de diámetro, aproximadamente el grosor de un cabello humano. En las fibras de monomodo, el núcleo es de 8 a 10 micras.

El núcleo está rodeado de un revestimiento de vidrio con un índice de refracción más bajo que el del núcleo, con el fin de mantener toda la luz en el núcleo. Después viene una cubierta delgada de plástico para proteger el revestimiento. Por lo general las fibras se agrupan en haces, protegidas por una funda exterior.
Por lo general, las fundas de fibras terrestres se colocan un metro debajo de la superficie, en donde en ocasiones están sujetas a los ataques de retroexcavadoras o topos. Cerca de la costa, las fundas de fibras transoceánicas se entierran en zanjas mediante una especie de arado marino. En aguas profundas, simplemente
se colocan en el fondo, donde pueden ser enganchadas por pesqueros o atacadas por un calamar gigante.
Las fibras se pueden conectar de tres maneras distintas. Primera, pueden terminar en conectores e insertarse en clavijas de fibra. Los conectores pierden entre un 10 y 20% de la luz, pero facilitan la reconfiguración de los sistemas.
Segunda, se pueden empalmar en forma mecánica. Los empalmes mecánicos simplemente acomodan los dos extremos cortados con cuidado, uno junto a otro en una manga especial y los sujetan en su lugar. Para mejorar la alineación se puede pasar luz a través de la unión para después realizar pequeños ajustes de modo que se maximice la señal. El personal capacitado tarda cerca de cinco minutos en crear empalmes mecánicos y se produce una pérdida de luz de 10%.
Tercera, se pueden fusionar (fundir) dos piezas de fibra para formar una conexión sólida. Un empalme por fusión es casi tan bueno como una sola fibra, pero incluso en este caso se produce una pequeña cantidad de atenuación.
En los tres tipos de empalmes se pueden producir reflejos en el punto del empalme; además la energía reflejada puede interferir con la señal. Por lo general se utilizan dos tipos de fuentes de luz para producir las señales: LED (Diodos Emisores de Luz, del inglés Light Emitting Diodes) y láseres semiconductores. Estas fuentes de luz tienen distintas propiedades.
Se pueden optimizar en cuanto a la longitud de onda, para lo cual se insertan interferómetros Fabry-Perot o Mach-Zehnder entre la fuente y la fibra. Los interferómetros Fabry-Perot son simples cavidades resonantes que consisten en dos espejos paralelos. La luz incide en los espejos en forma perpendicular. La longitud de la cavidad separa las longitudes de onda que caben dentro de un número entero de veces. Los interferómetros Mach-Zehnder separan la luz en dos haces, los cuales viajan distancias ligeramente distintas. Se vuelven a combinar en el extremo y están en fase sólo para ciertas longitudes de onda.
El extremo receptor de una fibra óptica consiste en un fotodiodo, el cual emite un pulso eléctrico cuando lo golpea la luz. El tiempo de respuesta de los fotodiodos, que convierten la señal óptica en eléctrica, limita la tasa de datos a cerca de 100 Gbps. El ruido térmico es otro inconveniente, por lo que un pulso de luz debe llevar suficiente potencia para detectarlo. Cuando los pulsos tienen la potencia suficiente, la tasa de error se puede reducir de manera considerable.
En la carrera continua entre la computación y la comunicación, tal vez gane la comunicación debido a las redes de fibra óptica. La implicación de esto sería en esencia un ancho de banda infinito y un nuevo acuerdo convencional para establecer que las computadoras son irremediablemente lentas, de modo que las redes deben tratar de evitar las tareas de cómputo a toda costa, sin importar qué tanto ancho de banda se desperdicie. Este cambio tardará un tiempo en penetrar en una generación de científicos e ingenieros en computación acostumbrados a pensar en términos de los bajos límites de Shannon impuestos por el cobre.
La fibra óptica se utiliza para la transmisión de larga distancia en las redes troncales, las redes LAN de alta velocidad (aunque hasta ahora el cobre siempre ha logrado ponerse a la par) y el acceso a Internet de alta velocidad como FTTH (Fibra para el Hogar, Fiber To The Home). Un sistema de transmisión óptico tiene tres componentes clave: la fuente de luz, el medio de transmisión y el detector. Por convención, un pulso de luz indica un bit 1 y la ausencia de luz indica un bit 0. El medio de transmisión es una fibra de vidrio ultra delgada. El detector genera un pulso eléctrico cuando la luz incide en él. Al conectar una fuente de luz a un extremo de una fibra óptica y un detector al otro extremo, tenemos un sistema de transmisión de datos unidireccional que acepta una señal eléctrica, la convierte y la transmite mediante pulsos de luz, y después reconvierte la salida a una señal eléctrica en el extremo receptor. Este sistema de transmisión tendría fugas de luz y sería inútil en la práctica si no fuera por un interesante principio de la física. Cuando un rayo de luz pasa de un medio a otro (por ejemplo, de sílice fundida al aire), el rayo se refracta (dobla) en el límite la sílice y el aire.
Aquí vemos un rayo de luz que incide en el límite a un ángulo α1 que emerge con un ángulo β1. El grado de refracción depende de las propiedades de los dos medios (en especial, de sus índices de refracción). Para ángulos de incidencia por encima de cierto valor crítico, la luz se refracta de regreso a la sílice; nada de ella escapa al aire. Se dice que cada rayo tiene un modo distinto, por lo que una fibra con esta propiedad se llama fibra multimodal.
Pero si el diámetro de la fibra se reduce a unas cuantas longitudes de onda de luz, la fibra actúa como una guía de ondas y la luz se puede propagar sólo en línea recta, sin rebotar, con lo que se obtiene una fibra monomodo. Estas fibras son más costosas pero se utilizan mucho para distancias más largas. Las fibras monomodo disponibles en la actualidad pueden transmitir datos a 100 Gbps por 100 km sin necesidad de amplificación. Incluso se han logrado tasas de datos más altas en el laboratorio, para distancias más cortas.
Transmisión de luz a través de fibras
Las fibras ópticas están hechas de vidrio, que a su vez se fabrica a partir de la arena, una materia prima de bajo costo disponible en cantidades ilimitadas. La fabricación del vidrio era conocida por los antiguos egipcios, pero su vidrio no podía ser mayor de 1 mm de grosor para que la luz pudiera atravesarlo. Durante el Renacimiento se desarrolló un vidrio lo bastante transparente como para usarlo en las ventanas. El vidrio utilizado para las fibras ópticas modernas es tan transparente que si los océanos estuvieran llenos de él en vez de agua, el lecho marino sería tan visible desde la superficie como lo es el suelo desde un avión en un día claro.
La atenuación de la luz que pasa por el vidrio depende de la longitud de onda de la luz (así como de algunas propiedades físicas del vidrio). Se define como la relación entre la potencia de la señal de entrada y la de salida. Para el tipo de vidrio que se utiliza en las fibras ópticas.
La longitud de los pulsos de luz que se transmiten por una fibra aumenta conforme se propagan. A este fenómeno se le conoce como dispersión cromática. Su magnitud depende de la longitud de onda. Una forma de evitar que se traslapen estos pulsos dispersos es aumentar la distancia entre ellos, pero esto se puede hacer sólo si se reduce la tasa de transmisión. Por fortuna se descubrió que si se da a los pulsos una forma especial relacionada con el recíproco del coseno hiperbólico, se cancelan casi todos los efectos de la dispersión y es posible enviar pulsos a miles de kilómetros sin una distorsión apreciable de la forma. Estos pulsos se llaman solitones. Se está realizando una cantidad considerable de investigaciones para sacar los solitones del laboratorio y llevarlos al campo.
Cables de fibras
Los cables de fibra óptica son similares a los coaxiales, excepto por el trenzado. En la figura 2-8(a) aparece una fibra óptica individual, vista de lado. Al centro se encuentra el núcleo de vidrio, a través del cual se propaga la luz. En las fibras multimodales, el núcleo es por lo general de 50 micras de diámetro, aproximadamente el grosor de un cabello humano. En las fibras de monomodo, el núcleo es de 8 a 10 micras.

a) Vista lateral de una sola fibra. b) Vista de extremo de una envoltura con tres fibras
El núcleo está rodeado de un revestimiento de vidrio con un índice de refracción más bajo que el del núcleo, con el fin de mantener toda la luz en el núcleo. Después viene una cubierta delgada de plástico para proteger el revestimiento. Por lo general las fibras se agrupan en haces, protegidas por una funda exterior.
Por lo general, las fundas de fibras terrestres se colocan un metro debajo de la superficie, en donde en ocasiones están sujetas a los ataques de retroexcavadoras o topos. Cerca de la costa, las fundas de fibras transoceánicas se entierran en zanjas mediante una especie de arado marino. En aguas profundas, simplemente
se colocan en el fondo, donde pueden ser enganchadas por pesqueros o atacadas por un calamar gigante.
Las fibras se pueden conectar de tres maneras distintas. Primera, pueden terminar en conectores e insertarse en clavijas de fibra. Los conectores pierden entre un 10 y 20% de la luz, pero facilitan la reconfiguración de los sistemas.
Segunda, se pueden empalmar en forma mecánica. Los empalmes mecánicos simplemente acomodan los dos extremos cortados con cuidado, uno junto a otro en una manga especial y los sujetan en su lugar. Para mejorar la alineación se puede pasar luz a través de la unión para después realizar pequeños ajustes de modo que se maximice la señal. El personal capacitado tarda cerca de cinco minutos en crear empalmes mecánicos y se produce una pérdida de luz de 10%.
Tercera, se pueden fusionar (fundir) dos piezas de fibra para formar una conexión sólida. Un empalme por fusión es casi tan bueno como una sola fibra, pero incluso en este caso se produce una pequeña cantidad de atenuación.
En los tres tipos de empalmes se pueden producir reflejos en el punto del empalme; además la energía reflejada puede interferir con la señal. Por lo general se utilizan dos tipos de fuentes de luz para producir las señales: LED (Diodos Emisores de Luz, del inglés Light Emitting Diodes) y láseres semiconductores. Estas fuentes de luz tienen distintas propiedades.
Se pueden optimizar en cuanto a la longitud de onda, para lo cual se insertan interferómetros Fabry-Perot o Mach-Zehnder entre la fuente y la fibra. Los interferómetros Fabry-Perot son simples cavidades resonantes que consisten en dos espejos paralelos. La luz incide en los espejos en forma perpendicular. La longitud de la cavidad separa las longitudes de onda que caben dentro de un número entero de veces. Los interferómetros Mach-Zehnder separan la luz en dos haces, los cuales viajan distancias ligeramente distintas. Se vuelven a combinar en el extremo y están en fase sólo para ciertas longitudes de onda.
El extremo receptor de una fibra óptica consiste en un fotodiodo, el cual emite un pulso eléctrico cuando lo golpea la luz. El tiempo de respuesta de los fotodiodos, que convierten la señal óptica en eléctrica, limita la tasa de datos a cerca de 100 Gbps. El ruido térmico es otro inconveniente, por lo que un pulso de luz debe llevar suficiente potencia para detectarlo. Cuando los pulsos tienen la potencia suficiente, la tasa de error se puede reducir de manera considerable.
6.2) Redes inalambricas
Nuestra Era ha dado origen a los adictos a la información: personas que necesitan estar todo el tiempo en línea. Para estos usuarios móviles no son de utilidad el par trenzado, el cable coaxial ni la fibra óptica. Necesitan obtener datos para sus computadoras laptop, notebook, de bolsillo, de mano o de reloj de pulsera sin tener que estar atados a la infraestructura de comunicación terrestre. Para estos usuarios, la comunicación inalámbrica es la respuesta.
Nuestra Era ha dado origen a los adictos a la información: personas que necesitan estar todo el tiempo en línea. Para estos usuarios móviles no son de utilidad el par trenzado, el cable coaxial ni la fibra óptica. Necesitan obtener datos para sus computadoras laptop, notebook, de bolsillo, de mano o de reloj de pulsera sin tener que estar atados a la infraestructura de comunicación terrestre. Para estos usuarios, la comunicación inalámbrica es la respuesta.
6.2.1) Dispositivos inalámbricos
Los dispositivos inalámbricos pueden permitir la conectividad central de computadoras cliente y dispositivos portátiles, o pueden ofrecer una extensión de conectividad a una red inalámbrica preexistente y se podría utilizar para conectar redes de área local enteras a Internet. Además, algunos dispositivos inalámbricos se pueden conectar directamente entre si de manera punto a punto.
Por mucho, el dispositivo inalámbrico más conocido es el punto de acceso inalámbrico o WAP. Este dispositivo a menudo actúa como un router, firewall y proxy lP. Permite la conectividad de diferentes dispositivos inalámbricos tales como laptops, PDAs, computadoras portátiles, ere. Lo hace realizando conexiones vía ondas de radio en frecuencias específicas. Las computadoras cliente y dispositivos portátiles deben utilizar la misma frecuencia con el fin de conectase al WAP. En el siguiente ejercicio, identificaremos puntos de acceso inalámbrico, adaptadores de red inalámbricos, así como puentes y repetidores inalámbricos.
Los dispositivos inalámbricos pueden permitir la conectividad central de computadoras cliente y dispositivos portátiles, o pueden ofrecer una extensión de conectividad a una red inalámbrica preexistente y se podría utilizar para conectar redes de área local enteras a Internet. Además, algunos dispositivos inalámbricos se pueden conectar directamente entre si de manera punto a punto.
Por mucho, el dispositivo inalámbrico más conocido es el punto de acceso inalámbrico o WAP. Este dispositivo a menudo actúa como un router, firewall y proxy lP. Permite la conectividad de diferentes dispositivos inalámbricos tales como laptops, PDAs, computadoras portátiles, ere. Lo hace realizando conexiones vía ondas de radio en frecuencias específicas. Las computadoras cliente y dispositivos portátiles deben utilizar la misma frecuencia con el fin de conectase al WAP. En el siguiente ejercicio, identificaremos puntos de acceso inalámbrico, adaptadores de red inalámbricos, así como puentes y repetidores inalámbricos.
6.2.2) Estándares de redes inalámbricas
Con el fin de configurar una LAN inalámbrica funcional, un administrador de red tiene que conocer varios estándares inalámbricos, así como también las formas de asegurar las transmisiones de red inalámbricas.
Una LAN lnalámbrica o WLAN es una red compuesta por, al menos, un WAP y una computadora o dispositivo portátil que pueda conectarse al WAP. Por lo general, estas redes están basadas en Ethernet, pero pueden estar basadas en otras arquitecturas de red. Con el !in de asegurar la compatibilidad, el WAP y otros dispositivos inalámbricos deben utilizar el mismo estándar WLAN IEEE 802.11. A estos estándares se les refiere colectivamente como 802.11x (no confundir con 802.1 X) y están definidos por la capa de enlace de datos del modelo OSI. El término "WLAN'' es a menudo utilizado intercambiablemente con el término Wi-Fi. Sin embargo, \.'f/i-Fi se refiere a una marca creada por la Wi-Fi Alliance. Los productos y tecnologías Wi-Fi están basados en estándares de WLAN. Estos estándares WLAN dictan la frecuencia {o frecuencias) utilizadas, velocidad, etc.
En los Estados Unidos, 802.11b y g tienen 11 canales utilizables, empezando con el canal 1 centrado a 2.412 GHz y terminando con el canal ll centrado a 2.462 GHz. Este es un rango pequeño en comparación con los que utilizan otros países.
Muchos canales en una WLAN se solapan. Para evitar esto, las organizaciones podrían poner, por ejemplo, eres WAPs separadas en los canales 1,6 y 11, respectivamente. Esto evita que se solapen e interfieran entre sí. Si dos WAPs en los canales 4 y 5 están muy cerca entre sí, habrá cierta cantidad de interferencia. También es sabio mantener las WAPs de la WLAN lejos de dispositivos Bluetooth y puntos de acceso de Bluetooth, ya que este también utiliza el rango de frecuencia de 2.4 GHz.
No hace falca decir que la compatibilidad es clave. Sin embargo, muchas WAPs son retrocompatibles. Por ejemplo. Un WAP 802.11g podría también permitir conexiones 802.11b e inclusive conexiones 802.11a, lo que sería un ejemplo de un puente inalámbrico.
Con el fin de configurar una LAN inalámbrica funcional, un administrador de red tiene que conocer varios estándares inalámbricos, así como también las formas de asegurar las transmisiones de red inalámbricas.
Una LAN lnalámbrica o WLAN es una red compuesta por, al menos, un WAP y una computadora o dispositivo portátil que pueda conectarse al WAP. Por lo general, estas redes están basadas en Ethernet, pero pueden estar basadas en otras arquitecturas de red. Con el !in de asegurar la compatibilidad, el WAP y otros dispositivos inalámbricos deben utilizar el mismo estándar WLAN IEEE 802.11. A estos estándares se les refiere colectivamente como 802.11x (no confundir con 802.1 X) y están definidos por la capa de enlace de datos del modelo OSI. El término "WLAN'' es a menudo utilizado intercambiablemente con el término Wi-Fi. Sin embargo, \.'f/i-Fi se refiere a una marca creada por la Wi-Fi Alliance. Los productos y tecnologías Wi-Fi están basados en estándares de WLAN. Estos estándares WLAN dictan la frecuencia {o frecuencias) utilizadas, velocidad, etc.
En los Estados Unidos, 802.11b y g tienen 11 canales utilizables, empezando con el canal 1 centrado a 2.412 GHz y terminando con el canal ll centrado a 2.462 GHz. Este es un rango pequeño en comparación con los que utilizan otros países.
Muchos canales en una WLAN se solapan. Para evitar esto, las organizaciones podrían poner, por ejemplo, eres WAPs separadas en los canales 1,6 y 11, respectivamente. Esto evita que se solapen e interfieran entre sí. Si dos WAPs en los canales 4 y 5 están muy cerca entre sí, habrá cierta cantidad de interferencia. También es sabio mantener las WAPs de la WLAN lejos de dispositivos Bluetooth y puntos de acceso de Bluetooth, ya que este también utiliza el rango de frecuencia de 2.4 GHz.
No hace falca decir que la compatibilidad es clave. Sin embargo, muchas WAPs son retrocompatibles. Por ejemplo. Un WAP 802.11g podría también permitir conexiones 802.11b e inclusive conexiones 802.11a, lo que sería un ejemplo de un puente inalámbrico.
CAPITULO 7. CAPAS
7.1) La capa física
En capítulos anteriores hemos empezado a conocer un poco a las capas, pero en este capitulo estudiaremos esos tipos de capas; en este punto estudiaremos la capa física, la que se podría denominar como la mas baja capa en nuestro modelo de protocolos.
Ésta define las interfaces eléctricas, de temporización y demás interfaces mediante las cuales se envían los bits como señales a través de los canales. La capa física es la base sobre la cual se construye la red.
7.1.1) Bases teóricas para comunicación de datos
Mediante la variación de alguna propiedad física, como el voltaje o la corriente, es posible transmitir información a través de cables. Si representamos el valor de este voltaje o corriente como una función simple del tiempo, f(t), podemos modelar el comportamiento de la señal y analizarlo matemáticamente. Para ello utilizaremos un tipo de análisis matemático conocido como Análisis de Fourier.
A principios del siglo xix, el matemático francés Jean-Baptiste Fourier demostró que cualquier función
periódica de comportamiento razonable, g(t) con un periodo T, se puede construir como la suma de un
número (posiblemente infinito) de senos y cosenos:
 (6.1)
(6.1)



Mediante la variación de alguna propiedad física, como el voltaje o la corriente, es posible transmitir información a través de cables. Si representamos el valor de este voltaje o corriente como una función simple del tiempo, f(t), podemos modelar el comportamiento de la señal y analizarlo matemáticamente. Para ello utilizaremos un tipo de análisis matemático conocido como Análisis de Fourier.
A principios del siglo xix, el matemático francés Jean-Baptiste Fourier demostró que cualquier función
periódica de comportamiento razonable, g(t) con un periodo T, se puede construir como la suma de un
número (posiblemente infinito) de senos y cosenos:
en donde f=1/T es la frecuencia fundamental, an y bn son las amplitudes de seno y coseno del n-esimo armónico (término) y c es una constante. A dicha descomposición se le denomina serie de Fourier. Podemos reconstruir la función a partir de la serie de Fourier. Esto es, si se conoce el periodo T y se dan las amplitudes, podemos encontrar la función original del tiempo realizando las sumas de la ecuación 6.1.
Podemos calcular las amplitudes an para cualquier g(t) si multiplicamos ambos lados de la ecuación (6.1) por sen(2πk ft) y después integramos de 0 a T. Dado que:

sólo sobrevive un término de la sumatoria: an. La sumatoria bn se desvanece por completo. De forma similar, si multiplicamos la ecuación (2-1) por cos(2πk ft) e integramos entre 0 y T, podemos derivar bn. Con sólo integrar ambos lados de la ecuación como está, podemos encontrar c. Los resultados de realizar estas operaciones son:
La relevancia de todo esto para la comunicación de datos es que los canales reales afectan a las distintas señales de frecuencia de manera diferente. Consideremos un ejemplo específico: la transmisión del carácter ASCII “b” codificado en un byte de 8 bits. El patrón de bits que transmitirá es 01100010. La parte izquierda de la figura 2-1(a) muestra la salida de voltaje producido por la computadora transmisora. El análisis de Fourier de esta señal produce los siguientes coeficientes:

Ninguna instalación transmisora puede enviar señales sin perder cierta potencia en el proceso. Si todos los componentes de Fourier disminuyeran en la misma proporción, la señal resultante se reduciría en amplitud pero no se distorsionaría. Por desgracia, todas las instalaciones transmisoras disminuyen los componentes de Fourier en distinto grado y, en consecuencia, introducen distorsión. Por lo general, las amplitudes se transmiten en su mayoría sin ninguna disminución en un cable, desde cero hasta cierta frecuencia fc [se mide en ciclos/segundo o Hertz (Hz)], y se atenúan todas las frecuencias que están por encima de esta frecuencia de corte. El rango de frecuencia que se transmite sin una atenuación considerable se denomina ancho de banda. En la práctica, el corte en realidad no es muy abrupto, por lo que a menudo el ancho de banda referido es desde cero hasta la frecuencia a la que disminuyó la potencia recibida a la mitad.
El ancho de banda es una propiedad física del medio de transmisión que depende; por ejemplo, de la construcción, el grosor y la longitud de un cable o fibra óptica. A menudo se utilizan filtros para limitar el ancho de banda de una señal. Por ejemplo, los canales inalámbricos 802.11 pueden utilizar aproximadamente 20 MHz, por lo que los radios 802.11 filtran el ancho de banda de la señal con base en este tamaño.
Otro ejemplo, los canales de televisión tradicionales (analógicos) ocupan 6 MHz cada uno, en un cable o a través del aire. Este filtrado permite que más señales compartan una región dada de un espectro, lo cual mejora la eficiencia del sistema en general. Lo que significa que el rango de frecuencia para ciertas señales no empezará en cero, pero no importa. El ancho de banda sigue siendo el rango de la banda de frecuencias que se transmiten, y la información que se puede transportar depende sólo de este ancho de banda, no de su frecuencia inicial ni final. Las señales que van desde cero hasta una frecuencia máxima se llaman señales de banda base. Las que se desplazan para ocupar un rango de frecuencias más altas, como es el caso de todas las transmisiones inalámbricas, se llaman señales de pasa-banda.
Una línea telefónica común, a menudo llamada línea con calidad de voz, tiene una frecuencia de corte introducida en forma artificial ligeramente mayor a 3 000 Hz. Esta restricción significa que el número de armónicos más altos que puede pasar es de aproximadamente 3 000/(b/8), o 24 000/b.
Hay mucha confusión en cuanto al ancho de banda, ya que tiene distintos significados para los ingenieros eléctricos y para los científicos de computadoras. Para los ingenieros eléctricos, el ancho de banda (analógico) es (como lo describimos antes) una cantidad que se mide en Hz. Para los científicos de computadora, el ancho de banda (digital) es la tasa de datos máxima de un canal, una cantidad que se mide en bits/segundo. Esa tasa de datos es el resultado final de usar el ancho de banda analógico de un canal físico para transmisión digital, y ambos están relacionados, como veremos a continuación.
En 1924, un ingeniero de AT&T llamado Henry Nyquist se dio cuenta de que incluso un canal perfecto tiene una capacidad de transmisión finita y dedujo una ecuación para expresar la tasa de datos máxima para un canal sin ruido con un ancho de banda finito. En 1948, Claude Shannon retomó el trabajo de Nyquist y lo extendió al caso de un canal sujeto a ruido aleatorio (es decir, termodinámico).
Nyquist demostró que si se pasa una señal cualquiera a través de un filtro pasa-bajas con un ancho de banda B, la señal filtrada se puede reconstruir por completo tomando sólo 2B muestras (exactas) por segundo. No tiene caso muestrear la línea más de 2B veces por segundo, ya que los componentes de mayor frecuencia que dicho muestreo pudiera recuperar ya se han filtrado. Si la señal consiste en V niveles discretos, el teorema de Nyquist establece lo siguiente:
Tasa de datos máxima = 2B log2 V bits/seg
Hasta ahora hemos considerado sólo los canales sin ruido. Si hay ruido aleatorio presente, la situación se deteriora con rapidez. Y siempre hay ruido aleatorio (térmico) presente debido al movimiento de las moléculas en el sistema. La cantidad de ruido térmico presente se mide con base en la relación entre la potencia de la señal y la potencia del ruido; llamada SNR (Relación Señal a Ruido, Signal-to-Noise Ratio).
Si denotamos la potencia de la señal mediante S y la potencia del ruido mediante N, la relación señal a ruido es S/N. Por lo general la relación se expresa en una escala de logaritmo como la cantidad 10 log10 S/N, ya que puede variar sobre un gran rango. Las unidades de esta escala logarítmica se llaman decibeles (dB), en donde “deci” significa 10 y “bel” se eligió en honor a Alexander Graham Bell, inventor del teléfono.
El principal resultado de Shannon es que la tasa de datos máxima (o capacidad) de un canal ruidoso, cuyo ancho de banda es B Hz y cuya relación señal a ruido es S/N, está dada por:
Número máximo de bits/seg = B log2 (1 1 S/N)
Esto nos indica las mejores capacidades que pueden tener los canales reales. Por ejemplo, la ADSL (Línea Asimétrica de Suscriptor Digital) que provee acceso a Internet a través de líneas telefónicas comunes, utiliza un ancho de banda de aproximadamente 1 MHz. La SNR depende en gran parte de la distancia entre el hogar y la central telefónica; una SNR de alrededor de 40 dB para líneas cortas de 1 a 2 km es algo muy bueno.
7.1.2) Medios de transmisión guiados
El propósito de la capa física es transportar bits de una máquina a otra. Se pueden utilizar varios medios físicos para la transmisión real. Cada medio tiene su propio nicho en términos de ancho de banda, retardo, costo y facilidad de instalación y mantenimiento. A grandes rasgos, los medios se agrupan en medios guiados (como el cable de cobre y la fibra óptica) y en medios no guiados (como la transmisión inalámbrica terrestre, los satélites y los láseres a través del aire).
Una de las formas más comunes para transportar datos de una computadora a otra es almacenarlos en cinta magnética o medios removibles (por ejemplo, DVD regrabables), transportar físicamente la cinta o los discos a la máquina de destino y leerlos de nuevo. Aunque este método no es tan sofisticado como usar un satélite de comunicación geosíncrono, a menudo es mucho más rentable, en especial para las aplicaciones en las que el ancho de banda alto o el costo por bit transportado es el factor clave.
Aunque las características de ancho de banda de la cinta magnética son excelentes, las características de retardo son pobres. El tiempo de transmisión se mide en minutos u horas, no en milisegundos. Para muchas aplicaciones se necesita una conexión en línea. Uno de los medios de transmisión más antiguos y todavía el más común es el par trenzado; el cual analizamos con mayor profundidad en el capitulo 6.
El propósito de la capa física es transportar bits de una máquina a otra. Se pueden utilizar varios medios físicos para la transmisión real. Cada medio tiene su propio nicho en términos de ancho de banda, retardo, costo y facilidad de instalación y mantenimiento. A grandes rasgos, los medios se agrupan en medios guiados (como el cable de cobre y la fibra óptica) y en medios no guiados (como la transmisión inalámbrica terrestre, los satélites y los láseres a través del aire).
Una de las formas más comunes para transportar datos de una computadora a otra es almacenarlos en cinta magnética o medios removibles (por ejemplo, DVD regrabables), transportar físicamente la cinta o los discos a la máquina de destino y leerlos de nuevo. Aunque este método no es tan sofisticado como usar un satélite de comunicación geosíncrono, a menudo es mucho más rentable, en especial para las aplicaciones en las que el ancho de banda alto o el costo por bit transportado es el factor clave.
Aunque las características de ancho de banda de la cinta magnética son excelentes, las características de retardo son pobres. El tiempo de transmisión se mide en minutos u horas, no en milisegundos. Para muchas aplicaciones se necesita una conexión en línea. Uno de los medios de transmisión más antiguos y todavía el más común es el par trenzado; el cual analizamos con mayor profundidad en el capitulo 6.
7.1.3) Transmisión inalámbrica
Nuestra Era ha dado origen a los adictos a la información: personas que necesitan estar todo el tiempo en línea. Para estos usuarios móviles no son de utilidad el par trenzado, el cable coaxial ni la fibra óptica. Necesitan obtener datos para sus computadoras laptop, notebook, de bolsillo, de mano o de reloj de pulsera sin tener que estar atados a la infraestructura de comunicación terrestre. Para estos usuarios, la comunicación inalámbrica es la respuesta.
El espectro electromagnético
Cuando los electrones se mueven, crean ondas electromagnéticas que se pueden propagar por el espacio (incluso en el vacío). El físico inglés James Clerk Maxwell predijo estas ondas en 1865 y el físico alemán Heinrich Hertz las observó por primera vez en 1887. El número de oscilaciones por segundo de una onda es su frecuencia, f, y se mide en Hz (en honor de Heinrich Hertz). La distancia entre dos máximos (o mínimos) consecutivos se llama longitud de onda y se designa en forma universal mediante la letra griega λ (lambda).
Al conectar una antena del tamaño apropiado a un circuito eléctrico, las ondas electromagnéticas se pueden difundir de manera eficiente y un receptor las puede captar a cierta distancia. Toda la comunicación inalámbrica se basa en este principio. En el vacío, todas las ondas electromagnéticas viajan a la misma velocidad sin importar cuál sea su frecuencia. Esta velocidad se conoce como velocidad de la luz, c, y es de aproximadamente 3 3 108 m/seg, o alrededor de 1 pie (30 cm) por nanosegundo (podríamos argumentar para redefinir el pie como la distancia que viaja la luz en un vacío por 1 nseg en vez de basarnos en el tamaño del zapato de un rey que murió hace mucho tiempo). En el cobre o la fibra, la velocidad baja a casi 2/3 de este valor y se vuelve ligeramente dependiente de la frecuencia. La velocidad de la luz es el máximo límite de velocidad. Ningún objeto o señal puede llegar a ser más rápido que la luz.
La relación fundamental entre f, λ y c (en el vacío) es: λf = c
Dado que c es una constante, si conocemos el valor f podemos encontrar λ y viceversa. Como regla práctica, cuando λ se da en metros y f en MHz, λf ≈ 300. Por ejemplo, las ondas de 100 MHz tienen una longitud aproximada de 3 metros, las ondas de 1000 MHz tienen una longitud de 0.3 metros y las ondas de 0.1 metros tienen una frecuencia de 3 000 MHz.
Las porciones de radio, microondas, infrarrojo y luz visible del espectro se pueden utilizar para transmitir información mediante la modulación de la amplitud, frecuencia o fase de las ondas. La luz ultravioleta, los rayos X y los rayos gamma serían todavía mejores, debido a sus frecuencias más altas, pero son difíciles de producir y de modular, no se propagan bien entre edificios y son peligrosos para los seres vivos.
La mayoría de las transmisiones utilizan una banda de frecuencia relativamente estrecha. Concentran sus señales en esta banda estrecha para usar el espectro con eficiencia y obtienen tasas de datos razonables al transmitir con suficiente potencia. Pero en algunos casos se utiliza una banda ancha, con tres variaciones. En el espectro disperso con salto de frecuencia, el transmisor salta de frecuencia en frecuencia cientos de veces por segundo. Es popular en la comunicación militar, ya que hace a las transmisiones difíciles de detectar y casi imposibles de bloquear.
Hay una segunda forma de espectro disperso conocida como espectro disperso de secuencia directa, la cual utiliza una secuencia de códigos para dispersar los datos sobre una banda de frecuencia ancha. Su uso comercial es muy popular como una forma espectralmente eficiente de permitir que múltiples señales compartan la misma banda de frecuencia. Estas señales pueden recibir distintos códigos, un método conocido como CDMA (Acceso Múltiple por División de Código, del inglés Code Division Multiple Access) que veremos más adelante en este capítulo.
Un tercer método de comunicación con una banda más ancha es la comunicación UWB (Banda Ultra-Ancha). La UWB envía una serie de pulsos rápidos, los cuales varían sus posiciones para comunicar la información. Las transiciones rápidas conducen a una señal que se dispersa finamente sobre una banda de frecuencia muy amplia. UWB se define como señales que tienen un ancho de banda de por lo menos 500 MHz o de al menos 20% de la frecuencia central de su banda de frecuencia.
Radiotransmisión
Las ondas de radio frecuencia (RF) son fáciles de generar, pueden recorrer distancias largas y penetrar edificios con facilidad, de modo que son muy utilizados en la comunicación, tanto en interiores como en exteriores. Las ondas de radio también son omnidireccionales, lo cual significa que viajan en todas direcciones desde la fuente, por lo que el transmisor y el receptor no tienen que estar alineados físicamente.
Algunas veces la radio omnidireccional es buena, pero otras no lo es tanto. En la década de 1970, General Motors decidió equipar a todos sus Cadillacs nuevos con frenos antibloqueo controlados por computadora. Cuando el conductor pisaba el pedal del freno, la computadora accionaba los frenos para activarlos y desactivarlos en vez de bloquearlos con firmeza. Un buen día, un patrullero de las carreteras de Ohio encendió su nuevo radio móvil para llamar a la estación de policía, cuando de repente el Cadillac que iba junto a él empezó a comportarse como un potro salvaje. Cuando el oficial detuvo el auto, el conductor alegó que no había hecho nada y que el auto se había vuelto loco.
Con el tiempo empezó a surgir un patrón: algunas veces los Cadillacs se volvían locos, pero sólo en las principales carreteras de Ohio y sólo cuando alguna patrulla de caminos estaba cerca. Durante mucho tiempo, General Motors no pudo comprender por qué los Cadillacs funcionaban bien en todos los demás estados e incluso en los caminos secundarios de Ohio. Después de que emprendieron una búsqueda extensa descubrieron que el cableado de los Cadillacs formaba una excelente antena para la frecuencia utilizada
por el nuevo sistema de radio de las patrullas de caminos de Ohio.
Las propiedades de las ondas de radio dependen de la frecuencia. A bajas frecuencias, las ondas de radio cruzan bien los obstáculos, pero la potencia se reduce drásticamente a medida que se aleja de la fuente (por lo menos tan rápido como 1/r2 en el aire). A esta atenuación se le conoce como pérdida de trayectoria.
A frecuencias altas, las ondas de radio tienden a viajar en línea recta y rebotan en los obstáculos.
La pérdida de trayectoria reduce aún más la potencia, aunque la señal recibida también puede depender en gran parte de las reflexiones. Las ondas de radio de alta frecuencia también son absorbidas por la lluvia y otros obstáculos en mayor grado que las de baja frecuencia. En todas las frecuencias las ondas de radio están sujetas a interferencia de los motores y demás equipos eléctricos.
Con la fibra, el cable coaxial y el par trenzado, la señal se reduce en la misma fracción por distancia de unidad, por ejemplo 20 dB por cada 100 m para el par trenzado. Con la radio, la señal se reduce en la misma fracción a medida que se duplica la distancia, por ejemplo 6 dB por cada vez que se duplique la distancia en el espacio libre. Este comportamiento indica que las ondas de radio pueden recorrer grandes distancias y, en consecuencia, la interferencia entre usuarios es un problema. Por esta razón, es común que los gobiernos regulen estrictamente el uso de los radiotransmisores.
En las bandas VLF, LF y MF las ondas de radio siguen la curvatura de la Tierra. Estas ondas se pueden detectar quizás a 1000 km en las frecuencias más bajas, y a menos distancia en las frecuencias más altas. La difusión de radio AM utiliza la banda MF; por esta razón las ondas terrestres de las estaciones de radio AM de Boston no se pueden escuchar con facilidad en Nueva York. Las ondas de radio en estas bandas pasan por los edificios fácilmente, razón por la cual los radios portátiles funcionan en interiores. El principal problema al usar estas bandas para la comunicación de datos es su bajo ancho de banda.
En las bandas HF y VHF, las ondas terrestres tienden a ser absorbidas por la Tierra. Sin embargo, las ondas que llegan a la ionosfera (una capa de partículas cargadas que rodean la Tierra a una altura de 100 a 500 km) se refractan y se envían de vuelta a nuestro planeta. Bajo ciertas condiciones atmosféricas, las señales pueden rebotar varias veces. Los operadores de las bandas de radio aficionados utilizan estas bandas para conversar a larga distancia. El ejército también se comunica en las bandas HF y VHF.
Transmisión por microondas
Por encima de los 100 MHz, las ondas viajan en línea recta y en consecuencia, se pueden enfocar en un haz estrecho. Al concentrar toda la energía en un pequeño haz por medio de una antena parabólica (como el tan conocido plato de TV por satélite) se obtiene una relación señal-ruido mucho más alta, pero las antenas transmisora y receptora deben estar alineadas entre sí con precisión. Además, esta direccionalidad permite que varios transmisores alineados en fila se comuniquen con varios receptores sin interferencia, siempre y cuando se sigan ciertas reglas de espacio mínimo. Antes de la fibra óptica, estas microondas formaron durante décadas el corazón del sistema de transmisión telefónica de larga distancia. De hecho, la empresa Microwave Communications Inc. (MCI) construyó todo su sistema a partir de comunicaciones por microondas que iban de torre en torre ubicadas a decenas de kilómetros una de la otra. Incluso el nombre de la empresa reflejaba esta cuestión. Después MCI cambió a la fibra óptica y por medio de una extensa serie de fusiones corporativas y bancarrotas en la reestructuración de las telecomunicaciones, se volvió parte de Verizon.
Puesto que las microondas viajan en línea recta, si las torres están demasiado separadas, la Tierra se interpondrá en el camino. Por ende se necesitan repetidores periódicos. Entre más altas sean las torres, más separadas pueden estar. La distancia entre repetidores se eleva en forma muy aproximada a la raíz cuadrada de la altura de la torre. Si tenemos torres de 100 metros de altura, los repetidores pueden estar separados a 80 km de distancia.
A diferencia de las ondas de radio a frecuencias más bajas, las microondas no pueden atravesar bien los edificios. Además, aun cuando el haz puede estar bien enfocado en el transmisor, hay cierta divergencia en el espacio. Algunas ondas pueden refractarse en las capas atmosféricas más bajas y tardar un poco más en llegar que las ondas directas. Estas ondas retrasadas pueden llegar desfasadas con la onda directa y cancelar así la señal. A este efecto se le llama desvanecimiento por multitrayectorias y representa a menudo un problema grave que depende del clima y de la frecuencia. Algunos operadores mantienen el 10% de sus canales inactivos como repuestos para activarlos cuando el desvanecimiento por multitrayectorias cancela en forma temporal alguna banda de frecuencia.
Transmisión Infraroja
Las ondas infrarrojas no guiadas se usan mucho para la comunicación de corto alcance. El control remoto de los televisores, grabadoras de video y estéreos utilizan comunicación infrarroja. Son relativamente direccionales, económicos y fáciles de construir, pero tienen un gran inconveniente: no atraviesan objetos sólidos (pruebe pararse entre el control remoto y su televisión, y vea si aún funciona). En general, conforme pasamos de la radio de onda larga hacia la luz visible, las ondas se comportan cada vez más como la luz y cada vez menos como la radio.
Por otro lado, el hecho de que las ondas infrarrojas no atraviesen bien las paredes sólidas también es una ventaja. Esto significa que un sistema infrarrojo en un cuarto de un edificio no interferirá con un sistema similar en cuartos o edificios adyacentes; no podrá controlar la televisión de su vecino con su control remoto. Además, la seguridad de los sistemas infrarrojos contra el espionaje es mejor que la de los sistemas de radio, precisamente por esta razón. Por ende, no se necesita licencia gubernamental para operar un sistema infrarrojo, en contraste con los sistemas de radio, que deben contar con licencia excepto las bandas ISM.
La comunicación infrarroja tiene un uso limitado en el escritorio; por ejemplo, para conectar computadoras portátiles e impresoras mediante el estándar IrDA (Asociación de Datos por Infrarrojo, del inglés Infrared Data Association), aunque no es un protagonista importante en el juego de las comunicaciones.
Nuestra Era ha dado origen a los adictos a la información: personas que necesitan estar todo el tiempo en línea. Para estos usuarios móviles no son de utilidad el par trenzado, el cable coaxial ni la fibra óptica. Necesitan obtener datos para sus computadoras laptop, notebook, de bolsillo, de mano o de reloj de pulsera sin tener que estar atados a la infraestructura de comunicación terrestre. Para estos usuarios, la comunicación inalámbrica es la respuesta.
El espectro electromagnético
Cuando los electrones se mueven, crean ondas electromagnéticas que se pueden propagar por el espacio (incluso en el vacío). El físico inglés James Clerk Maxwell predijo estas ondas en 1865 y el físico alemán Heinrich Hertz las observó por primera vez en 1887. El número de oscilaciones por segundo de una onda es su frecuencia, f, y se mide en Hz (en honor de Heinrich Hertz). La distancia entre dos máximos (o mínimos) consecutivos se llama longitud de onda y se designa en forma universal mediante la letra griega λ (lambda).
Al conectar una antena del tamaño apropiado a un circuito eléctrico, las ondas electromagnéticas se pueden difundir de manera eficiente y un receptor las puede captar a cierta distancia. Toda la comunicación inalámbrica se basa en este principio. En el vacío, todas las ondas electromagnéticas viajan a la misma velocidad sin importar cuál sea su frecuencia. Esta velocidad se conoce como velocidad de la luz, c, y es de aproximadamente 3 3 108 m/seg, o alrededor de 1 pie (30 cm) por nanosegundo (podríamos argumentar para redefinir el pie como la distancia que viaja la luz en un vacío por 1 nseg en vez de basarnos en el tamaño del zapato de un rey que murió hace mucho tiempo). En el cobre o la fibra, la velocidad baja a casi 2/3 de este valor y se vuelve ligeramente dependiente de la frecuencia. La velocidad de la luz es el máximo límite de velocidad. Ningún objeto o señal puede llegar a ser más rápido que la luz.
La relación fundamental entre f, λ y c (en el vacío) es: λf = c
Dado que c es una constante, si conocemos el valor f podemos encontrar λ y viceversa. Como regla práctica, cuando λ se da en metros y f en MHz, λf ≈ 300. Por ejemplo, las ondas de 100 MHz tienen una longitud aproximada de 3 metros, las ondas de 1000 MHz tienen una longitud de 0.3 metros y las ondas de 0.1 metros tienen una frecuencia de 3 000 MHz.
Las porciones de radio, microondas, infrarrojo y luz visible del espectro se pueden utilizar para transmitir información mediante la modulación de la amplitud, frecuencia o fase de las ondas. La luz ultravioleta, los rayos X y los rayos gamma serían todavía mejores, debido a sus frecuencias más altas, pero son difíciles de producir y de modular, no se propagan bien entre edificios y son peligrosos para los seres vivos.
La mayoría de las transmisiones utilizan una banda de frecuencia relativamente estrecha. Concentran sus señales en esta banda estrecha para usar el espectro con eficiencia y obtienen tasas de datos razonables al transmitir con suficiente potencia. Pero en algunos casos se utiliza una banda ancha, con tres variaciones. En el espectro disperso con salto de frecuencia, el transmisor salta de frecuencia en frecuencia cientos de veces por segundo. Es popular en la comunicación militar, ya que hace a las transmisiones difíciles de detectar y casi imposibles de bloquear.
Hay una segunda forma de espectro disperso conocida como espectro disperso de secuencia directa, la cual utiliza una secuencia de códigos para dispersar los datos sobre una banda de frecuencia ancha. Su uso comercial es muy popular como una forma espectralmente eficiente de permitir que múltiples señales compartan la misma banda de frecuencia. Estas señales pueden recibir distintos códigos, un método conocido como CDMA (Acceso Múltiple por División de Código, del inglés Code Division Multiple Access) que veremos más adelante en este capítulo.
Un tercer método de comunicación con una banda más ancha es la comunicación UWB (Banda Ultra-Ancha). La UWB envía una serie de pulsos rápidos, los cuales varían sus posiciones para comunicar la información. Las transiciones rápidas conducen a una señal que se dispersa finamente sobre una banda de frecuencia muy amplia. UWB se define como señales que tienen un ancho de banda de por lo menos 500 MHz o de al menos 20% de la frecuencia central de su banda de frecuencia.
Radiotransmisión
Las ondas de radio frecuencia (RF) son fáciles de generar, pueden recorrer distancias largas y penetrar edificios con facilidad, de modo que son muy utilizados en la comunicación, tanto en interiores como en exteriores. Las ondas de radio también son omnidireccionales, lo cual significa que viajan en todas direcciones desde la fuente, por lo que el transmisor y el receptor no tienen que estar alineados físicamente.
Algunas veces la radio omnidireccional es buena, pero otras no lo es tanto. En la década de 1970, General Motors decidió equipar a todos sus Cadillacs nuevos con frenos antibloqueo controlados por computadora. Cuando el conductor pisaba el pedal del freno, la computadora accionaba los frenos para activarlos y desactivarlos en vez de bloquearlos con firmeza. Un buen día, un patrullero de las carreteras de Ohio encendió su nuevo radio móvil para llamar a la estación de policía, cuando de repente el Cadillac que iba junto a él empezó a comportarse como un potro salvaje. Cuando el oficial detuvo el auto, el conductor alegó que no había hecho nada y que el auto se había vuelto loco.
Con el tiempo empezó a surgir un patrón: algunas veces los Cadillacs se volvían locos, pero sólo en las principales carreteras de Ohio y sólo cuando alguna patrulla de caminos estaba cerca. Durante mucho tiempo, General Motors no pudo comprender por qué los Cadillacs funcionaban bien en todos los demás estados e incluso en los caminos secundarios de Ohio. Después de que emprendieron una búsqueda extensa descubrieron que el cableado de los Cadillacs formaba una excelente antena para la frecuencia utilizada
por el nuevo sistema de radio de las patrullas de caminos de Ohio.
Las propiedades de las ondas de radio dependen de la frecuencia. A bajas frecuencias, las ondas de radio cruzan bien los obstáculos, pero la potencia se reduce drásticamente a medida que se aleja de la fuente (por lo menos tan rápido como 1/r2 en el aire). A esta atenuación se le conoce como pérdida de trayectoria.
A frecuencias altas, las ondas de radio tienden a viajar en línea recta y rebotan en los obstáculos.
La pérdida de trayectoria reduce aún más la potencia, aunque la señal recibida también puede depender en gran parte de las reflexiones. Las ondas de radio de alta frecuencia también son absorbidas por la lluvia y otros obstáculos en mayor grado que las de baja frecuencia. En todas las frecuencias las ondas de radio están sujetas a interferencia de los motores y demás equipos eléctricos.
Con la fibra, el cable coaxial y el par trenzado, la señal se reduce en la misma fracción por distancia de unidad, por ejemplo 20 dB por cada 100 m para el par trenzado. Con la radio, la señal se reduce en la misma fracción a medida que se duplica la distancia, por ejemplo 6 dB por cada vez que se duplique la distancia en el espacio libre. Este comportamiento indica que las ondas de radio pueden recorrer grandes distancias y, en consecuencia, la interferencia entre usuarios es un problema. Por esta razón, es común que los gobiernos regulen estrictamente el uso de los radiotransmisores.
En las bandas VLF, LF y MF las ondas de radio siguen la curvatura de la Tierra. Estas ondas se pueden detectar quizás a 1000 km en las frecuencias más bajas, y a menos distancia en las frecuencias más altas. La difusión de radio AM utiliza la banda MF; por esta razón las ondas terrestres de las estaciones de radio AM de Boston no se pueden escuchar con facilidad en Nueva York. Las ondas de radio en estas bandas pasan por los edificios fácilmente, razón por la cual los radios portátiles funcionan en interiores. El principal problema al usar estas bandas para la comunicación de datos es su bajo ancho de banda.
En las bandas HF y VHF, las ondas terrestres tienden a ser absorbidas por la Tierra. Sin embargo, las ondas que llegan a la ionosfera (una capa de partículas cargadas que rodean la Tierra a una altura de 100 a 500 km) se refractan y se envían de vuelta a nuestro planeta. Bajo ciertas condiciones atmosféricas, las señales pueden rebotar varias veces. Los operadores de las bandas de radio aficionados utilizan estas bandas para conversar a larga distancia. El ejército también se comunica en las bandas HF y VHF.
Transmisión por microondas
Por encima de los 100 MHz, las ondas viajan en línea recta y en consecuencia, se pueden enfocar en un haz estrecho. Al concentrar toda la energía en un pequeño haz por medio de una antena parabólica (como el tan conocido plato de TV por satélite) se obtiene una relación señal-ruido mucho más alta, pero las antenas transmisora y receptora deben estar alineadas entre sí con precisión. Además, esta direccionalidad permite que varios transmisores alineados en fila se comuniquen con varios receptores sin interferencia, siempre y cuando se sigan ciertas reglas de espacio mínimo. Antes de la fibra óptica, estas microondas formaron durante décadas el corazón del sistema de transmisión telefónica de larga distancia. De hecho, la empresa Microwave Communications Inc. (MCI) construyó todo su sistema a partir de comunicaciones por microondas que iban de torre en torre ubicadas a decenas de kilómetros una de la otra. Incluso el nombre de la empresa reflejaba esta cuestión. Después MCI cambió a la fibra óptica y por medio de una extensa serie de fusiones corporativas y bancarrotas en la reestructuración de las telecomunicaciones, se volvió parte de Verizon.
Puesto que las microondas viajan en línea recta, si las torres están demasiado separadas, la Tierra se interpondrá en el camino. Por ende se necesitan repetidores periódicos. Entre más altas sean las torres, más separadas pueden estar. La distancia entre repetidores se eleva en forma muy aproximada a la raíz cuadrada de la altura de la torre. Si tenemos torres de 100 metros de altura, los repetidores pueden estar separados a 80 km de distancia.
A diferencia de las ondas de radio a frecuencias más bajas, las microondas no pueden atravesar bien los edificios. Además, aun cuando el haz puede estar bien enfocado en el transmisor, hay cierta divergencia en el espacio. Algunas ondas pueden refractarse en las capas atmosféricas más bajas y tardar un poco más en llegar que las ondas directas. Estas ondas retrasadas pueden llegar desfasadas con la onda directa y cancelar así la señal. A este efecto se le llama desvanecimiento por multitrayectorias y representa a menudo un problema grave que depende del clima y de la frecuencia. Algunos operadores mantienen el 10% de sus canales inactivos como repuestos para activarlos cuando el desvanecimiento por multitrayectorias cancela en forma temporal alguna banda de frecuencia.
Transmisión Infraroja
Las ondas infrarrojas no guiadas se usan mucho para la comunicación de corto alcance. El control remoto de los televisores, grabadoras de video y estéreos utilizan comunicación infrarroja. Son relativamente direccionales, económicos y fáciles de construir, pero tienen un gran inconveniente: no atraviesan objetos sólidos (pruebe pararse entre el control remoto y su televisión, y vea si aún funciona). En general, conforme pasamos de la radio de onda larga hacia la luz visible, las ondas se comportan cada vez más como la luz y cada vez menos como la radio.
Por otro lado, el hecho de que las ondas infrarrojas no atraviesen bien las paredes sólidas también es una ventaja. Esto significa que un sistema infrarrojo en un cuarto de un edificio no interferirá con un sistema similar en cuartos o edificios adyacentes; no podrá controlar la televisión de su vecino con su control remoto. Además, la seguridad de los sistemas infrarrojos contra el espionaje es mejor que la de los sistemas de radio, precisamente por esta razón. Por ende, no se necesita licencia gubernamental para operar un sistema infrarrojo, en contraste con los sistemas de radio, que deben contar con licencia excepto las bandas ISM.
La comunicación infrarroja tiene un uso limitado en el escritorio; por ejemplo, para conectar computadoras portátiles e impresoras mediante el estándar IrDA (Asociación de Datos por Infrarrojo, del inglés Infrared Data Association), aunque no es un protagonista importante en el juego de las comunicaciones.
7.1.4) Satélites de comunicación
En la década de 1950 y a principios de la década de 1960, las personas trataban de establecer sistemas de comunicación mediante el rebote de señales sobre globos meteorológicos. Por desgracia, las señales que se recibían eran demasiado débiles como para darles un uso práctico. Después, la marina de Estados Unidos observó un tipo de globo meteorológico permanente en el cielo (la Luna), de modo que construyó un sistema operacional para la comunicación de barcos con la costa mediante señales que rebotaban de la Luna. El avance en el campo de la comunicación celestial tuvo que esperar hasta que se lanzó el primer satélite de comunicaciones. La diferencia clave entre un satélite artificial y uno real es que el primero puede amplificar las señales antes de enviarlas de regreso, convirtiendo una extraña curiosidad en un poderoso sistema de comunicaciones.
Los satélites de comunicaciones tienen ciertas propiedades interesantes que los hacen atractivos para muchas aplicaciones. En su forma más simple, podemos considerar un satélite de comunicaciones como un enorme repetidor de microondas en el cielo que contiene varios transpondedores, cada uno de los cuales escucha en cierta porción del espectro, amplifica la señal entrante y después la retransmite en otra frecuencia para evitar interferencia con la señal entrante. Este modo de operación se llama tubo doblado. Se puede agregar un procesamiento digital para manipular o redirigir por separado los flujos de datos en toda la banda, o el satélite puede recibir información digital y retransmitirla. Esta forma de regeneración de señales mejora el desempeño si se le compara con un tubo doblado, ya que el satélite no amplifica el ruido en la señal que va hacia arriba. Los haces que descienden pueden ser amplios y cubrir una fracción considerable de la superficie de la Tierra, o pueden ser estrechos y cubrir un área de unos cuantos cientos de kilómetros de diámetro.
De acuerdo con la ley de Kepler, el periodo orbital de un satélite varía según el radio de la órbita a la 3/2 potencia. Entre más alto esté el satélite, mayor será el periodo. Cerca de la superficie de la Tierra, el periodo es de aproximadamente 90 minutos. En consecuencia, los satélites con órbitas bajas salen del rango de visión muy rápido, de modo que muchos de ellos deben proveer una cobertura continua y las antenas terrestres deben rastrearlos. El periodo de un satélite es importante, pero no es la única razón para determinar en dónde colocarlo. Otra cuestión es la presencia de los cinturones de Van Allen: capas de partículas altamente cargadas, atrapadas por el campo magnético de la Tierra. Cualquier satélite que volara dentro de los cinturones quedaría destruido casi al instante debido a las partículas. Estos factores condujeron a tres regiones en las que se pueden colocar los satélites de forma segura. En la figura 2-15 se muestran estas regiones con algunas de sus propiedades.

Satélites geoestacionarios
En 1945, el escritor de ciencia ficción Arthur C. Clarke calculó que un satélite con una altitud de 35 800 km en una órbita ecuatorial circular parecería estar inmóvil en el cielo, por lo que no habría la necesidad de rastrearlo. Pasó a describir un sistema completo de comunicaciones que utilizaba estos satélites geoestacionarios (tripulados), incluyendo las órbitas, los paneles solares, las frecuencias de radio y los procedimientos de lanzamiento. Por desgracia concluyó que los satélites no eran prácticos debido a la imposibilidad de poner en órbita amplificadores de tubos de vacío frágiles y que consumían una gran cantidad de energía, por lo que nunca profundizó sobre esta idea, aunque escribió algunas historias de ciencia ficción sobre el tema.
La invención del transistor cambió todo eso; el primer satélite de comunicación artificial llamado Telstar se lanzó en julio de 1962. Desde entonces, los satélites de comunicación se convirtieron en un negocio multimillonario y el único aspecto del espacio exterior que se ha vuelto muy rentable. Estos satélites que vuelan a grandes alturas se conocen comúnmente como satélites GEO (Órbita Terrestre Geoestacionaria, del inglés Geostationary Earth Orbit).
Los satélites modernos pueden ser muy grandes y pesar más de 5 000 kg, además de que consumen varios kilowatts de energía eléctrica producida por los paneles solares. Los efectos de la gravedad solar, lunar y planetaria tienden a alejarlos de sus espacios orbitales y orientaciones asignadas, un efecto que se contrarresta mediante motores de cohete integrados. Esta actividad de ajuste se conoce como control de la posición orbital (station keeping). Sin embargo, cuando se agota el combustible de los motores (por lo general después de casi 10 años), el satélite queda a la deriva y cae sin que se pueda hacer nada, de modo que debe ser desactivado. En un momento dado la órbita se deteriora, el satélite vuelve a entrar en la atmósfera y se quema (o en muy raras ocasiones, se estrella en la Tierra).
Los espacios orbitales no son el único motivo de discordia. Las frecuencias también son otro problema debido a que las transmisiones de los enlaces descendentes interfieren con los usuarios existentes de microondas. En consecuencia, la Unión Internacional de Telecomunicaciones (ITU) ha asignado bandas de frecuencia específicas a los usuarios de satélites.

La siguiente banda más ancha disponible para las portadoras de telecomunicaciones comerciales es la banda Ku (K inferior, del inglés K under). Esta banda (aún) no está saturada; a sus frecuencias más altas los satélites pueden tener una separación mínima de 1 grado. Sin embargo, existe otro problema: la lluvia. El agua absorbe bien estas microondas cortas. Por fortuna, las tormentas fuertes por lo general son localizables, de modo que para resolver el problema se pueden usar varias estaciones terrestres separadas a grandes distancias en vez de usar sólo una, pero a costa de requerir antenas, cables y componentes electrónicos adicionales para permitir una conmutación rápida entre las estaciones. También se asignó ancho de banda en la banda Ka (K superior, del inglés K above) para el tráfico comercial de satélites, pero el equipo necesario para utilizarla es costoso. Además de estas bandas comerciales, también existen muchas bandas gubernamentales y militares.
Un reciente acontecimiento en el mundo de los satélites de comunicaciones es el desarrollo de microestaciones de bajo costo, conocidas también como VSAT (Terminales de apertura muy pequeña, del inglés Very Small Apertura Terminals). Estas pequeñas terminales tienen antenas de 1 metro o menos (en comparación con las antenas GEO estándar de 10 m) y pueden emitir cerca de 1 watt de potencia. El enlace ascendente es generalmente bueno para soportar hasta 1 Mbps, pero el enlace descendente puede soportar por lo general hasta varios megabits/seg. La televisión vía satélite de difusión directa utiliza esta tecnología para la transmisión unidireccional.
Satélites de Órbita Terrestre Media (MEO)
En altitudes mucho más bajas entre los dos cinturones de Van Allen se encuentran los satélites MEO (Orbita Terrestre Media, del inglés Medium-Earth Orbit). Vistos desde la Tierra, se desvían lentamente en longitud y tardan cerca de seis horas en dar vuelta a la Tierra. Por ende, hay que rastrearlos a medida que se mueven por el cielo. Como tienen menor altura que los satélites GEO, producen una huella más pequeña en la Tierra y requieren transmisores menos poderosos para comunicarse. En la actualidad se utilizan para sistemas de navegación en vez de las telecomunicaciones, por lo que no daremos más detalles sobre ellos. La constelación de alrededor de 30 satélites GPS (Sistema de Posicionamiento Global, del inglés Global Positioning System) que giran a una distancia aproximada de 20 200 km son ejemplos de satélites MEO.
Satélites de Órbita Terrestre Baja (LEO)
Los satélites LEO (Órbita Terrestre Baja, del inglés Low-Earth Orbit) se encuentran a una altitud todavía más baja. Debido a su rápido movimiento, se necesita un gran número de ellos para un sistema completo. Por otro lado, como los satélites están tan cerca de la Tierra, las estaciones terrestres no necesitan mucha potencia y el retardo de viaje redondo es de sólo unos cuantos milisegundos. El costo de lanzamiento es más económico.
Durante los primeros 30 años de la era satelital, rara vez se utilizaban los satélites de órbita baja debido a que entran y salen del campo de visión con mucha rapidez. En 1990, Motorola abrió nuevos caminos al presentar una solicitud a la FCC para lanzar 77 satélites de órbita baja para el proyecto Iridium (el iridio es el elemento 77). El plan se revisó después para usar sólo 66 satélites, de modo que el proyecto debió haber cambiado su nombre a Dysprosium (elemento 66), pero probablemente eso sonaba muy parecido a una enfermedad. La idea era que, tan pronto como un satélite quedara fuera del campo de visión, otro lo reemplazaría. Esta propuesta desató una gran exaltación entre las demás compañías de comunicaciones. De repente todos querían lanzar una cadena de satélites de órbita baja. Después de siete años de reunir improvisadamente socios y financiamiento, el servicio de comunicación empezó en noviembre de 1998. Por desgracia, la demanda comercial de teléfonos satelitales grandes y pesados era insignificante debido a que a partir de 1990 la red de telefonía móvil había crecido de manera espectacular. Como consecuencia, Iridium no fue rentable y entró en bancarrota en agosto de 1999, en uno de los fracasos corporativos más espectaculares de la historia. Más adelante un inversionista compró los satélites y otros activos (con valor de $5 mil millones) por $25 millones, en un tipo de venta de garaje extraterrestre. A éste le siguieron casi de inmediato otros proyectos empresariales de satélites.
Los satélites Iridium están posicionados a una altitud de 750 km, en órbitas polares circulares. Están dispuestos en forma de collares de norte a sur con un satélite cada 32 grados de latitud.
Una alternativa de diseño para Iridium es Globalstar, que se basa en 48 satélites LEO pero utiliza un esquema de conmutación distinto al de Iridium. Mientras que Iridium transmite llamadas de un satélite a otro, para lo cual se requiere de un sofisticado equipo de conmutación en los satélites, Globalstar utiliza un diseño tradicional de tubo doblado.
En la década de 1950 y a principios de la década de 1960, las personas trataban de establecer sistemas de comunicación mediante el rebote de señales sobre globos meteorológicos. Por desgracia, las señales que se recibían eran demasiado débiles como para darles un uso práctico. Después, la marina de Estados Unidos observó un tipo de globo meteorológico permanente en el cielo (la Luna), de modo que construyó un sistema operacional para la comunicación de barcos con la costa mediante señales que rebotaban de la Luna. El avance en el campo de la comunicación celestial tuvo que esperar hasta que se lanzó el primer satélite de comunicaciones. La diferencia clave entre un satélite artificial y uno real es que el primero puede amplificar las señales antes de enviarlas de regreso, convirtiendo una extraña curiosidad en un poderoso sistema de comunicaciones.
Los satélites de comunicaciones tienen ciertas propiedades interesantes que los hacen atractivos para muchas aplicaciones. En su forma más simple, podemos considerar un satélite de comunicaciones como un enorme repetidor de microondas en el cielo que contiene varios transpondedores, cada uno de los cuales escucha en cierta porción del espectro, amplifica la señal entrante y después la retransmite en otra frecuencia para evitar interferencia con la señal entrante. Este modo de operación se llama tubo doblado. Se puede agregar un procesamiento digital para manipular o redirigir por separado los flujos de datos en toda la banda, o el satélite puede recibir información digital y retransmitirla. Esta forma de regeneración de señales mejora el desempeño si se le compara con un tubo doblado, ya que el satélite no amplifica el ruido en la señal que va hacia arriba. Los haces que descienden pueden ser amplios y cubrir una fracción considerable de la superficie de la Tierra, o pueden ser estrechos y cubrir un área de unos cuantos cientos de kilómetros de diámetro.
De acuerdo con la ley de Kepler, el periodo orbital de un satélite varía según el radio de la órbita a la 3/2 potencia. Entre más alto esté el satélite, mayor será el periodo. Cerca de la superficie de la Tierra, el periodo es de aproximadamente 90 minutos. En consecuencia, los satélites con órbitas bajas salen del rango de visión muy rápido, de modo que muchos de ellos deben proveer una cobertura continua y las antenas terrestres deben rastrearlos. El periodo de un satélite es importante, pero no es la única razón para determinar en dónde colocarlo. Otra cuestión es la presencia de los cinturones de Van Allen: capas de partículas altamente cargadas, atrapadas por el campo magnético de la Tierra. Cualquier satélite que volara dentro de los cinturones quedaría destruido casi al instante debido a las partículas. Estos factores condujeron a tres regiones en las que se pueden colocar los satélites de forma segura. En la figura 2-15 se muestran estas regiones con algunas de sus propiedades.

Satélites geoestacionarios
En 1945, el escritor de ciencia ficción Arthur C. Clarke calculó que un satélite con una altitud de 35 800 km en una órbita ecuatorial circular parecería estar inmóvil en el cielo, por lo que no habría la necesidad de rastrearlo. Pasó a describir un sistema completo de comunicaciones que utilizaba estos satélites geoestacionarios (tripulados), incluyendo las órbitas, los paneles solares, las frecuencias de radio y los procedimientos de lanzamiento. Por desgracia concluyó que los satélites no eran prácticos debido a la imposibilidad de poner en órbita amplificadores de tubos de vacío frágiles y que consumían una gran cantidad de energía, por lo que nunca profundizó sobre esta idea, aunque escribió algunas historias de ciencia ficción sobre el tema.
La invención del transistor cambió todo eso; el primer satélite de comunicación artificial llamado Telstar se lanzó en julio de 1962. Desde entonces, los satélites de comunicación se convirtieron en un negocio multimillonario y el único aspecto del espacio exterior que se ha vuelto muy rentable. Estos satélites que vuelan a grandes alturas se conocen comúnmente como satélites GEO (Órbita Terrestre Geoestacionaria, del inglés Geostationary Earth Orbit).
Los satélites modernos pueden ser muy grandes y pesar más de 5 000 kg, además de que consumen varios kilowatts de energía eléctrica producida por los paneles solares. Los efectos de la gravedad solar, lunar y planetaria tienden a alejarlos de sus espacios orbitales y orientaciones asignadas, un efecto que se contrarresta mediante motores de cohete integrados. Esta actividad de ajuste se conoce como control de la posición orbital (station keeping). Sin embargo, cuando se agota el combustible de los motores (por lo general después de casi 10 años), el satélite queda a la deriva y cae sin que se pueda hacer nada, de modo que debe ser desactivado. En un momento dado la órbita se deteriora, el satélite vuelve a entrar en la atmósfera y se quema (o en muy raras ocasiones, se estrella en la Tierra).
Los espacios orbitales no son el único motivo de discordia. Las frecuencias también son otro problema debido a que las transmisiones de los enlaces descendentes interfieren con los usuarios existentes de microondas. En consecuencia, la Unión Internacional de Telecomunicaciones (ITU) ha asignado bandas de frecuencia específicas a los usuarios de satélites.

PRINCIPALES BANDAS DE SATELITES
La siguiente banda más ancha disponible para las portadoras de telecomunicaciones comerciales es la banda Ku (K inferior, del inglés K under). Esta banda (aún) no está saturada; a sus frecuencias más altas los satélites pueden tener una separación mínima de 1 grado. Sin embargo, existe otro problema: la lluvia. El agua absorbe bien estas microondas cortas. Por fortuna, las tormentas fuertes por lo general son localizables, de modo que para resolver el problema se pueden usar varias estaciones terrestres separadas a grandes distancias en vez de usar sólo una, pero a costa de requerir antenas, cables y componentes electrónicos adicionales para permitir una conmutación rápida entre las estaciones. También se asignó ancho de banda en la banda Ka (K superior, del inglés K above) para el tráfico comercial de satélites, pero el equipo necesario para utilizarla es costoso. Además de estas bandas comerciales, también existen muchas bandas gubernamentales y militares.
Un reciente acontecimiento en el mundo de los satélites de comunicaciones es el desarrollo de microestaciones de bajo costo, conocidas también como VSAT (Terminales de apertura muy pequeña, del inglés Very Small Apertura Terminals). Estas pequeñas terminales tienen antenas de 1 metro o menos (en comparación con las antenas GEO estándar de 10 m) y pueden emitir cerca de 1 watt de potencia. El enlace ascendente es generalmente bueno para soportar hasta 1 Mbps, pero el enlace descendente puede soportar por lo general hasta varios megabits/seg. La televisión vía satélite de difusión directa utiliza esta tecnología para la transmisión unidireccional.
Satélites de Órbita Terrestre Media (MEO)
En altitudes mucho más bajas entre los dos cinturones de Van Allen se encuentran los satélites MEO (Orbita Terrestre Media, del inglés Medium-Earth Orbit). Vistos desde la Tierra, se desvían lentamente en longitud y tardan cerca de seis horas en dar vuelta a la Tierra. Por ende, hay que rastrearlos a medida que se mueven por el cielo. Como tienen menor altura que los satélites GEO, producen una huella más pequeña en la Tierra y requieren transmisores menos poderosos para comunicarse. En la actualidad se utilizan para sistemas de navegación en vez de las telecomunicaciones, por lo que no daremos más detalles sobre ellos. La constelación de alrededor de 30 satélites GPS (Sistema de Posicionamiento Global, del inglés Global Positioning System) que giran a una distancia aproximada de 20 200 km son ejemplos de satélites MEO.
Satélites de Órbita Terrestre Baja (LEO)
Los satélites LEO (Órbita Terrestre Baja, del inglés Low-Earth Orbit) se encuentran a una altitud todavía más baja. Debido a su rápido movimiento, se necesita un gran número de ellos para un sistema completo. Por otro lado, como los satélites están tan cerca de la Tierra, las estaciones terrestres no necesitan mucha potencia y el retardo de viaje redondo es de sólo unos cuantos milisegundos. El costo de lanzamiento es más económico.
Durante los primeros 30 años de la era satelital, rara vez se utilizaban los satélites de órbita baja debido a que entran y salen del campo de visión con mucha rapidez. En 1990, Motorola abrió nuevos caminos al presentar una solicitud a la FCC para lanzar 77 satélites de órbita baja para el proyecto Iridium (el iridio es el elemento 77). El plan se revisó después para usar sólo 66 satélites, de modo que el proyecto debió haber cambiado su nombre a Dysprosium (elemento 66), pero probablemente eso sonaba muy parecido a una enfermedad. La idea era que, tan pronto como un satélite quedara fuera del campo de visión, otro lo reemplazaría. Esta propuesta desató una gran exaltación entre las demás compañías de comunicaciones. De repente todos querían lanzar una cadena de satélites de órbita baja. Después de siete años de reunir improvisadamente socios y financiamiento, el servicio de comunicación empezó en noviembre de 1998. Por desgracia, la demanda comercial de teléfonos satelitales grandes y pesados era insignificante debido a que a partir de 1990 la red de telefonía móvil había crecido de manera espectacular. Como consecuencia, Iridium no fue rentable y entró en bancarrota en agosto de 1999, en uno de los fracasos corporativos más espectaculares de la historia. Más adelante un inversionista compró los satélites y otros activos (con valor de $5 mil millones) por $25 millones, en un tipo de venta de garaje extraterrestre. A éste le siguieron casi de inmediato otros proyectos empresariales de satélites.
Los satélites Iridium están posicionados a una altitud de 750 km, en órbitas polares circulares. Están dispuestos en forma de collares de norte a sur con un satélite cada 32 grados de latitud.
Una alternativa de diseño para Iridium es Globalstar, que se basa en 48 satélites LEO pero utiliza un esquema de conmutación distinto al de Iridium. Mientras que Iridium transmite llamadas de un satélite a otro, para lo cual se requiere de un sofisticado equipo de conmutación en los satélites, Globalstar utiliza un diseño tradicional de tubo doblado.
7.1.5) Modulación digital y multiplexión
Ahora que hemos estudiado las propiedades de los canales alámbricos e inalámbricos, nos enfocaremos en el problema de cómo enviar información digital. Los cables y los canales inalámbricos transportan señales analógicas, como el voltaje, la intensidad de la luz o del sonido que varían de forma continua. Para enviar información digital debemos idear señales analógicas que representen bits. Al proceso de realizar la conversión entre los bits y las señales que los representan se le conoce como modulación digital.
Empezaremos con esquemas que convierten directamente los bits en una señal. Estos esquemas resultan en una transmisión en banda base, en donde la señal ocupa frecuencias desde cero hasta un valor máximo que depende de la tasa de señalización. Este tipo de transmisión es común para los cables. Después consideraremos esquemas que varían la amplitud, fase o frecuencia de una señal portadora para transmitir los bits. Estos esquemas resultan en una transmisión pasa-banda, en donde la señal ocupa una banda de frecuencias alrededor de la frecuencia de la señal portadora. Es común para los canales inalámbricos y ópticos, en donde las señales deben residir en una banda de frecuencia dada. A menudo los canales se comparten entre varias señales. Después de todo, es mucho más conveniente utilizar un solo cable para transportar varias señales que instalar un cable para cada señal. A este tipo de compartición se le denomina multiplexión y se puede lograr de varias formas. Presentaremos los métodos para la multiplexión por división de tiempo, de frecuencia y de código. Las técnicas de modulación y multiplexión que describiremos en esta sección son muy usados en los cables, la fibra óptica, los canales inalámbricos terrestres y los canales de satélite.
Transmisión en banda base
La forma más simple de modulación digital es utilizar un voltaje positivo para representar un 1 y un voltaje negativo para representar un 0. Para una fibra óptica, la presencia de luz podría representar un 1 y la ausencia de luz podría representar un 0. Este esquema se denomina NRZ (No Retorno a Cero, del inglés Non-Return-to-Zero). El nombre extraño es por cuestiones históricas; simplemente significa que la señal sigue a los datos.
Una vez enviada, la señal NRZ se propaga por el cable. En el otro extremo, el receptor la convierte en bits al muestrear la señal a intervalos de tiempo regulares. Esta señal no se verá exactamente igual que la señal que se envió. El canal y el ruido en el receptor la atenuarán y distorsionarán. Para decodificar los bits, el receptor asocia las muestras de la señal con los símbolos más cercanos. Para NRZ, se tomará un voltaje positivo para indicar que se envió un 1 y un voltaje negativo para indicar que se envió un 0.
El esquema NRZ es un buen punto de inicio para nuestros estudios, ya que es simple pero se utiliza pocas veces por sí solo en la práctica. Los esquemas más complejos pueden convertir bits en señales que cumplen mejor con las consideraciones de ingeniería. Estos esquemas se denominan códigos de línea. A continuación describiremos códigos de línea que ayudan con la eficiencia del ancho de banda, la recuperación del reloj y el balance de CD.

Con NRZ, la señal puede alternar entre los niveles positivo y negativo hasta cada 2 bits (en caso de alternar 1 s y 0 s). Esto significa que necesitamos un ancho de banda de por lo menos B/2 Hz cuando la tasa de bits es de B bits/seg. Esta relación proviene de la tasa de Nyquist. Es un límite fundamental, por lo que no podemos operar el esquema NRZ a una mayor velocidad sin usar más ancho de banda. Por lo general el ancho de banda es un recurso limitado, incluso para los canales con cables. Entre más altas sean las frecuencias de las señales su atenuación es cada vez mayor, lo que las hace menos útiles; además las señales de frecuencias más altas también requieren componentes electrónicos más rápidos. Una estrategia para utilizar el ancho de banda limitado con más eficiencia es usar más de dos niveles de señalización. La tasa a la que cambia la señal se denomina tasa de símbolo para diferenciarla de la tasa de bits. La tasa de bits es la tasa de símbolo multiplicada por el número de bits por símbolo. Un nombre antiguo para la tasa de símbolo, en especial dentro del contexto de los dispositivos conocidos como módems telefónicos que transmiten datos digitales a través de las líneas telefónicas, es la tasa de baudios.
Las señales que tienen la misma cantidad de voltaje positivo y negativo, incluso durante periodos cortos, se conocen como señales balanceadas. Su promedio es cero, lo cual significa que no tienen componente eléctrico de CD. La falta de un componente de CD es una ventaja, ya que algunos canales (como el cable coaxial o las líneas con transformadores) atenúan de manera considerable un componente de CD debido a sus propiedades físicas. Además, un método para conectar el receptor al canal, conocido como acoplamiento capacitivo, sólo pasa la porción de CA de la señal. En cualquier caso, si enviamos una señal cuyo promedio no sea cero desperdiciaremos energía, puesto que se filtrará el componente de CD. El balanceo ayuda a proveer transiciones para la recuperación del reloj, ya que hay una mezcla de voltajes positivos y negativos. Además proporciona una forma simple de calibrar los receptores, debido a que se puede medir el promedio de la señal y usarlo como un umbral de decisión para decodificar los símbolos. Con las señales no balanceadas, el promedio puede variar del verdadero nivel de decisión, lo cual provocaría que se decodificaran más símbolos con errores.
Transmisión pasa-banda
A menudo es conveniente usar un rango de frecuencias que no empiece en cero para enviar información a través de un canal. En los canales inalámbricos no es práctico enviar señales de muy baja frecuencia, ya que el tamaño de la antena necesita ser de una fracción de la longitud de onda de la señal, por lo que llega a ser grande. En cualquier caso, por lo general la elección de frecuencias se dicta con base en las restricciones regulatorias y a la necesidad de evitar interferencias. Incluso para los cables, es útil colocar una señal en una banda de frecuencias específica para dejar que coexistan distintos tipos de señales en el canal. A este tipo de transmisión se le conoce como transmisión pasa-banda, debido a que se utiliza una banda arbitraria de frecuencias para pasar la señal.
Para lograr la modulación digital mediante la transmisión pasa-banda, se regula o modula una señal portadora que se sitúa en la banda de paso. Podemos modular la amplitud, frecuencia o fase de la señal portadora. Cada uno de estos métodos tiene su correspondiente nombre. En la ASK (Modulación por Desplazamiento de Amplitud, del inglés Amplitude Shift Keying) se utilizan dos amplitudes distintas para representar el 0 y 1.
De manera similar, en la FSK (Modulación por Desplazamiento de Frecuencia, del inglés Frequency Shift Keying) se utilizan dos o más tonos distintos. En la forma más simple de PSK (Modulación por Desplazamiento de Fase, del inglés Phase Shift Keying), la onda portadora se desplaza de manera sistemática 0 o 180 grados en cada periodo de símbolo. Como hay dos fases, se llama BPSK (Modulación por Desplazamiento de Fase Binaria, del inglés Binary Phase Shift Keying). Aquí, la palabra “binaria” se refiere a los dos símbolos, no que los símbolos representan 2 bits.
Un esquema más conveniente en el que se utiliza el ancho de banda del canal con más eficiencia es el que utiliza cuatro desplazamientos para transmitir 2 bits de información por símbolo. Esta versión se llama QPSK (Modulación por Desplazamiento de Fase en Cuadratura, del inglés Quadrature Phase Shift Keying).

De las siguientes figuras, en la figura (a) podemos ver puntos equidistantes a 45, 135, 225 y 315 grados. La amplitud de un punto es la distancia a partir del origen. Esta figura es una representación de QPSK. A este tipo de diagrama se le conoce como diagrama de constelación. En la figura (b) podemos ver un esquema de modulación con una constelación más densa. Se utilizan 16 combinaciones de amplitudes y fases, por lo que el esquema de modulación se puede usar para transmitir 4 bits por símbolo. Se denomina QAM-16, en donde QAM significa Modulación de Amplitud en Cuadratura (en inglés Quadrature Amplitude Modulatian). La figura (c) es un esquema de modulación todavía más denso con 64 combinaciones distintas, por lo que se pueden transmitir 6 bits por símbolo. Se denomina QAM-64. También se utilizan esquemas QAM más altos. Como podría sospechar de estas constelaciones, es más fácil construir componentes electrónicos para producir símbolos como una combinación de valores en cada eje, que como una combinación de valores de amplitud y fase. Ésta es la razón por la cual los patrones se ven como cuadros en vez de círculos concéntricos.

Multiplexión por división de frecuencia
Los esquemas de modulación que hemos visto nos permiten enviar una señal para transmitir bits a través de un enlace alámbrico o inalámbrico. Sin embargo, la economía de escala desempeña un importante papel en cuanto a la forma en que utilizamos las redes. En esencia, es igual de costoso instalar y mantener una línea de transmisión con un alto ancho de banda que una línea con un bajo ancho de banda entre dos oficinas distintas (es decir, los costos provienen de tener que cavar la zanja y no del tipo de cable o fibra óptica que se va a instalar).
Por ende, se han desarrollado esquemas de multiplexión para compartir líneas entre muchas señales. FDM (Multiplexión por División de Frecuencia, del inglés Frecuency Division Multiplexing) aprovecha la ventaja de la transmisión pasa-banda para compartir un canal. Divide el espectro en bandas de frecuencia, en donde cada usuario tiene posesión exclusiva de cierta banda en la que puede enviar su señal.
Las distintas frecuencias se asignan a distintos canales lógicos (estaciones), cada uno de los cuales opera en una parte del espectro y la separación entre canales es lo bastante grande como para evitar interferencias.
Para un ejemplo más detallado, en la siguiente figura mostramos tres canales telefónicos de calidad de voz, multiplexados mediante FDM. Los filtros limitan el ancho de banda útil a cerca de 3100 Hz por cada canal de calidad de voz. Cuando se multiplexan muchos canales juntos, se asignan 4 000 Hz por canal. Al exceso se le denomina banda de guarda, la cual mantiene los canales bien separados.

Este esquema se ha utilizado para mutiplexar llamadas en el sistema telefónico durante muchos años, pero ahora se prefiere más la multiplexión en el tiempo. Sin embargo, FDM se sigue utilizando en las redes telefónicas, así como en las redes celulares, redes inalámbricas terrestres y redes de satélites con un mayor nivel de granularidad. Al enviar datos digitales, es posible dividir el espectro de manera eficiente sin usar bandas de guarda. En OFDM (Multiplexión por División de Frecuencia Ortogonal, del inglés Orthogonal Frequency Division Multiplexing), el ancho de banda del canal se divide en muchas subportadoras que envían
datos de manera independiente. Las subportadoras están empaquetadas estrechamente en el dominio de la frecuencia. Por lo tanto, las señales de cada subportadora se extienden a las subportadoras adyacentes.
Multiplexión por división de tiempo
TDM (Multiplexión por División de Tiempo, del inglés Time Division Multiplexing) es una alternativa a FDM. Aquí, los usuarios toman turnos (rotatorios tipo round-robin) y cada uno recibe periódicamente todo el ancho de banda durante una pequeña ráfaga de tiempo. En la figura 2-27 se muestra un ejemplo de tres flujos multiplexados mediante TDM. Se toman bits de cada flujo de entrada en una ranura de tiempo fija y se envían al flujo agregado. Este flujo opera a una velocidad equivalente a la suma de los flujos individuales. Para que esto funcione, los flujos se deben estar sincronizados en tiempo. Se pueden agregar pequeños intervalos de tiempo de guarda, los cuales son análogos a una banda de guarda de frecuencia, para tener en cuenta las pequeñas variaciones de sincronización. El TDM se utiliza mucho como parte de las redes telefónicas y celulares. Para evitar un punto de confusión, dejemos claro que es muy distinto a la STDM (Multiplexión Estadística por División de Tiempo, del inglés Statistical Time Division Multiplexing). El prefijo “estadística” es para indicar que los flujos individuales contribuyen al flujo multiplexado no en un itinerario fijo, sino con base en la estadística de su demanda. En sí, STDM es otro nombre para la conmutación de paquetes.

Ahora que hemos estudiado las propiedades de los canales alámbricos e inalámbricos, nos enfocaremos en el problema de cómo enviar información digital. Los cables y los canales inalámbricos transportan señales analógicas, como el voltaje, la intensidad de la luz o del sonido que varían de forma continua. Para enviar información digital debemos idear señales analógicas que representen bits. Al proceso de realizar la conversión entre los bits y las señales que los representan se le conoce como modulación digital.
Empezaremos con esquemas que convierten directamente los bits en una señal. Estos esquemas resultan en una transmisión en banda base, en donde la señal ocupa frecuencias desde cero hasta un valor máximo que depende de la tasa de señalización. Este tipo de transmisión es común para los cables. Después consideraremos esquemas que varían la amplitud, fase o frecuencia de una señal portadora para transmitir los bits. Estos esquemas resultan en una transmisión pasa-banda, en donde la señal ocupa una banda de frecuencias alrededor de la frecuencia de la señal portadora. Es común para los canales inalámbricos y ópticos, en donde las señales deben residir en una banda de frecuencia dada. A menudo los canales se comparten entre varias señales. Después de todo, es mucho más conveniente utilizar un solo cable para transportar varias señales que instalar un cable para cada señal. A este tipo de compartición se le denomina multiplexión y se puede lograr de varias formas. Presentaremos los métodos para la multiplexión por división de tiempo, de frecuencia y de código. Las técnicas de modulación y multiplexión que describiremos en esta sección son muy usados en los cables, la fibra óptica, los canales inalámbricos terrestres y los canales de satélite.
Transmisión en banda base
La forma más simple de modulación digital es utilizar un voltaje positivo para representar un 1 y un voltaje negativo para representar un 0. Para una fibra óptica, la presencia de luz podría representar un 1 y la ausencia de luz podría representar un 0. Este esquema se denomina NRZ (No Retorno a Cero, del inglés Non-Return-to-Zero). El nombre extraño es por cuestiones históricas; simplemente significa que la señal sigue a los datos.
Una vez enviada, la señal NRZ se propaga por el cable. En el otro extremo, el receptor la convierte en bits al muestrear la señal a intervalos de tiempo regulares. Esta señal no se verá exactamente igual que la señal que se envió. El canal y el ruido en el receptor la atenuarán y distorsionarán. Para decodificar los bits, el receptor asocia las muestras de la señal con los símbolos más cercanos. Para NRZ, se tomará un voltaje positivo para indicar que se envió un 1 y un voltaje negativo para indicar que se envió un 0.
El esquema NRZ es un buen punto de inicio para nuestros estudios, ya que es simple pero se utiliza pocas veces por sí solo en la práctica. Los esquemas más complejos pueden convertir bits en señales que cumplen mejor con las consideraciones de ingeniería. Estos esquemas se denominan códigos de línea. A continuación describiremos códigos de línea que ayudan con la eficiencia del ancho de banda, la recuperación del reloj y el balance de CD.

Códigos de línea: (a) Bits, (b) NRZ, (c) NRZI, (d) Manchester, (e) Bipolar o AML
Las señales que tienen la misma cantidad de voltaje positivo y negativo, incluso durante periodos cortos, se conocen como señales balanceadas. Su promedio es cero, lo cual significa que no tienen componente eléctrico de CD. La falta de un componente de CD es una ventaja, ya que algunos canales (como el cable coaxial o las líneas con transformadores) atenúan de manera considerable un componente de CD debido a sus propiedades físicas. Además, un método para conectar el receptor al canal, conocido como acoplamiento capacitivo, sólo pasa la porción de CA de la señal. En cualquier caso, si enviamos una señal cuyo promedio no sea cero desperdiciaremos energía, puesto que se filtrará el componente de CD. El balanceo ayuda a proveer transiciones para la recuperación del reloj, ya que hay una mezcla de voltajes positivos y negativos. Además proporciona una forma simple de calibrar los receptores, debido a que se puede medir el promedio de la señal y usarlo como un umbral de decisión para decodificar los símbolos. Con las señales no balanceadas, el promedio puede variar del verdadero nivel de decisión, lo cual provocaría que se decodificaran más símbolos con errores.
Transmisión pasa-banda
A menudo es conveniente usar un rango de frecuencias que no empiece en cero para enviar información a través de un canal. En los canales inalámbricos no es práctico enviar señales de muy baja frecuencia, ya que el tamaño de la antena necesita ser de una fracción de la longitud de onda de la señal, por lo que llega a ser grande. En cualquier caso, por lo general la elección de frecuencias se dicta con base en las restricciones regulatorias y a la necesidad de evitar interferencias. Incluso para los cables, es útil colocar una señal en una banda de frecuencias específica para dejar que coexistan distintos tipos de señales en el canal. A este tipo de transmisión se le conoce como transmisión pasa-banda, debido a que se utiliza una banda arbitraria de frecuencias para pasar la señal.
Para lograr la modulación digital mediante la transmisión pasa-banda, se regula o modula una señal portadora que se sitúa en la banda de paso. Podemos modular la amplitud, frecuencia o fase de la señal portadora. Cada uno de estos métodos tiene su correspondiente nombre. En la ASK (Modulación por Desplazamiento de Amplitud, del inglés Amplitude Shift Keying) se utilizan dos amplitudes distintas para representar el 0 y 1.
De manera similar, en la FSK (Modulación por Desplazamiento de Frecuencia, del inglés Frequency Shift Keying) se utilizan dos o más tonos distintos. En la forma más simple de PSK (Modulación por Desplazamiento de Fase, del inglés Phase Shift Keying), la onda portadora se desplaza de manera sistemática 0 o 180 grados en cada periodo de símbolo. Como hay dos fases, se llama BPSK (Modulación por Desplazamiento de Fase Binaria, del inglés Binary Phase Shift Keying). Aquí, la palabra “binaria” se refiere a los dos símbolos, no que los símbolos representan 2 bits.
Un esquema más conveniente en el que se utiliza el ancho de banda del canal con más eficiencia es el que utiliza cuatro desplazamientos para transmitir 2 bits de información por símbolo. Esta versión se llama QPSK (Modulación por Desplazamiento de Fase en Cuadratura, del inglés Quadrature Phase Shift Keying).

(a) Una señal binaria, (b) Modulación por desplazamiento de amplitud, (c) Modulación por desplazamiento de frecuencia
(d) Modulación por desplazamiento por fase
De las siguientes figuras, en la figura (a) podemos ver puntos equidistantes a 45, 135, 225 y 315 grados. La amplitud de un punto es la distancia a partir del origen. Esta figura es una representación de QPSK. A este tipo de diagrama se le conoce como diagrama de constelación. En la figura (b) podemos ver un esquema de modulación con una constelación más densa. Se utilizan 16 combinaciones de amplitudes y fases, por lo que el esquema de modulación se puede usar para transmitir 4 bits por símbolo. Se denomina QAM-16, en donde QAM significa Modulación de Amplitud en Cuadratura (en inglés Quadrature Amplitude Modulatian). La figura (c) es un esquema de modulación todavía más denso con 64 combinaciones distintas, por lo que se pueden transmitir 6 bits por símbolo. Se denomina QAM-64. También se utilizan esquemas QAM más altos. Como podría sospechar de estas constelaciones, es más fácil construir componentes electrónicos para producir símbolos como una combinación de valores en cada eje, que como una combinación de valores de amplitud y fase. Ésta es la razón por la cual los patrones se ven como cuadros en vez de círculos concéntricos.

Multiplexión por división de frecuencia
Los esquemas de modulación que hemos visto nos permiten enviar una señal para transmitir bits a través de un enlace alámbrico o inalámbrico. Sin embargo, la economía de escala desempeña un importante papel en cuanto a la forma en que utilizamos las redes. En esencia, es igual de costoso instalar y mantener una línea de transmisión con un alto ancho de banda que una línea con un bajo ancho de banda entre dos oficinas distintas (es decir, los costos provienen de tener que cavar la zanja y no del tipo de cable o fibra óptica que se va a instalar).
Por ende, se han desarrollado esquemas de multiplexión para compartir líneas entre muchas señales. FDM (Multiplexión por División de Frecuencia, del inglés Frecuency Division Multiplexing) aprovecha la ventaja de la transmisión pasa-banda para compartir un canal. Divide el espectro en bandas de frecuencia, en donde cada usuario tiene posesión exclusiva de cierta banda en la que puede enviar su señal.
Las distintas frecuencias se asignan a distintos canales lógicos (estaciones), cada uno de los cuales opera en una parte del espectro y la separación entre canales es lo bastante grande como para evitar interferencias.
Para un ejemplo más detallado, en la siguiente figura mostramos tres canales telefónicos de calidad de voz, multiplexados mediante FDM. Los filtros limitan el ancho de banda útil a cerca de 3100 Hz por cada canal de calidad de voz. Cuando se multiplexan muchos canales juntos, se asignan 4 000 Hz por canal. Al exceso se le denomina banda de guarda, la cual mantiene los canales bien separados.

MULTIPLEXIÓN POR DIVISIÓN DE FRECUENCIA. (a) Los anchos de banda originales
(b) Los anchos de banda elevados en frecuencias
(c) El canal multiplexado
Este esquema se ha utilizado para mutiplexar llamadas en el sistema telefónico durante muchos años, pero ahora se prefiere más la multiplexión en el tiempo. Sin embargo, FDM se sigue utilizando en las redes telefónicas, así como en las redes celulares, redes inalámbricas terrestres y redes de satélites con un mayor nivel de granularidad. Al enviar datos digitales, es posible dividir el espectro de manera eficiente sin usar bandas de guarda. En OFDM (Multiplexión por División de Frecuencia Ortogonal, del inglés Orthogonal Frequency Division Multiplexing), el ancho de banda del canal se divide en muchas subportadoras que envían
datos de manera independiente. Las subportadoras están empaquetadas estrechamente en el dominio de la frecuencia. Por lo tanto, las señales de cada subportadora se extienden a las subportadoras adyacentes.
Multiplexión por división de tiempo
TDM (Multiplexión por División de Tiempo, del inglés Time Division Multiplexing) es una alternativa a FDM. Aquí, los usuarios toman turnos (rotatorios tipo round-robin) y cada uno recibe periódicamente todo el ancho de banda durante una pequeña ráfaga de tiempo. En la figura 2-27 se muestra un ejemplo de tres flujos multiplexados mediante TDM. Se toman bits de cada flujo de entrada en una ranura de tiempo fija y se envían al flujo agregado. Este flujo opera a una velocidad equivalente a la suma de los flujos individuales. Para que esto funcione, los flujos se deben estar sincronizados en tiempo. Se pueden agregar pequeños intervalos de tiempo de guarda, los cuales son análogos a una banda de guarda de frecuencia, para tener en cuenta las pequeñas variaciones de sincronización. El TDM se utiliza mucho como parte de las redes telefónicas y celulares. Para evitar un punto de confusión, dejemos claro que es muy distinto a la STDM (Multiplexión Estadística por División de Tiempo, del inglés Statistical Time Division Multiplexing). El prefijo “estadística” es para indicar que los flujos individuales contribuyen al flujo multiplexado no en un itinerario fijo, sino con base en la estadística de su demanda. En sí, STDM es otro nombre para la conmutación de paquetes.

7.1.6) Red telefónica publica conmutada
Cuando una compañía u organización cuenta con dos computadoras que se ubican una cerca de la otra y necesitan comunicarse, con frecuencia lo más fácil es tender un cable entre ellas. Las redes LAN funcionan de esta manera. Sin embargo, cuando las distancias son grandes o hay muchas computadoras, o cuando los cables tienen que pasar por un camino público u otra vía pública, los costos de tender cables privados son por lo general prohibitivos. Además, en casi cualquier país del mundo también es ilegal instalar líneas de transmisión privadas a través (o debajo) de una propiedad pública. Por lo tanto, los diseñadores de redes deben depender de las instalaciones de telecomunicaciones existentes. Estas instalaciones, en especial la PSTN (Red Telefónica Pública Conmutada, del inglés Public Switched Telephone Network), por lo general se diseñaron hace muchos años con un objetivo completamente distinto en mente: transmitir la voz humana en una forma más o menos reconocible. Su adaptabilidad para usarse en la comunicación de computadora a computadora con frecuencia es marginal en el mejor de los casos. Para ver el tamaño del problema, considere que un cable común y económico tendido entre dos computadoras puede transferir datos a 1 Gbps o más. En contraste, una línea ADSL común, la ultrarrápida alternativa al módem telefónico, opera a una velocidad aproximada de 1 Mbps. La diferencia entre las dos es como viajar en un avión y dar un tranquilo paseo a pie.
Sin embargo, el sistema telefónico está muy entrelazado con las redes de computadoras (de área amplia), por lo que vale la pena dedicar algo de tiempo para estudiarlo con detalle. El factor limitante para fines de interconexión resulta ser la “última milla” a través de la cual se conectan los clientes, no las troncales y conmutadores dentro de la red telefónica. Esta situación está cambiando debido a la extensión gradual de la fibra óptica y la tecnología digital al borde de la red, pero llevará algo de tiempo y dinero.
Estructura del sistema telefónico
Poco después de que Alexander Graham Bell patentara el teléfono en 1876, hubo una enorme demanda por su nuevo invento. El mercado inicial era para la venta de teléfonos, los cuales se vendían en pares. Al cliente le correspondía tender un cable entre los dos teléfonos. Si el propietario de un teléfono quería hablar a otros n propietarios de teléfonos, tenía que tender cables separados a cada una de las n casas. En menos de un año las ciudades estaban cubiertas de cables que pasaban sobre casas y árboles en un salvaje embrollo. Fue inmediatamente obvio que el modelo de conectar cada teléfono a cada uno de los otros teléfonos, no iba a funcionar. Para su fortuna, Bell había previsto este problema y formó la compañía telefónica Bell, la cual abrió su primera oficina de conmutación (en New Haven, Connecticut) en 1878. La compañía tendía un cable hasta la casa u oficina de cada cliente. Para hacer una llamada, el cliente debía dar vueltas a una manivela en el teléfono para producir un sonido de timbre en la oficina de la compañía telefónica y atraer la atención de una operadora, quien a su vez conectaba en forma manual a la persona que llamaba con la persona que iba a recibir la llamada mediante un cable de puenteo.
Muy pronto surgieron por todas partes oficinas de conmutación de Bell System y la gente quería hacer llamadas de larga distancia entre ciudades, de modo que el Bell System empezó a conectar las oficinas de conmutación. Pronto reapareció el problema original: conectar cada oficina de conmutación con todas las demás mediante un cable entre ellas pronto dejó de ser práctico, por lo que se inventaron las oficinas de conmutación de segundo nivel. Con el tiempo, la jerarquía aumentó a cinco niveles.
Para 1890, las tres principales partes del sistema telefónico estaban en operación: las oficinas de conmutación, los cables entre los clientes y las oficinas de conmutación (a estas alturas eran pares trenzados balanceados y aislados, en vez de cables abiertos con retorno a tierra), y las conexiones de larga distancia entre las oficinas de conmutación. Aunque desde entonces se han realizado mejoras en las tres áreas, el modelo básico del Bell System ha permanecido en esencia intacto durante más de 100 años. La siguiente descripción está muy simplificada, pero logra transmitir la idea esencial. Cada teléfono tiene dos cables de cobre que salen de él y que van directamente a la oficina final más cercana de la compañía telefónica (también se conoce como oficina central local). Por lo general la distancia es de 1 a 10 km, siendo menor en las ciudades que en las áreas rurales. Tan sólo en Estados Unidos hay cerca de 22 000 oficinas finales. Las conexiones de dos cables entre el teléfono de cada suscriptor y la oficina central se conocen en el negocio como lazo local. Si los lazos locales del mundo se estiraran y unieran por los extremos, se extenderían hasta la Luna y
regresarían 1000 veces.
La política de los teléfonos
Durante las décadas anteriores a 1984, el Bell System proporcionaba tanto el servicio local como el de larga distancia en casi todo el territorio de Estados Unidos. En la década de 1970, el gobierno federal estadounidense se convenció de que era un monopolio ilegal y entabló un juicio para dividirlo. El gobierno ganó, y el 1 de enero de 1984, AT&T se dividió en AT&T Long Lines, 23 compañías BOC (Compañías Operativas de Bell, del inglés Bell Operating Companies) y algunas otras partes pequeñas. Las 23 BOC se agruparon en siete BOC regionales (RBOC) para hacerlas económicamente viables. La naturaleza entera de las telecomunicaciones en Estados Unidos se cambió de la noche a la mañana por orden judicial (no por un acto del Congreso). Las especificaciones exactas del desmantelamiento se describieron en el llamado MFJ (Juicio Final Modificado, del inglés Modified Final Judgment), un contrasentido si alguna vez hubo uno (si el juicio se podía modificar, obviamente no era final). Este suceso condujo a un aumento en la competencia, un mejor servicio y tarifas de larga distancia más bajas para los consumidores y las empresas. Sin embargo, los precios del servicio local aumentaron al eliminar los subsidios cruzados de las llamadas de larga distancia, de modo que el servicio local tuvo que independizarse económicamente. Ahora muchos otros países han introducido la competencia por caminos similares.
Algo de relevancia directa para nuestros estudios es que el nuevo marco de trabajo competitivo provocó que se agregara una característica técnica clave a la arquitectura de la red telefónica. Para dejar en claro quiénes podían actuar y cómo, Estados Unidos se dividió en 164 áreas LATA (Áreas de Acceso Local y de Transporte, del inglés Local Access and Transport Areas). A grandes rasgos, una LATA es casi tan grande como el área cubierta por un código de área. Dentro de cada LATA había una LEC (Portadora de Intercambio Local, del inglés Local Exchange Carrier) con un monopolio del servicio tradicional de telefonía dentro de su área. Las LEC más importantes eran las BOC, aunque algunas LATA contenían una o más de las 1 500 compañías telefónicas independientes que operaban como LEC. La nueva característica era que todo el tráfico dentro de las LATA se manejaba a través de un tipo distinto de compañía: una IXC (Portadora entre Centrales, del inglés IntereXchange Carrier). En un principio, AT&T Long Lines era la única IXC seria, pero ahora hay competidores bien establecidos como Verizon y Sprint en el negocio de las IXC. Una de las consideraciones durante la disolución fue asegurar que todas las IXC se tratarían con igualdad en términos de calidad de las líneas, tarifas y cantidad de dígitos que sus clientes tendrían que marcar para usarlas. En la figura 2-31 se ilustra la forma en que se maneja esto. Aquí podemos ver tres LATA de ejemplo, cada una con varias oficinas finales. Las LATA 2 y 3 también tienen una pequeña jerarquía con oficinas tándem (oficinas interurbanas inter-LATA).
Cualquier IXC que desee manejar llamadas que se originen en una LATA puede construir allí una oficina de conmutación conocida como POP (Punto de Presencia, del inglés Point of Presence). Se requiere la LEC para conectar cada IXC con cada oficina final, ya sea de manera directa como en las LATA 1 y 3, o de manera indirecta como en la LATA 2. Asimismo, los términos de la conexión (tanto técnicos como financieros) deben ser idénticos para todas las IXC. De esta forma, este requerimiento permite que un suscriptor en la LATA 1 (por ejemplo) seleccione cuál IXC desea usar para llamar a los suscriptores en la LATA 3.
Cuando una compañía u organización cuenta con dos computadoras que se ubican una cerca de la otra y necesitan comunicarse, con frecuencia lo más fácil es tender un cable entre ellas. Las redes LAN funcionan de esta manera. Sin embargo, cuando las distancias son grandes o hay muchas computadoras, o cuando los cables tienen que pasar por un camino público u otra vía pública, los costos de tender cables privados son por lo general prohibitivos. Además, en casi cualquier país del mundo también es ilegal instalar líneas de transmisión privadas a través (o debajo) de una propiedad pública. Por lo tanto, los diseñadores de redes deben depender de las instalaciones de telecomunicaciones existentes. Estas instalaciones, en especial la PSTN (Red Telefónica Pública Conmutada, del inglés Public Switched Telephone Network), por lo general se diseñaron hace muchos años con un objetivo completamente distinto en mente: transmitir la voz humana en una forma más o menos reconocible. Su adaptabilidad para usarse en la comunicación de computadora a computadora con frecuencia es marginal en el mejor de los casos. Para ver el tamaño del problema, considere que un cable común y económico tendido entre dos computadoras puede transferir datos a 1 Gbps o más. En contraste, una línea ADSL común, la ultrarrápida alternativa al módem telefónico, opera a una velocidad aproximada de 1 Mbps. La diferencia entre las dos es como viajar en un avión y dar un tranquilo paseo a pie.
Sin embargo, el sistema telefónico está muy entrelazado con las redes de computadoras (de área amplia), por lo que vale la pena dedicar algo de tiempo para estudiarlo con detalle. El factor limitante para fines de interconexión resulta ser la “última milla” a través de la cual se conectan los clientes, no las troncales y conmutadores dentro de la red telefónica. Esta situación está cambiando debido a la extensión gradual de la fibra óptica y la tecnología digital al borde de la red, pero llevará algo de tiempo y dinero.
Estructura del sistema telefónico
Poco después de que Alexander Graham Bell patentara el teléfono en 1876, hubo una enorme demanda por su nuevo invento. El mercado inicial era para la venta de teléfonos, los cuales se vendían en pares. Al cliente le correspondía tender un cable entre los dos teléfonos. Si el propietario de un teléfono quería hablar a otros n propietarios de teléfonos, tenía que tender cables separados a cada una de las n casas. En menos de un año las ciudades estaban cubiertas de cables que pasaban sobre casas y árboles en un salvaje embrollo. Fue inmediatamente obvio que el modelo de conectar cada teléfono a cada uno de los otros teléfonos, no iba a funcionar. Para su fortuna, Bell había previsto este problema y formó la compañía telefónica Bell, la cual abrió su primera oficina de conmutación (en New Haven, Connecticut) en 1878. La compañía tendía un cable hasta la casa u oficina de cada cliente. Para hacer una llamada, el cliente debía dar vueltas a una manivela en el teléfono para producir un sonido de timbre en la oficina de la compañía telefónica y atraer la atención de una operadora, quien a su vez conectaba en forma manual a la persona que llamaba con la persona que iba a recibir la llamada mediante un cable de puenteo.
Muy pronto surgieron por todas partes oficinas de conmutación de Bell System y la gente quería hacer llamadas de larga distancia entre ciudades, de modo que el Bell System empezó a conectar las oficinas de conmutación. Pronto reapareció el problema original: conectar cada oficina de conmutación con todas las demás mediante un cable entre ellas pronto dejó de ser práctico, por lo que se inventaron las oficinas de conmutación de segundo nivel. Con el tiempo, la jerarquía aumentó a cinco niveles.
Para 1890, las tres principales partes del sistema telefónico estaban en operación: las oficinas de conmutación, los cables entre los clientes y las oficinas de conmutación (a estas alturas eran pares trenzados balanceados y aislados, en vez de cables abiertos con retorno a tierra), y las conexiones de larga distancia entre las oficinas de conmutación. Aunque desde entonces se han realizado mejoras en las tres áreas, el modelo básico del Bell System ha permanecido en esencia intacto durante más de 100 años. La siguiente descripción está muy simplificada, pero logra transmitir la idea esencial. Cada teléfono tiene dos cables de cobre que salen de él y que van directamente a la oficina final más cercana de la compañía telefónica (también se conoce como oficina central local). Por lo general la distancia es de 1 a 10 km, siendo menor en las ciudades que en las áreas rurales. Tan sólo en Estados Unidos hay cerca de 22 000 oficinas finales. Las conexiones de dos cables entre el teléfono de cada suscriptor y la oficina central se conocen en el negocio como lazo local. Si los lazos locales del mundo se estiraran y unieran por los extremos, se extenderían hasta la Luna y
regresarían 1000 veces.
La política de los teléfonos
Durante las décadas anteriores a 1984, el Bell System proporcionaba tanto el servicio local como el de larga distancia en casi todo el territorio de Estados Unidos. En la década de 1970, el gobierno federal estadounidense se convenció de que era un monopolio ilegal y entabló un juicio para dividirlo. El gobierno ganó, y el 1 de enero de 1984, AT&T se dividió en AT&T Long Lines, 23 compañías BOC (Compañías Operativas de Bell, del inglés Bell Operating Companies) y algunas otras partes pequeñas. Las 23 BOC se agruparon en siete BOC regionales (RBOC) para hacerlas económicamente viables. La naturaleza entera de las telecomunicaciones en Estados Unidos se cambió de la noche a la mañana por orden judicial (no por un acto del Congreso). Las especificaciones exactas del desmantelamiento se describieron en el llamado MFJ (Juicio Final Modificado, del inglés Modified Final Judgment), un contrasentido si alguna vez hubo uno (si el juicio se podía modificar, obviamente no era final). Este suceso condujo a un aumento en la competencia, un mejor servicio y tarifas de larga distancia más bajas para los consumidores y las empresas. Sin embargo, los precios del servicio local aumentaron al eliminar los subsidios cruzados de las llamadas de larga distancia, de modo que el servicio local tuvo que independizarse económicamente. Ahora muchos otros países han introducido la competencia por caminos similares.
Algo de relevancia directa para nuestros estudios es que el nuevo marco de trabajo competitivo provocó que se agregara una característica técnica clave a la arquitectura de la red telefónica. Para dejar en claro quiénes podían actuar y cómo, Estados Unidos se dividió en 164 áreas LATA (Áreas de Acceso Local y de Transporte, del inglés Local Access and Transport Areas). A grandes rasgos, una LATA es casi tan grande como el área cubierta por un código de área. Dentro de cada LATA había una LEC (Portadora de Intercambio Local, del inglés Local Exchange Carrier) con un monopolio del servicio tradicional de telefonía dentro de su área. Las LEC más importantes eran las BOC, aunque algunas LATA contenían una o más de las 1 500 compañías telefónicas independientes que operaban como LEC. La nueva característica era que todo el tráfico dentro de las LATA se manejaba a través de un tipo distinto de compañía: una IXC (Portadora entre Centrales, del inglés IntereXchange Carrier). En un principio, AT&T Long Lines era la única IXC seria, pero ahora hay competidores bien establecidos como Verizon y Sprint en el negocio de las IXC. Una de las consideraciones durante la disolución fue asegurar que todas las IXC se tratarían con igualdad en términos de calidad de las líneas, tarifas y cantidad de dígitos que sus clientes tendrían que marcar para usarlas. En la figura 2-31 se ilustra la forma en que se maneja esto. Aquí podemos ver tres LATA de ejemplo, cada una con varias oficinas finales. Las LATA 2 y 3 también tienen una pequeña jerarquía con oficinas tándem (oficinas interurbanas inter-LATA).
Cualquier IXC que desee manejar llamadas que se originen en una LATA puede construir allí una oficina de conmutación conocida como POP (Punto de Presencia, del inglés Point of Presence). Se requiere la LEC para conectar cada IXC con cada oficina final, ya sea de manera directa como en las LATA 1 y 3, o de manera indirecta como en la LATA 2. Asimismo, los términos de la conexión (tanto técnicos como financieros) deben ser idénticos para todas las IXC. De esta forma, este requerimiento permite que un suscriptor en la LATA 1 (por ejemplo) seleccione cuál IXC desea usar para llamar a los suscriptores en la LATA 3.
7.1.7) Sistema de telefonía móvil
El sistema de telefonía móvil se utiliza para la comunicación de datos y voz de área amplia. Los teléfonos móviles (también conocidos como teléfonos celulares) han pasado por tres generaciones distintas, conocidas comúnmente como 1G, 2G y 3G. Las generaciones son:
Aunque la mayor parte de nuestro estudio se enfoca en la tecnología de estos sistemas, es interesante observar cómo las decisiones políticas y de mercado pueden tener un enorme impacto. El primer sistema móvil fue inventado en Estados Unidos por AT&T y se hizo obligatorio en todo el país mediante la FCC. Como resultado, todo Estados Unidos tenía un solo sistema (analógico), por lo que un teléfono móvil comprado en California también funcionaba en Nueva York. En contraste, cuando los teléfonos móviles llegaron a Europa cada país desarrolló su propio sistema, lo cual resultó en un fiasco. Europa aprendió de su error y cuando llegó el sistema digital, las PTT gubernamentales se reunieron y crearon estándares para un solo sistema (GSM), de modo que cualquier teléfono móvil europeo pudiera funcionar en cualquier parte de Europa. Para entonces, Estados Unidos había decidido que el gobierno no debería participar en el negocio de la estandarización, así que dejó el sistema digital a cargo del mercado. Debido a esta decisión, los distintos fabricantes de equipos produjeron tipos diferentes de teléfonos móviles. Como consecuencia, en Estados Unidos se implementaron dos tipos principales (y totalmente incompatibles) de sistemas de telefonía móvil digital, así como algunos otros sistemas menos importantes.
Teléfonos móviles de primera generación (1G): voz analógica
Dejemos a un lado los aspectos políticos y de marketing de los teléfonos móviles. Ahora analizaremos la tecnología, empezando con el primero de los sistemas. Los radioteléfonos móviles se utilizaban esporádicamente para comunicación marítima y militar durante las primeras décadas del siglo xx. En 1946 se estableció el primer sistema de teléfonos instalados en autos en St. Louis. Este sistema utilizaba un solo transmisor grande colocado en la parte superior de un edificio alto y tenía un solo canal, el cual servía tanto para enviar como para recibir. Para hablar, el usuario tenía que oprimir un botón para habilitar el transmisor y deshabilitar el receptor. Dichos sistemas, conocidos como sistemas de oprimir para hablar, se instalaron en varias ciudades desde finales de la década de 1950. El radio de banda civil (CB), los taxis y las patrullas utilizan con frecuencia esta tecnología.
En la década de 1960, se instaló el IMTS (Sistema Mejorado de Telefonía Móvil, del inglés Improved Mobile Telephone System). También utilizaba un transmisor de alta potencia (200 watts) en la parte superior de una colina, pero tenía dos frecuencias: una para enviar y otra para recibir. De esta forma, ya no era necesario el botón de oprimir para hablar. Como toda la comunicación de los teléfonos móviles entraba por un canal distinto al de las señales de salida, los usuarios móviles no se podían escuchar entre sí (a diferencia del sistema de oprimir para hablar que utilizaban los taxis).
El IMTS manejaba 23 canales dispersos desde 150 MHz hasta 450 MHz. Debido al pequeño número de canales, a veces los usuarios tenían que esperar mucho tiempo antes de obtener el tono de marcar. Además, debido a la gran potencia de los transmisores en la cima de las colinas, los sistemas adyacentes tenían que estar separados varios cientos de kilómetros para evitar interferencia. En sí, el sistema no era práctico debido a su limitada capacidad.
Todo cambió con el AMPS (Sistema Avanzado de Telefonía Móvil, del inglés Advanced Mobile Phone System), inventado por los Laboratorios Bell e instalado por primera vez en Estados Unidos en 1982. También se utilizó en Inglaterra, donde se llamaba TACS, y en Japón, donde se llamaba MCS-L1. El AMPS se retiró formalmente en 2008, pero lo analizaremos para comprender el contexto de los sistemas 2G y 3G que se basaron en él para mejorar.
El sistema AMPS utiliza FDM para separar los canales. Emplea 832 canales full-dúplex, cada uno de los cuales consiste en un par de canales simplex. Este arreglo se conoce como FDD (Duplexión por División de Frecuencia, del inglés Frequency Division Duplex). Los 832 canales simplex de 824 a 849 MHz se utilizan para la transmisión del móvil a la estación base, y los 832 canales simplex de 869 a 894 MHz se utilizan para transmisiones de la estación base al móvil. Cada uno de estos canales simplex tiene una amplitud de 30 kHz. Los 832 canales se dividen en cuatro categorías. Canales de control (base a móvil) se utilizan para administrar el sistema. Canales de localización (base a móvil) alertan a los usuarios móviles que tienen llamadas. Canales de acceso (bidireccional) se usan para establecimiento de llamadas y asignación de canales. Por último, los canales de datos (bidireccional) transportan voz, fax o datos. Puesto que no se pueden reutilizar las mismas frecuencias en las celdas cercanas y se reservan 21 canales en cada celda para actividades de control, el número actual de canales de voz disponibles por celda es mucho menor de 832, por lo general cerca de 45.
Teléfonos móviles de segunda generación (2G): voz digital
La primera generación de teléfonos móviles era analógica; la segunda, es digital. El cambio a digital tiene varias ventajas. Ofrece un aumento en la capacidad al permitir la digitalización y compresión de las señales de voz. Mejora la seguridad al permitir cifrar las señales de voz y de control. Esto a su vez impide los fraudes y el espionaje, ya sean producto de una exploración intencional o debido a los ecos de otras llamadas que se producen por la propagación de RF. Por último, permite el uso de nuevos servicios, como la mensajería de texto.
Así como en la primera generación no hubo una estandarización a nivel mundial, tampoco la segunda cuenta con ello. Se desarrollaron varios sistemas distintos, de los cuales tres se han implementado ampliamente.
D-AMPS (Sistema Avanzado de Telefonía Móvil Digital, del inglés Digital Advanced Mobile Phone System) es una versión digital de AMPS que coexiste con este sistema y usa TDM para colocar múltiples llamadas en el mismo canal de frecuencia. Se describe en el estándar internacional IS-54 y en su sucesor, IS-136. GSM (Sistema Global para Comunicaciones Móviles, del inglés Global System for Mobile communications) se ha establecido como el sistema dominante, y aunque tardó en popularizarse en Estados Unidos ahora se utiliza casi en cualquier parte del mundo. Al igual que D-AMPS, GSM se basa en una mezcla de FDM y TDM. El sistema CDMA (Acceso Múltiple por División de Código, del inglés Code Division Multiple Access), que se describe en el estándar internacional IS-95, es un tipo de sistema completamente distinto y no se basa en FDM ni en TDM. Aunque CDMA no se ha convertido en el sistema 2G dominante, su tecnología forma la base para los sistemas 3G. Algunas veces se utiliza también el nombre PCS (Servicios de Comunicaciones Personales, del inglés Personal Communications Services) en la literatura para indicar un sistema de segunda generación (es decir, digital). En un principio indicaba que un teléfono móvil usaba la banda de 1900 MHz, pero en la actualidad es raro hacer esta distinción.
Teléfonos móviles de tercera generación (3G): voz y datos digitales
La primera generación de teléfonos móviles era de voz analógica y la segunda generación era de voz digital. La tercera generación de teléfonos móviles, o 3G como se le conoce comúnmente, es de voz y datos digitales.
Hay varios factores que impulsan la industria. Primero, el tráfico de datos ya es mayor que el tráfico de voz en la red fija y está creciendo en forma exponencial, mientras que el tráfico de voz es en esencia fijo. Muchos expertos en la industria esperan también que el tráfico de datos domine al tráfico de voz en los dispositivos móviles muy pronto. Segundo, las industrias de telefonía, entretenimiento y computadoras se han vuelto digitales y están convergiendo con rapidez. Muchas personas suspiran por los dispositivos ligeros y portátiles que actúan como teléfono, reproductor de música y de video, terminal de correo electrónico, interfaz web, máquina de juegos y mucho más, todo con conectividad inalámbrica mundial a Internet con un alto ancho de banda.
El iPhone de Apple es un buen ejemplo de este tipo de dispositivo 3G. Con él, las personas se envician en los servicios de datos inalámbricos y, en consecuencia, los volúmenes de datos inalámbricos de AT&T se elevan estrepitosamente junto con la popularidad del iPhone. El problema es que este teléfono utiliza una red 2.5G (una red 2G mejorada, pero no es una verdadera red 3G) y no hay suficiente capacidad de datos para mantener felices a los usuarios. El único fin de telefonía móvil 3G es proveer suficiente ancho de banda inalámbrico para mantener felices a estos futuros usuarios.
La ITU trató de ser un poco más específica sobre esta visión allá por el año de 1992. Emitió un plano detallado para alcanzar este sueño, llamado IMT-2000. IMT son las siglas en inglés de Telecomunicaciones Móviles Internacionales.
El sistema de telefonía móvil se utiliza para la comunicación de datos y voz de área amplia. Los teléfonos móviles (también conocidos como teléfonos celulares) han pasado por tres generaciones distintas, conocidas comúnmente como 1G, 2G y 3G. Las generaciones son:
- Voz analógica.
- Voz digital.
- Voz y datos digitales (Internet, correo electrónico, etcétera).
Aunque la mayor parte de nuestro estudio se enfoca en la tecnología de estos sistemas, es interesante observar cómo las decisiones políticas y de mercado pueden tener un enorme impacto. El primer sistema móvil fue inventado en Estados Unidos por AT&T y se hizo obligatorio en todo el país mediante la FCC. Como resultado, todo Estados Unidos tenía un solo sistema (analógico), por lo que un teléfono móvil comprado en California también funcionaba en Nueva York. En contraste, cuando los teléfonos móviles llegaron a Europa cada país desarrolló su propio sistema, lo cual resultó en un fiasco. Europa aprendió de su error y cuando llegó el sistema digital, las PTT gubernamentales se reunieron y crearon estándares para un solo sistema (GSM), de modo que cualquier teléfono móvil europeo pudiera funcionar en cualquier parte de Europa. Para entonces, Estados Unidos había decidido que el gobierno no debería participar en el negocio de la estandarización, así que dejó el sistema digital a cargo del mercado. Debido a esta decisión, los distintos fabricantes de equipos produjeron tipos diferentes de teléfonos móviles. Como consecuencia, en Estados Unidos se implementaron dos tipos principales (y totalmente incompatibles) de sistemas de telefonía móvil digital, así como algunos otros sistemas menos importantes.
Teléfonos móviles de primera generación (1G): voz analógica
Dejemos a un lado los aspectos políticos y de marketing de los teléfonos móviles. Ahora analizaremos la tecnología, empezando con el primero de los sistemas. Los radioteléfonos móviles se utilizaban esporádicamente para comunicación marítima y militar durante las primeras décadas del siglo xx. En 1946 se estableció el primer sistema de teléfonos instalados en autos en St. Louis. Este sistema utilizaba un solo transmisor grande colocado en la parte superior de un edificio alto y tenía un solo canal, el cual servía tanto para enviar como para recibir. Para hablar, el usuario tenía que oprimir un botón para habilitar el transmisor y deshabilitar el receptor. Dichos sistemas, conocidos como sistemas de oprimir para hablar, se instalaron en varias ciudades desde finales de la década de 1950. El radio de banda civil (CB), los taxis y las patrullas utilizan con frecuencia esta tecnología.
En la década de 1960, se instaló el IMTS (Sistema Mejorado de Telefonía Móvil, del inglés Improved Mobile Telephone System). También utilizaba un transmisor de alta potencia (200 watts) en la parte superior de una colina, pero tenía dos frecuencias: una para enviar y otra para recibir. De esta forma, ya no era necesario el botón de oprimir para hablar. Como toda la comunicación de los teléfonos móviles entraba por un canal distinto al de las señales de salida, los usuarios móviles no se podían escuchar entre sí (a diferencia del sistema de oprimir para hablar que utilizaban los taxis).
El IMTS manejaba 23 canales dispersos desde 150 MHz hasta 450 MHz. Debido al pequeño número de canales, a veces los usuarios tenían que esperar mucho tiempo antes de obtener el tono de marcar. Además, debido a la gran potencia de los transmisores en la cima de las colinas, los sistemas adyacentes tenían que estar separados varios cientos de kilómetros para evitar interferencia. En sí, el sistema no era práctico debido a su limitada capacidad.
Todo cambió con el AMPS (Sistema Avanzado de Telefonía Móvil, del inglés Advanced Mobile Phone System), inventado por los Laboratorios Bell e instalado por primera vez en Estados Unidos en 1982. También se utilizó en Inglaterra, donde se llamaba TACS, y en Japón, donde se llamaba MCS-L1. El AMPS se retiró formalmente en 2008, pero lo analizaremos para comprender el contexto de los sistemas 2G y 3G que se basaron en él para mejorar.
El sistema AMPS utiliza FDM para separar los canales. Emplea 832 canales full-dúplex, cada uno de los cuales consiste en un par de canales simplex. Este arreglo se conoce como FDD (Duplexión por División de Frecuencia, del inglés Frequency Division Duplex). Los 832 canales simplex de 824 a 849 MHz se utilizan para la transmisión del móvil a la estación base, y los 832 canales simplex de 869 a 894 MHz se utilizan para transmisiones de la estación base al móvil. Cada uno de estos canales simplex tiene una amplitud de 30 kHz. Los 832 canales se dividen en cuatro categorías. Canales de control (base a móvil) se utilizan para administrar el sistema. Canales de localización (base a móvil) alertan a los usuarios móviles que tienen llamadas. Canales de acceso (bidireccional) se usan para establecimiento de llamadas y asignación de canales. Por último, los canales de datos (bidireccional) transportan voz, fax o datos. Puesto que no se pueden reutilizar las mismas frecuencias en las celdas cercanas y se reservan 21 canales en cada celda para actividades de control, el número actual de canales de voz disponibles por celda es mucho menor de 832, por lo general cerca de 45.
Teléfonos móviles de segunda generación (2G): voz digital
La primera generación de teléfonos móviles era analógica; la segunda, es digital. El cambio a digital tiene varias ventajas. Ofrece un aumento en la capacidad al permitir la digitalización y compresión de las señales de voz. Mejora la seguridad al permitir cifrar las señales de voz y de control. Esto a su vez impide los fraudes y el espionaje, ya sean producto de una exploración intencional o debido a los ecos de otras llamadas que se producen por la propagación de RF. Por último, permite el uso de nuevos servicios, como la mensajería de texto.
Así como en la primera generación no hubo una estandarización a nivel mundial, tampoco la segunda cuenta con ello. Se desarrollaron varios sistemas distintos, de los cuales tres se han implementado ampliamente.
D-AMPS (Sistema Avanzado de Telefonía Móvil Digital, del inglés Digital Advanced Mobile Phone System) es una versión digital de AMPS que coexiste con este sistema y usa TDM para colocar múltiples llamadas en el mismo canal de frecuencia. Se describe en el estándar internacional IS-54 y en su sucesor, IS-136. GSM (Sistema Global para Comunicaciones Móviles, del inglés Global System for Mobile communications) se ha establecido como el sistema dominante, y aunque tardó en popularizarse en Estados Unidos ahora se utiliza casi en cualquier parte del mundo. Al igual que D-AMPS, GSM se basa en una mezcla de FDM y TDM. El sistema CDMA (Acceso Múltiple por División de Código, del inglés Code Division Multiple Access), que se describe en el estándar internacional IS-95, es un tipo de sistema completamente distinto y no se basa en FDM ni en TDM. Aunque CDMA no se ha convertido en el sistema 2G dominante, su tecnología forma la base para los sistemas 3G. Algunas veces se utiliza también el nombre PCS (Servicios de Comunicaciones Personales, del inglés Personal Communications Services) en la literatura para indicar un sistema de segunda generación (es decir, digital). En un principio indicaba que un teléfono móvil usaba la banda de 1900 MHz, pero en la actualidad es raro hacer esta distinción.
Teléfonos móviles de tercera generación (3G): voz y datos digitales
La primera generación de teléfonos móviles era de voz analógica y la segunda generación era de voz digital. La tercera generación de teléfonos móviles, o 3G como se le conoce comúnmente, es de voz y datos digitales.
Hay varios factores que impulsan la industria. Primero, el tráfico de datos ya es mayor que el tráfico de voz en la red fija y está creciendo en forma exponencial, mientras que el tráfico de voz es en esencia fijo. Muchos expertos en la industria esperan también que el tráfico de datos domine al tráfico de voz en los dispositivos móviles muy pronto. Segundo, las industrias de telefonía, entretenimiento y computadoras se han vuelto digitales y están convergiendo con rapidez. Muchas personas suspiran por los dispositivos ligeros y portátiles que actúan como teléfono, reproductor de música y de video, terminal de correo electrónico, interfaz web, máquina de juegos y mucho más, todo con conectividad inalámbrica mundial a Internet con un alto ancho de banda.
El iPhone de Apple es un buen ejemplo de este tipo de dispositivo 3G. Con él, las personas se envician en los servicios de datos inalámbricos y, en consecuencia, los volúmenes de datos inalámbricos de AT&T se elevan estrepitosamente junto con la popularidad del iPhone. El problema es que este teléfono utiliza una red 2.5G (una red 2G mejorada, pero no es una verdadera red 3G) y no hay suficiente capacidad de datos para mantener felices a los usuarios. El único fin de telefonía móvil 3G es proveer suficiente ancho de banda inalámbrico para mantener felices a estos futuros usuarios.
La ITU trató de ser un poco más específica sobre esta visión allá por el año de 1992. Emitió un plano detallado para alcanzar este sueño, llamado IMT-2000. IMT son las siglas en inglés de Telecomunicaciones Móviles Internacionales.
7.2) Capa de enlace de datos
Este estudio se enfoca en los algoritmos para lograr una comunicación confiable y eficiente de unidades completas de información llamadas tramas (en vez de bits individuales, como en la capa física) entre dos máquinas adyacentes. Por adyacente, queremos decir que las dos máquinas están conectadas mediante un canal de comunicaciones que actúa de manera conceptual como un alambre (por ejemplo, un cable coaxial, una línea telefónica o un canal inalámbrico). La propiedad esencial de un canal que lo hace asemejarse a un “alambre” es que los bits se entregan exactamente en el mismo orden en que se enviaron.
Por desgracia, en ocaciones los canales de comunicación cometen errores. Además, sólo tienen una tasa de transmisión de datos finita y hay un retardo de propagación distinto de cero entre el momento en que se envía un bit y el momento en que se recibe. Estas limitaciones tienen implicaciones importantes para la eficiencia de la transferencia de datos. Los protocolos usados para comunicaciones deben considerar todos estos factores.
7.2.1) Cuestiones de diseño de la capa de enlace de datos
La capa de enlace de datos utiliza los servicios de la capa física para enviar y recibir bits a través de los canales de comunicación. Tiene varias funciones específicas, entre las que se incluyen:
Para cumplir con estas metas, la capa de enlace de datos toma los paquetes que obtiene de la capa de red y los encapsula en tramas para transmitirlos. Cada trama contiene un encabezado, un campo de carga útil (payload) para almacenar el paquete y un terminador. El manejo de las tramas es la tarea más importante de la capa de enlace de datos.
Servicios proporcionados a la capa de red
La función de la capa de enlace de datos es proveer servicios a la capa de red. El servicio principal es la transferencia de datos de la capa de red en la máquina de origen, a la capa de red en la máquina de destino. En la capa de red de la máquina de origen está una entidad, llamada proceso, que entrega algunos bits a la capa de enlace de datos para que los transmita al destino. La tarea de la capa de enlace de datos es transmitir los bits a la máquina de destino, de modo que se puedan entregar a la capa de red de esa máquina.
La capa de enlace de datos puede diseñarse para ofrecer varios servicios. Los servicios reales ofrecidos varían de un protocolo a otro. Tres posibilidades razonables que normalmente se proporcionan son:
El servicio sin conexión ni confirmación de recepción consiste en hacer que la máquina de origen envíe tramas independientes a la máquina de destino sin que ésta confirme la recepción. Ethernet es un buen ejemplo de una capa de enlace de datos que provee esta clase de servicio. No se establece una conexión lógica de antemano ni se libera después. Si se pierde una trama debido a ruido en la línea, en la capa de datos no se realiza ningún intento por detectar la pérdida o recuperarse de ella. Esta clase de servicio es apropiada cuando la tasa de error es muy baja, de modo que la recuperación se deja a las capas superiores. También es apropiada para el tráfico en tiempo real, como el de voz, en donde es peor tener retraso en los datos que errores en ellos.
El siguiente paso en términos de confiabilidad es el servicio sin conexión con confirmación de recepción. Cuando se ofrece este servicio tampoco se utilizan conexiones lógicas, pero se confirma de manera individual la recepción de cada trama enviada. De esta manera, el emisor sabe si la trama llegó bien o se perdió. Si no ha llegado en un intervalo especificado, se puede enviar de nuevo. Este servicio es útil en canales no confiables,
como los de los sistemas inalámbricos. 802.11 (WiFi) es un buen ejemplo de esta clase de servicio.
Entramado
Para proveer servicio a la capa de red, la capa de enlace de datos debe usar el servicio que la capa física le proporciona. Lo que hace la capa física es aceptar un flujo de bits puros y tratar de entregarlo al destino. Si el canal es ruidoso, como en la mayoría de los enlaces inalámbricos y en algunos alámbricos, la capa física agregará cierta redundancia a sus señales para reducir la tasa de error de bits a un nivel tolerable. Sin embargo, no se garantiza que el flujo de bits recibido por la capa de enlace de datos esté libre de errores.
Algunos bits pueden tener distintos valores y la cantidad de bits recibidos puede ser menor, igual o mayor que la cantidad de bits transmitidos. Es responsabilidad de la capa de enlace de datos detectar y, de ser necesario, corregir los errores. El método común es que la capa de enlace de datos divida el flujo de bits en tramas discretas, calcule un token corto conocido como suma de verificación para cada trama, e incluya esa suma de verificación en la trama al momento de transmitirla (más adelante en este capítulo analizaremos los algoritmos de suma de verificación). Cuando una trama llega al destino, se recalcula la suma de verificación. Si la nueva suma de verificación calculada es distinta de la contenida en la trama, la capa de enlace de datos sabe que ha ocurrido un error y toma las medidas necesarias para manejarlo (por ejemplo, desecha la trama errónea y es posible que también devuelva un informe de error).
Es más difícil dividir el flujo de bits en tramas de lo que parece a simple vista. Un buen diseño debe facilitar a un receptor el proceso de encontrar el inicio de las nuevas tramas al tiempo que utiliza una pequeña parte del ancho de banda del canal. En esta sección veremos cuatro métodos:
El primer método de entramado se vale de un campo en el encabezado para especificar el número de bytes en la trama. Cuando la capa de enlace de datos del destino ve el conteo de bytes, sabe cuántos bytes siguen y, por lo tanto, dónde concluye la trama. Esta técnica se muestra en la figura 3-3(a) para cuatro tramas pequeñas de ejemplo con 5, 5, 8 y 8 bytes de longitud, respectivamente. El problema con este algoritmo es que el conteo se puede alterar debido a un error de transmisión.

El segundo método de entramado evita el problema de volver a sincronizar nuevamente después de un error al hacer que cada trama inicie y termine con bytes especiales. Con frecuencia se utiliza el mismo byte, denominado byte bandera, como delimitador inicial y final.
Dos bytes bandera consecutivos señalan el final de una trama y el inicio de la siguiente. De esta forma, si el receptor pierde alguna vez la sincronización, todo lo que tiene que hacer es buscar dos bytes bandera para encontrar el fin de la trama actual y el inicio de la siguiente. Sin embargo, aún queda un problema que tenemos que resolver. Se puede dar el caso de que el byte bandera aparezca en los datos, en especial cuando se transmiten datos binarios como fotografías o canciones.
Esta situación interferiría con el entramado. Una forma de resolver este problema es hacer que la capa de enlace de datos del emisor inserte un byte de escape especial (ESC) justo antes de cada byte bandera “accidental” en los datos. De esta forma es posible diferenciar un byte bandera del entramado de uno en los datos mediante la ausencia o presencia de un byte de escape antes del byte bandera. La capa de enlace de datos del lado receptor quita el byte de escape antes de entregar los datos a la capa de red. Esta técnica se llama relleno de bytes.

El esquema de relleno de bytes que se muestra en la figura anterior es una ligera simplificación del esquema empleado en el protocolo PPP (Protocolo Punto a Punto, del inglés Point-to-Point Protocol), que se utiliza para transmitir paquetes a través de los enlaces de comunicación. Analizaremos el protocolo PPP casi al final de este capítulo.
El tercer método de delimitar el flujo de bits resuelve una desventaja del relleno de bytes: que está obligado a usar bytes de 8 bits. También se puede realizar el entramado a nivel de bit, de modo que las tramas puedan contener un número arbitrario de bits compuesto por unidades de cualquier tamaño. Esto se desarrolló para el protocolo HDLC (Control de Enlace de Datos de Alto Nivel, del inglés High-level Data Link Control ), que alguna vez fue muy popular. Cada trama empieza y termina con un patrón de bits especial, 01111110 o 0x7E en hexadecimal. Este patrón es un byte bandera. Cada vez que la capa de enlace de datos del emisor encuentra cinco bits 1 consecutivos en los datos, inserta automáticamente un 0 como relleno en el flujo de bits de salida. Este relleno de bits es análogo al relleno de bytes, en el cual se inserta un byte de escape en el flujo de caracteres de salida antes de un byte bandera en los datos. Además asegura una densidad mínima de transiciones que ayudan a la capa física a mantener la sincronización. La tecnología USB (Bus Serie Universal, del inglés Universal Serial Bus) usa relleno de bits por esta razón.
La capa de enlace de datos utiliza los servicios de la capa física para enviar y recibir bits a través de los canales de comunicación. Tiene varias funciones específicas, entre las que se incluyen:
- Proporcionar a la capa de red una interfaz de servicio bien definida.
- Manejar los errores de transmisión.
- Regular el flujo de datos para que los emisores rápidos no saturen a los receptores lentos.
Para cumplir con estas metas, la capa de enlace de datos toma los paquetes que obtiene de la capa de red y los encapsula en tramas para transmitirlos. Cada trama contiene un encabezado, un campo de carga útil (payload) para almacenar el paquete y un terminador. El manejo de las tramas es la tarea más importante de la capa de enlace de datos.
Servicios proporcionados a la capa de red
La función de la capa de enlace de datos es proveer servicios a la capa de red. El servicio principal es la transferencia de datos de la capa de red en la máquina de origen, a la capa de red en la máquina de destino. En la capa de red de la máquina de origen está una entidad, llamada proceso, que entrega algunos bits a la capa de enlace de datos para que los transmita al destino. La tarea de la capa de enlace de datos es transmitir los bits a la máquina de destino, de modo que se puedan entregar a la capa de red de esa máquina.
La capa de enlace de datos puede diseñarse para ofrecer varios servicios. Los servicios reales ofrecidos varían de un protocolo a otro. Tres posibilidades razonables que normalmente se proporcionan son:
- Servicio sin conexión ni confirmación de recepción.
- Servicio sin conexión con confirmación de recepción.
- Servicio orientado a conexión con confirmación de recepción.
El servicio sin conexión ni confirmación de recepción consiste en hacer que la máquina de origen envíe tramas independientes a la máquina de destino sin que ésta confirme la recepción. Ethernet es un buen ejemplo de una capa de enlace de datos que provee esta clase de servicio. No se establece una conexión lógica de antemano ni se libera después. Si se pierde una trama debido a ruido en la línea, en la capa de datos no se realiza ningún intento por detectar la pérdida o recuperarse de ella. Esta clase de servicio es apropiada cuando la tasa de error es muy baja, de modo que la recuperación se deja a las capas superiores. También es apropiada para el tráfico en tiempo real, como el de voz, en donde es peor tener retraso en los datos que errores en ellos.
El siguiente paso en términos de confiabilidad es el servicio sin conexión con confirmación de recepción. Cuando se ofrece este servicio tampoco se utilizan conexiones lógicas, pero se confirma de manera individual la recepción de cada trama enviada. De esta manera, el emisor sabe si la trama llegó bien o se perdió. Si no ha llegado en un intervalo especificado, se puede enviar de nuevo. Este servicio es útil en canales no confiables,
como los de los sistemas inalámbricos. 802.11 (WiFi) es un buen ejemplo de esta clase de servicio.
Entramado
Para proveer servicio a la capa de red, la capa de enlace de datos debe usar el servicio que la capa física le proporciona. Lo que hace la capa física es aceptar un flujo de bits puros y tratar de entregarlo al destino. Si el canal es ruidoso, como en la mayoría de los enlaces inalámbricos y en algunos alámbricos, la capa física agregará cierta redundancia a sus señales para reducir la tasa de error de bits a un nivel tolerable. Sin embargo, no se garantiza que el flujo de bits recibido por la capa de enlace de datos esté libre de errores.
Algunos bits pueden tener distintos valores y la cantidad de bits recibidos puede ser menor, igual o mayor que la cantidad de bits transmitidos. Es responsabilidad de la capa de enlace de datos detectar y, de ser necesario, corregir los errores. El método común es que la capa de enlace de datos divida el flujo de bits en tramas discretas, calcule un token corto conocido como suma de verificación para cada trama, e incluya esa suma de verificación en la trama al momento de transmitirla (más adelante en este capítulo analizaremos los algoritmos de suma de verificación). Cuando una trama llega al destino, se recalcula la suma de verificación. Si la nueva suma de verificación calculada es distinta de la contenida en la trama, la capa de enlace de datos sabe que ha ocurrido un error y toma las medidas necesarias para manejarlo (por ejemplo, desecha la trama errónea y es posible que también devuelva un informe de error).
Es más difícil dividir el flujo de bits en tramas de lo que parece a simple vista. Un buen diseño debe facilitar a un receptor el proceso de encontrar el inicio de las nuevas tramas al tiempo que utiliza una pequeña parte del ancho de banda del canal. En esta sección veremos cuatro métodos:
- Conteo de bytes.
- Bytes bandera con relleno de bytes.
- Bits bandera con relleno de bits.
- Violaciones de codificación de la capa física.
El primer método de entramado se vale de un campo en el encabezado para especificar el número de bytes en la trama. Cuando la capa de enlace de datos del destino ve el conteo de bytes, sabe cuántos bytes siguen y, por lo tanto, dónde concluye la trama. Esta técnica se muestra en la figura 3-3(a) para cuatro tramas pequeñas de ejemplo con 5, 5, 8 y 8 bytes de longitud, respectivamente. El problema con este algoritmo es que el conteo se puede alterar debido a un error de transmisión.

Un flujo de bytes. a)Sin errores b)Con un error
El segundo método de entramado evita el problema de volver a sincronizar nuevamente después de un error al hacer que cada trama inicie y termine con bytes especiales. Con frecuencia se utiliza el mismo byte, denominado byte bandera, como delimitador inicial y final.
Dos bytes bandera consecutivos señalan el final de una trama y el inicio de la siguiente. De esta forma, si el receptor pierde alguna vez la sincronización, todo lo que tiene que hacer es buscar dos bytes bandera para encontrar el fin de la trama actual y el inicio de la siguiente. Sin embargo, aún queda un problema que tenemos que resolver. Se puede dar el caso de que el byte bandera aparezca en los datos, en especial cuando se transmiten datos binarios como fotografías o canciones.
Esta situación interferiría con el entramado. Una forma de resolver este problema es hacer que la capa de enlace de datos del emisor inserte un byte de escape especial (ESC) justo antes de cada byte bandera “accidental” en los datos. De esta forma es posible diferenciar un byte bandera del entramado de uno en los datos mediante la ausencia o presencia de un byte de escape antes del byte bandera. La capa de enlace de datos del lado receptor quita el byte de escape antes de entregar los datos a la capa de red. Esta técnica se llama relleno de bytes.

a) Una trama delimitada por bytes bandera. b) Cuatros ejemplos
de secuencias de bytes antes y después del relleno de bytes
El esquema de relleno de bytes que se muestra en la figura anterior es una ligera simplificación del esquema empleado en el protocolo PPP (Protocolo Punto a Punto, del inglés Point-to-Point Protocol), que se utiliza para transmitir paquetes a través de los enlaces de comunicación. Analizaremos el protocolo PPP casi al final de este capítulo.
El tercer método de delimitar el flujo de bits resuelve una desventaja del relleno de bytes: que está obligado a usar bytes de 8 bits. También se puede realizar el entramado a nivel de bit, de modo que las tramas puedan contener un número arbitrario de bits compuesto por unidades de cualquier tamaño. Esto se desarrolló para el protocolo HDLC (Control de Enlace de Datos de Alto Nivel, del inglés High-level Data Link Control ), que alguna vez fue muy popular. Cada trama empieza y termina con un patrón de bits especial, 01111110 o 0x7E en hexadecimal. Este patrón es un byte bandera. Cada vez que la capa de enlace de datos del emisor encuentra cinco bits 1 consecutivos en los datos, inserta automáticamente un 0 como relleno en el flujo de bits de salida. Este relleno de bits es análogo al relleno de bytes, en el cual se inserta un byte de escape en el flujo de caracteres de salida antes de un byte bandera en los datos. Además asegura una densidad mínima de transiciones que ayudan a la capa física a mantener la sincronización. La tecnología USB (Bus Serie Universal, del inglés Universal Serial Bus) usa relleno de bits por esta razón.
7.2.2) Protocolos elementales de enlace de datos
Para comenzar, supongamos que las capas física, de enlace de datos y de red son procesos independientes que se comunican pasando mensajes de un lado a otro. El proceso de la capa física y una parte del proceso de la capa de enlace de datos se ejecutan en hardware dedicado, conocido como NIC (Tarjeta de Interfaz de Red, del inglés Network Interface Card). El resto del proceso de la capa de enlace y el proceso de la capa de red se ejecutan en la CPU principal como parte del sistema operativo, en donde el software para el proceso de la capa de enlace a menudo toma la forma de un controlador de dispositivo. Sin embargo, también puede haber otras implementaciones (por ejemplo, tres procesos descargados a un dispositivo de hardware dedicado, conocido como acelerador de red, o tres procesos ejecutándose en la CPU principal en un radio definido por software). En realidad, la implementación preferida cambia de una década a otra con las concesiones tecnológicas. En cualquier caso, el hecho de tratar las tres capas como procesos independientes hace más nítido el análisis en el terreno conceptual y también sirve para enfatizar la independencia de las capas.
En lo que concierne a la capa de enlace de datos, el paquete que recibe a través de la interfaz desde la capa de red sólo es de datos, los cuales deben ser entregados bit por bit a la capa de red del destino.
El hecho de que la capa de red del destino pueda interpretar parte del paquete como un encabezado no es de importancia para la capa de enlace de datos.
Cuando la capa de enlace de datos acepta un paquete, lo encapsula en una trama agregándole un encabezado y un terminador de enlace de datos. Por lo tanto, una trama consiste en un paquete incrustado, con cierta información de control (en el encabezado) y una suma de verificación (en el terminador). A continuación la trama se transmite a la capa de enlace de datos de la otra máquina.
Un protocolo simplex utópico
Como ejemplo inicial consideraremos un protocolo que es lo más sencillo posible, por la posibilidad de que algo salga mal. Los datos son transmitidos en una sola dirección; las capas de red tanto del emisor como del receptor siempre están listas. Podemos ignorar el tiempo de procesamiento. Hay un espacio infinito de búfer disponible. Y lo mejor de todo, el canal de comunicación entre las capas de enlace de datos nunca daña ni pierde las tramas. Este protocolo completamente irreal, al que apodaremos “utopía”, es simplemente para mostrar la estructura básica en la que nos basaremos.
El protocolo consiste en dos procedimientos diferentes, un emisor y un receptor. El emisor se ejecuta en la capa de enlace de datos de la máquina de origen y el receptor se ejecuta en la capa de enlace de datos de la máquina de destino. No se usan números de secuencia ni confirmaciones de recepción, por lo que no se necesita MAX_SEQ. El único tipo de evento posible es frame_arrival (es decir, la llegada de una trama sin daños).
El emisor está en un ciclo while infinito que sólo envía datos a la línea tan rápido como puede. El cuerpo del ciclo consiste en tres acciones: obtener un paquete de la (siempre dispuesta) capa de red, construir una trama de salida usando la variable s y enviar la trama a su destino. Este protocolo sólo utiliza el campo info de la trama, pues los demás campos tienen que ver con el control de errores y de flujo, y aquí no hay restricciones de este tipo.
El receptor también es sencillo. Al principio espera que algo ocurra, siendo la única posibilidad la llegada de una trama sin daños. En algún momento llega la trama, el procedimiento wait_for_event regresa y event contiene el valor frame_arrival (que de todos modos se ignora). La llamada a from_physical_layer elimina la trama recién llegada del búfer de hardware y la coloca en la variable r, en donde el código receptor pueda obtenerla. Por último, la parte de los datos se pasa a la capa de red y la capa de enlace de datos se retira para esperar la siguiente trama, para lo cual se suspende efectivamente hasta que ésta llega.
El protocolo utópico es irreal, ya que no maneja el control de flujo ni la corrección de errores. Su procesamiento se asemeja al de un servicio sin conexión ni confirmación de recepción que depende de las capas más altas para resolver estos problemas, aun cuando un servicio sin conexión ni confirmación de recepción realizaría cierta detección de errores.

Protocolo simplex de parada y espera para un canal libre de errores
Ahora debemos lidiar con el problema principal de evitar que el emisor sature al receptor enviando tramas a una mayor velocidad de la que este último puede procesarlas. Esta situación puede ocurrir con facilidad en la práctica, por lo que es de extrema importancia evitarla. Sin embargo, aún existe el supuesto de que el canal está libre de errores y el tráfico de datos sigue siendo simplex.
Una solución es construir un receptor lo suficientemente poderoso como para procesar un flujo continuo de tramas, una tras otra sin interrupción (lo equivalente sería definir la capa de enlace de modo que fuera lo bastante lenta como para que el receptor pudiera mantenerse a la par). Debe tener suficiente capacidad en el búfer y de procesamiento como para operar a la tasa de transmisión de la línea; asimismo debe ser capaz de pasar las tramas que se reciben en la capa de red con la rapidez suficiente. Sin embargo, ésta es una solución para el peor de los casos. Requiere hardware dedicado y se pueden desperdiciar recursos si el enlace se usa poco. Además, sólo cambia el problema de tratar con un emisor demasiado rápido a otra parte; en este caso, a la capa de red.
Una solución más general para este dilema es hacer que el receptor proporcione retroalimentación al emisor. Tras haber pasado un paquete a su capa de red, el receptor regresa al emisor una pequeña trama ficticia que, de hecho, autoriza al emisor para que transmita la siguiente trama. Después de enviar una trama, el protocolo exige que el emisor espere hasta que llegue la pequeña trama ficticia. Los protocolos en los que el emisor envía una trama y luego espera una confirmación de recepción antes de continuar se denominan de parada y espera.

Protocolo simplex de parada y espera para un canal ruidoso
Ahora consideremos la situación normal de un canal de comunicación que comete errores. Las tramas pueden llegar dañadas o se pueden perder por completo. Sin embargo, suponemos que si una trama se daña en tránsito, el hardware del receptor detectará esto cuando calcule la suma de verificación. Si la trama está dañada de tal manera que pese a ello la suma de verificación sea correcta (una ocurrencia muy poco probable), este protocolo (y todos los demás) puede fallar (es decir, tal vez entregue un paquete incorrecto a la capa de red).
A primera vista puede parecer que funcionaría una variación del protocolo 2: agregar un temporizador.
El emisor podría enviar una trama, pero el receptor sólo enviaría una trama de confirmación de recepción si los datos llegaran correctamente. Si llegara una trama dañada al receptor, se desecharía. Después de un tiempo el temporizador del emisor expiraría y éste enviaría la trama otra vez. Este proceso se repetiría hasta que la trama por fin llegara intacta. Pero el esquema anterior tiene un defecto fatal. Piense en el problema y trate de descubrir lo que podría salir mal antes de continuar leyendo.
Para ver lo que puede resultar mal, recuerde que el objetivo de la capa de enlace de datos es proporcionar una comunicación transparente y libre de errores entre los procesos de las capas de red. La capa de red de la máquina A pasa una serie de paquetes a su capa de enlace de datos, la cual debe asegurar que se entregue una serie de paquetes idénticos a la capa de red de la máquina B a través de su capa de enlace de datos. En particular, la capa de red en B no tiene manera de saber si el paquete se perdió o duplicó, por lo que la capa de enlace de datos debe garantizar que ninguna combinación de errores de transmisión, por improbables que sean, pudiera causar la entrega de un paquete duplicado a la capa de red.
Los protocolos en los que el emisor espera una confirmación de recepción positiva antes de avanzar al siguiente elemento de datos se conocen comúnmente como ARQ (Solicitud Automática de Repetición, del inglés Automatic Repeat reQuest) o PAR (Confirmación de Recepción Positiva con Retransmisión, del inglés Positive Acknowledgement with Retransmission). Al igual que el protocolo 2, éste también transmite datos en una sola dirección.


Para comenzar, supongamos que las capas física, de enlace de datos y de red son procesos independientes que se comunican pasando mensajes de un lado a otro. El proceso de la capa física y una parte del proceso de la capa de enlace de datos se ejecutan en hardware dedicado, conocido como NIC (Tarjeta de Interfaz de Red, del inglés Network Interface Card). El resto del proceso de la capa de enlace y el proceso de la capa de red se ejecutan en la CPU principal como parte del sistema operativo, en donde el software para el proceso de la capa de enlace a menudo toma la forma de un controlador de dispositivo. Sin embargo, también puede haber otras implementaciones (por ejemplo, tres procesos descargados a un dispositivo de hardware dedicado, conocido como acelerador de red, o tres procesos ejecutándose en la CPU principal en un radio definido por software). En realidad, la implementación preferida cambia de una década a otra con las concesiones tecnológicas. En cualquier caso, el hecho de tratar las tres capas como procesos independientes hace más nítido el análisis en el terreno conceptual y también sirve para enfatizar la independencia de las capas.
En lo que concierne a la capa de enlace de datos, el paquete que recibe a través de la interfaz desde la capa de red sólo es de datos, los cuales deben ser entregados bit por bit a la capa de red del destino.
El hecho de que la capa de red del destino pueda interpretar parte del paquete como un encabezado no es de importancia para la capa de enlace de datos.
Cuando la capa de enlace de datos acepta un paquete, lo encapsula en una trama agregándole un encabezado y un terminador de enlace de datos. Por lo tanto, una trama consiste en un paquete incrustado, con cierta información de control (en el encabezado) y una suma de verificación (en el terminador). A continuación la trama se transmite a la capa de enlace de datos de la otra máquina.
Un protocolo simplex utópico
Como ejemplo inicial consideraremos un protocolo que es lo más sencillo posible, por la posibilidad de que algo salga mal. Los datos son transmitidos en una sola dirección; las capas de red tanto del emisor como del receptor siempre están listas. Podemos ignorar el tiempo de procesamiento. Hay un espacio infinito de búfer disponible. Y lo mejor de todo, el canal de comunicación entre las capas de enlace de datos nunca daña ni pierde las tramas. Este protocolo completamente irreal, al que apodaremos “utopía”, es simplemente para mostrar la estructura básica en la que nos basaremos.
El protocolo consiste en dos procedimientos diferentes, un emisor y un receptor. El emisor se ejecuta en la capa de enlace de datos de la máquina de origen y el receptor se ejecuta en la capa de enlace de datos de la máquina de destino. No se usan números de secuencia ni confirmaciones de recepción, por lo que no se necesita MAX_SEQ. El único tipo de evento posible es frame_arrival (es decir, la llegada de una trama sin daños).
El emisor está en un ciclo while infinito que sólo envía datos a la línea tan rápido como puede. El cuerpo del ciclo consiste en tres acciones: obtener un paquete de la (siempre dispuesta) capa de red, construir una trama de salida usando la variable s y enviar la trama a su destino. Este protocolo sólo utiliza el campo info de la trama, pues los demás campos tienen que ver con el control de errores y de flujo, y aquí no hay restricciones de este tipo.
El receptor también es sencillo. Al principio espera que algo ocurra, siendo la única posibilidad la llegada de una trama sin daños. En algún momento llega la trama, el procedimiento wait_for_event regresa y event contiene el valor frame_arrival (que de todos modos se ignora). La llamada a from_physical_layer elimina la trama recién llegada del búfer de hardware y la coloca en la variable r, en donde el código receptor pueda obtenerla. Por último, la parte de los datos se pasa a la capa de red y la capa de enlace de datos se retira para esperar la siguiente trama, para lo cual se suspende efectivamente hasta que ésta llega.
El protocolo utópico es irreal, ya que no maneja el control de flujo ni la corrección de errores. Su procesamiento se asemeja al de un servicio sin conexión ni confirmación de recepción que depende de las capas más altas para resolver estos problemas, aun cuando un servicio sin conexión ni confirmación de recepción realizaría cierta detección de errores.

Protocolo simplex de parada y espera para un canal libre de errores
Ahora debemos lidiar con el problema principal de evitar que el emisor sature al receptor enviando tramas a una mayor velocidad de la que este último puede procesarlas. Esta situación puede ocurrir con facilidad en la práctica, por lo que es de extrema importancia evitarla. Sin embargo, aún existe el supuesto de que el canal está libre de errores y el tráfico de datos sigue siendo simplex.
Una solución es construir un receptor lo suficientemente poderoso como para procesar un flujo continuo de tramas, una tras otra sin interrupción (lo equivalente sería definir la capa de enlace de modo que fuera lo bastante lenta como para que el receptor pudiera mantenerse a la par). Debe tener suficiente capacidad en el búfer y de procesamiento como para operar a la tasa de transmisión de la línea; asimismo debe ser capaz de pasar las tramas que se reciben en la capa de red con la rapidez suficiente. Sin embargo, ésta es una solución para el peor de los casos. Requiere hardware dedicado y se pueden desperdiciar recursos si el enlace se usa poco. Además, sólo cambia el problema de tratar con un emisor demasiado rápido a otra parte; en este caso, a la capa de red.
Una solución más general para este dilema es hacer que el receptor proporcione retroalimentación al emisor. Tras haber pasado un paquete a su capa de red, el receptor regresa al emisor una pequeña trama ficticia que, de hecho, autoriza al emisor para que transmita la siguiente trama. Después de enviar una trama, el protocolo exige que el emisor espere hasta que llegue la pequeña trama ficticia. Los protocolos en los que el emisor envía una trama y luego espera una confirmación de recepción antes de continuar se denominan de parada y espera.

Protocolo simplex de parada y espera para un canal ruidoso
Ahora consideremos la situación normal de un canal de comunicación que comete errores. Las tramas pueden llegar dañadas o se pueden perder por completo. Sin embargo, suponemos que si una trama se daña en tránsito, el hardware del receptor detectará esto cuando calcule la suma de verificación. Si la trama está dañada de tal manera que pese a ello la suma de verificación sea correcta (una ocurrencia muy poco probable), este protocolo (y todos los demás) puede fallar (es decir, tal vez entregue un paquete incorrecto a la capa de red).
A primera vista puede parecer que funcionaría una variación del protocolo 2: agregar un temporizador.
El emisor podría enviar una trama, pero el receptor sólo enviaría una trama de confirmación de recepción si los datos llegaran correctamente. Si llegara una trama dañada al receptor, se desecharía. Después de un tiempo el temporizador del emisor expiraría y éste enviaría la trama otra vez. Este proceso se repetiría hasta que la trama por fin llegara intacta. Pero el esquema anterior tiene un defecto fatal. Piense en el problema y trate de descubrir lo que podría salir mal antes de continuar leyendo.
Para ver lo que puede resultar mal, recuerde que el objetivo de la capa de enlace de datos es proporcionar una comunicación transparente y libre de errores entre los procesos de las capas de red. La capa de red de la máquina A pasa una serie de paquetes a su capa de enlace de datos, la cual debe asegurar que se entregue una serie de paquetes idénticos a la capa de red de la máquina B a través de su capa de enlace de datos. En particular, la capa de red en B no tiene manera de saber si el paquete se perdió o duplicó, por lo que la capa de enlace de datos debe garantizar que ninguna combinación de errores de transmisión, por improbables que sean, pudiera causar la entrega de un paquete duplicado a la capa de red.
Los protocolos en los que el emisor espera una confirmación de recepción positiva antes de avanzar al siguiente elemento de datos se conocen comúnmente como ARQ (Solicitud Automática de Repetición, del inglés Automatic Repeat reQuest) o PAR (Confirmación de Recepción Positiva con Retransmisión, del inglés Positive Acknowledgement with Retransmission). Al igual que el protocolo 2, éste también transmite datos en una sola dirección.


7.2.3) Protocolos de ventana deslizante
En los protocolos anteriores, las tramas de datos se transmitían en una sola dirección. En la mayoría de las situaciones prácticas existe la necesidad de transmitir datos en ambas direcciones. Una manera de lograr una transmisión de datos full-dúplex es tener dos instancias de uno de los protocolos anteriores, cada uno de los cuales debe usar un enlace separado para el tráfico de datos simplex (en distintas direcciones). A su vez, cada enlace se compone de un canal de “ida” (para los datos) y de un canal de “retorno” (para las confirmaciones de recepción). En ambos casos se desperdicia la capacidad del canal de retorno casi por completo. Una mejor idea es utilizar el mismo enlace para datos en ambas direcciones. Después de todo, en los protocolos 2 y 3 ya se usaba para transmitir tramas en ambos sentidos, y por lo general el canal de retorno tiene la misma capacidad que el canal de ida. En este modelo, las tramas de datos de A a B se entremezclan con las tramas de confirmación de recepción de A a B. Si analizamos el campo kind en el encabezado de una trama entrante, el receptor puede saber si la trama es de datos o de confirmación de recepción.
Aunque intercalar datos y tramas de control en el mismo enlace es una gran mejora respecto al uso de dos enlaces físicos separados, es posible realizar otra mejora. Cuando llega una trama de datos, en lugar de enviar de inmediato una trama de control independiente, el receptor se aguanta y espera hasta que la capa de red le pasa el siguiente paquete. La confirmación de recepción se anexa a la trama de datos de salida (mediante el uso del campo ack del encabezado de la trama). En efecto, la confirmación de recepción viaja gratuitamente en la siguiente trama de datos de salida. La técnica de retardar temporalmente las confirmaciones de recepción salientes para que puedan viajar en la siguiente trama de datos de salida se conoce como superposición (piggybacking).
La principal ventaja de usar la superposición en lugar de tener tramas de confirmación de recepción independientes, es un mejor aprovechamiento del ancho de banda disponible del canal. El campo ack del encabezado de la trama ocupa sólo unos cuantos bits, mientras que una trama separada requeriría de un encabezado, la confirmación de recepción y una suma de verificación. Además, el envío de menos tramas casi siempre representa una carga de procesamiento más ligera en el receptor. En el siguiente protocolo que vamos a examinar, el campo de superposición sólo ocupa 1 bit en el encabezado de trama. Pocas veces ocupa más de unos cuantos bits.
Los siguientes tres protocolos son bidireccionales y pertenecen a una clase llamada protocolos de ventana deslizante. Los tres difieren entre ellos en términos de eficiencia, complejidad y requerimientos de búfer, como veremos más adelante. En ellos, al igual que en todos los protocolos de ventana deslizante, cada trama de salida contiene un número de secuencia que va desde 0 hasta algún número máximo. Por lo general este valor máximo es 2n 2 1, por lo que el número de secuencia encaja perfectamente en un campo de n bits. El protocolo de ventana deslizante de parada y espera utiliza n 5 1 y restringe los números de secuencia de 0 y 1, pero las versiones más sofisticadas pueden utilizar un n arbitrario.
La esencia de todos los protocolos de ventana deslizante es que, en cualquier instante, el emisor mantiene un conjunto de números de secuencia que corresponde a las tramas que tiene permitido enviar. Se dice que estas tramas caen dentro de la ventana emisora. De manera similar, el receptor mantiene una ventana receptora correspondiente al conjunto de tramas que tiene permitido aceptar. La ventana del emisor y la del receptor no necesitan tener los mismos límites inferior y superior, ni siquiera el mismo tamaño. En algunos protocolos las ventanas son de tamaño fijo, pero en otros pueden aumentar o reducir su tamaño con el transcurso del tiempo, a medida que se envían y reciben las tramas.
Un protocolo de ventana deslizante de un bit
Antes de tratar el caso general, examinemos un protocolo de ventana deslizante con un tamaño máximo de ventana de 1. Tal protocolo utiliza parada y espera, ya que el emisor envía una trama y espera su confirmación de recepción antes de transmitir la siguiente.
Como los demás, comienza por definir algunas variables. Next_frame_to_send indica qué trama está tratando de enviar el emisor. Asimismo, frame_expected indica qué trama espera el receptor. En ambos casos, 0 y 1 son las únicas posibilidades. En circunstancias normales, una de las dos capas de enlace de datos es la que comienza a transmitir la primera trama. En otras palabras, sólo uno de los programas de capa de enlace de datos debe contener las llamadas de procedimiento to_physical_layer y start_timer fuera del ciclo principal. La máquina que inicia obtiene el primer paquete de su capa de red, construye una trama a partir de él y la envía. Al llegar esta (o cualquier) trama, la capa de enlace de datos del receptor la verifica para saber si es un duplicado, igual que en el protocolo 3. Si la trama es la esperada, se pasa a la capa de red y la ventana del receptor se recorre hacia arriba. El campo de confirmación de recepción contiene el número de la última trama recibida sin error. Si este número concuerda con el de secuencia de la trama que está tratando de enviar el emisor, éste sabe que ha terminado con la trama almacenada en el búfer (buffer) y que puede obtener el siguiente paquete de su capa de red. Si el número de secuencia no concuerda, debe seguir tratando de enviar la misma trama. Cada vez que se recibe una trama, también se regresa una.
Ahora examinemos el protocolo 4 para ver qué tan flexible es ante circunstancias patológicas. Suponga que la computadora A trata de enviar su trama 0 a la computadora B y que B trata de enviar su trama 0 a A. Suponga que A envía una trama a B, pero que el intervalo de temporización de A es un poco corto. En consecuencia, el temporizador de A se podría agotar repetidamente, enviando una serie de tramas idénticas, todas con seq = 0 y ack = 1.


En los protocolos anteriores, las tramas de datos se transmitían en una sola dirección. En la mayoría de las situaciones prácticas existe la necesidad de transmitir datos en ambas direcciones. Una manera de lograr una transmisión de datos full-dúplex es tener dos instancias de uno de los protocolos anteriores, cada uno de los cuales debe usar un enlace separado para el tráfico de datos simplex (en distintas direcciones). A su vez, cada enlace se compone de un canal de “ida” (para los datos) y de un canal de “retorno” (para las confirmaciones de recepción). En ambos casos se desperdicia la capacidad del canal de retorno casi por completo. Una mejor idea es utilizar el mismo enlace para datos en ambas direcciones. Después de todo, en los protocolos 2 y 3 ya se usaba para transmitir tramas en ambos sentidos, y por lo general el canal de retorno tiene la misma capacidad que el canal de ida. En este modelo, las tramas de datos de A a B se entremezclan con las tramas de confirmación de recepción de A a B. Si analizamos el campo kind en el encabezado de una trama entrante, el receptor puede saber si la trama es de datos o de confirmación de recepción.
Aunque intercalar datos y tramas de control en el mismo enlace es una gran mejora respecto al uso de dos enlaces físicos separados, es posible realizar otra mejora. Cuando llega una trama de datos, en lugar de enviar de inmediato una trama de control independiente, el receptor se aguanta y espera hasta que la capa de red le pasa el siguiente paquete. La confirmación de recepción se anexa a la trama de datos de salida (mediante el uso del campo ack del encabezado de la trama). En efecto, la confirmación de recepción viaja gratuitamente en la siguiente trama de datos de salida. La técnica de retardar temporalmente las confirmaciones de recepción salientes para que puedan viajar en la siguiente trama de datos de salida se conoce como superposición (piggybacking).
La principal ventaja de usar la superposición en lugar de tener tramas de confirmación de recepción independientes, es un mejor aprovechamiento del ancho de banda disponible del canal. El campo ack del encabezado de la trama ocupa sólo unos cuantos bits, mientras que una trama separada requeriría de un encabezado, la confirmación de recepción y una suma de verificación. Además, el envío de menos tramas casi siempre representa una carga de procesamiento más ligera en el receptor. En el siguiente protocolo que vamos a examinar, el campo de superposición sólo ocupa 1 bit en el encabezado de trama. Pocas veces ocupa más de unos cuantos bits.
Los siguientes tres protocolos son bidireccionales y pertenecen a una clase llamada protocolos de ventana deslizante. Los tres difieren entre ellos en términos de eficiencia, complejidad y requerimientos de búfer, como veremos más adelante. En ellos, al igual que en todos los protocolos de ventana deslizante, cada trama de salida contiene un número de secuencia que va desde 0 hasta algún número máximo. Por lo general este valor máximo es 2n 2 1, por lo que el número de secuencia encaja perfectamente en un campo de n bits. El protocolo de ventana deslizante de parada y espera utiliza n 5 1 y restringe los números de secuencia de 0 y 1, pero las versiones más sofisticadas pueden utilizar un n arbitrario.
La esencia de todos los protocolos de ventana deslizante es que, en cualquier instante, el emisor mantiene un conjunto de números de secuencia que corresponde a las tramas que tiene permitido enviar. Se dice que estas tramas caen dentro de la ventana emisora. De manera similar, el receptor mantiene una ventana receptora correspondiente al conjunto de tramas que tiene permitido aceptar. La ventana del emisor y la del receptor no necesitan tener los mismos límites inferior y superior, ni siquiera el mismo tamaño. En algunos protocolos las ventanas son de tamaño fijo, pero en otros pueden aumentar o reducir su tamaño con el transcurso del tiempo, a medida que se envían y reciben las tramas.
Un protocolo de ventana deslizante de un bit
Antes de tratar el caso general, examinemos un protocolo de ventana deslizante con un tamaño máximo de ventana de 1. Tal protocolo utiliza parada y espera, ya que el emisor envía una trama y espera su confirmación de recepción antes de transmitir la siguiente.
Como los demás, comienza por definir algunas variables. Next_frame_to_send indica qué trama está tratando de enviar el emisor. Asimismo, frame_expected indica qué trama espera el receptor. En ambos casos, 0 y 1 son las únicas posibilidades. En circunstancias normales, una de las dos capas de enlace de datos es la que comienza a transmitir la primera trama. En otras palabras, sólo uno de los programas de capa de enlace de datos debe contener las llamadas de procedimiento to_physical_layer y start_timer fuera del ciclo principal. La máquina que inicia obtiene el primer paquete de su capa de red, construye una trama a partir de él y la envía. Al llegar esta (o cualquier) trama, la capa de enlace de datos del receptor la verifica para saber si es un duplicado, igual que en el protocolo 3. Si la trama es la esperada, se pasa a la capa de red y la ventana del receptor se recorre hacia arriba. El campo de confirmación de recepción contiene el número de la última trama recibida sin error. Si este número concuerda con el de secuencia de la trama que está tratando de enviar el emisor, éste sabe que ha terminado con la trama almacenada en el búfer (buffer) y que puede obtener el siguiente paquete de su capa de red. Si el número de secuencia no concuerda, debe seguir tratando de enviar la misma trama. Cada vez que se recibe una trama, también se regresa una.
Ahora examinemos el protocolo 4 para ver qué tan flexible es ante circunstancias patológicas. Suponga que la computadora A trata de enviar su trama 0 a la computadora B y que B trata de enviar su trama 0 a A. Suponga que A envía una trama a B, pero que el intervalo de temporización de A es un poco corto. En consecuencia, el temporizador de A se podría agotar repetidamente, enviando una serie de tramas idénticas, todas con seq = 0 y ack = 1.


7.2.4) Conmutación de la capa de enlace de datos
Muchas organizaciones tienen varias redes LAN y desean interconectarlas. ¿No sería conveniente si tan sólo pudiéramos unir las redes LAN para formar una LAN más grande? De hecho, este tipo de redes se puede conectar mediante dispositivos llamados puentes. Los switches de Ethernet son un nombre moderno para los puentes; proveen una funcionalidad que va más allá de los hubs de Ethernet clásica y Ethernet para facilitar la unión de varias redes LAN en una red más grande y veloz. Utilizaremos los términos “puente” y “switch” para indicar lo mismo. Los puentes operan en la capa de enlace de datos, por lo que examinan las direcciones de la capa de enlace de datos para reenviar tramas. Como no tienen que examinar el campo de carga útil de las ramas que reenvían, pueden manejar paquetes IP al igual que otros tipos de paquetes, como Apple- Talk. En contraste, los enrutadores examinan las direcciones de los paquetes y realizan su trabajo de enrutamiento con base en ellas, por lo que sólo funcionan con los protocolos para los cuales se diseñaron.
Usos de los puentes
Antes de entrar de lleno a la tecnología de los puentes, veamos algunas situaciones comunes en las cuales se utilizan los puentes. Mencionaremos tres razones por las cuales una sola organización podría terminar trabajando con varias LAN.
En primer lugar, muchas universidades y departamentos corporativos tienen sus propias redes LAN para conectar sus propias computadoras personales, servidores y dispositivos como impresoras. Dado que los objetivos de los distintos departamentos difieren, los distintos departamentos pueden establecer diferentes redes LAN, sin importarles lo que hagan los demás departamentos. Pero tarde o temprano surge la necesidad de interacción, y aquí es donde entran los puentes. En este ejemplo surgieron múltiples redes LAN debido a la autonomía de sus propietarios.
En segundo lugar, la organización puede estar distribuida geográficamente en varios edificios, separados por distancias considerables. Puede ser más económico tener redes LAN independientes en cada edificio y conectarlas mediante puentes y unos cuantos enlaces de fibra óptica de larga distancia que tender todos los cables hacia un solo switch central. Incluso si es fácil tender los cables, existen límites en cuanto a sus longitudes (por ejemplo, 200 m para Gigabit Ethernet de par trenzado). La red no funcionaría con cables más largos debido a la excesiva atenuación de la señal, o al retardo de viaje redondo. La única solución es dividir la LAN e instalar puentes para unir las piezas y poder incrementar la distancia física total que se puede cubrir.
En tercer lugar, tal vez sea necesario dividir lo que por lógica es una sola LAN en varias redes LAN individuales (conectadas mediante puentes) para manejar la carga. Por ejemplo, en muchas universidades grandes, hay miles de estaciones de trabajo disponibles para los estudiantes y el cuerpo docente. Las empresas también pueden tener miles de empleados. La escala de este sistema hace imposible poner todas las estaciones de trabajo en una sola LAN; hay muchas más computadoras que puertos en cualquier hub Ethernet y más estaciones de lo que se permite en una sola Ethernet clásica.
Incluso si fuera posible cablear todas las estaciones de trabajo juntas, al colocar más estaciones en un hub Ethernet o en una red Ethernet clásica no se agrega capacidad. Todas las estaciones comparten la misma cantidad fija de ancho de banda. Entre más estaciones haya, menor será el ancho de banda promedio por estación.
Para que estos beneficios pudieran estar fácilmente disponibles, los puentes ideales tendrían que ser totalmente transparentes. Debería ser posible comprar los puentes, conectar los cables de LAN en los puentes y que todo funcionara a la perfección en un instante. No debería existir la necesidad de cambios de hardware o de software, ni de configurar switches de direcciones o descargar tablas de enrutamiento o parámetros, nada de eso. Simplemente conectar los cables y seguir con nuestras actividades cotidianas. Lo que es más, la operación de las redes LAN existentes no se debería ver afectada por los puentes para nada. En cuanto a las estaciones, no debería haber ninguna diferencia observable en cuanto a si son parte o no de una LAN con puente. Debería ser igual de fácil mover estaciones alrededor de una LAN con puente que moverlas en una sola LAN.
Puentes de aprendizaje
Los puentes se desarrollaron cuando se usaban redes Ethernet clásicas, por lo que a menudo se muestran en topologías con cables multiderivación. Sin embargo, todas las topologías en la actualidad están compuestas de cables punto a punto y switches. Los puentes funcionan de la misma forma en ambas configuraciones. Todas las estaciones conectadas al mismo puerto en un puente pertenecen al mismo dominio de colisión, y éste es distinto al dominio de colisión para otros puertos. Si hay más de una estación, como en una red Ethernet clásica, un hub o un enlace half-dúplex, se utiliza el protocolo CSMA/CD para enviar tramas.
Sin embargo, hay una diferencia en cuanto a la forma en que se construyen las redes LAN con puentes. Para conectar redes LAN multiderivación con puentes, se agrega un puente como una nueva estación en cada LAN multiderivación, como en la figura 4-41(a). Para conectar redes LAN punto a punto mediante puentes, los hubs se conectan a un puente o, lo que es preferible, se reemplazan con un puente para incrementar el desempeño.
Muchas organizaciones tienen varias redes LAN y desean interconectarlas. ¿No sería conveniente si tan sólo pudiéramos unir las redes LAN para formar una LAN más grande? De hecho, este tipo de redes se puede conectar mediante dispositivos llamados puentes. Los switches de Ethernet son un nombre moderno para los puentes; proveen una funcionalidad que va más allá de los hubs de Ethernet clásica y Ethernet para facilitar la unión de varias redes LAN en una red más grande y veloz. Utilizaremos los términos “puente” y “switch” para indicar lo mismo. Los puentes operan en la capa de enlace de datos, por lo que examinan las direcciones de la capa de enlace de datos para reenviar tramas. Como no tienen que examinar el campo de carga útil de las ramas que reenvían, pueden manejar paquetes IP al igual que otros tipos de paquetes, como Apple- Talk. En contraste, los enrutadores examinan las direcciones de los paquetes y realizan su trabajo de enrutamiento con base en ellas, por lo que sólo funcionan con los protocolos para los cuales se diseñaron.
Usos de los puentes
Antes de entrar de lleno a la tecnología de los puentes, veamos algunas situaciones comunes en las cuales se utilizan los puentes. Mencionaremos tres razones por las cuales una sola organización podría terminar trabajando con varias LAN.
En primer lugar, muchas universidades y departamentos corporativos tienen sus propias redes LAN para conectar sus propias computadoras personales, servidores y dispositivos como impresoras. Dado que los objetivos de los distintos departamentos difieren, los distintos departamentos pueden establecer diferentes redes LAN, sin importarles lo que hagan los demás departamentos. Pero tarde o temprano surge la necesidad de interacción, y aquí es donde entran los puentes. En este ejemplo surgieron múltiples redes LAN debido a la autonomía de sus propietarios.
En segundo lugar, la organización puede estar distribuida geográficamente en varios edificios, separados por distancias considerables. Puede ser más económico tener redes LAN independientes en cada edificio y conectarlas mediante puentes y unos cuantos enlaces de fibra óptica de larga distancia que tender todos los cables hacia un solo switch central. Incluso si es fácil tender los cables, existen límites en cuanto a sus longitudes (por ejemplo, 200 m para Gigabit Ethernet de par trenzado). La red no funcionaría con cables más largos debido a la excesiva atenuación de la señal, o al retardo de viaje redondo. La única solución es dividir la LAN e instalar puentes para unir las piezas y poder incrementar la distancia física total que se puede cubrir.
En tercer lugar, tal vez sea necesario dividir lo que por lógica es una sola LAN en varias redes LAN individuales (conectadas mediante puentes) para manejar la carga. Por ejemplo, en muchas universidades grandes, hay miles de estaciones de trabajo disponibles para los estudiantes y el cuerpo docente. Las empresas también pueden tener miles de empleados. La escala de este sistema hace imposible poner todas las estaciones de trabajo en una sola LAN; hay muchas más computadoras que puertos en cualquier hub Ethernet y más estaciones de lo que se permite en una sola Ethernet clásica.
Incluso si fuera posible cablear todas las estaciones de trabajo juntas, al colocar más estaciones en un hub Ethernet o en una red Ethernet clásica no se agrega capacidad. Todas las estaciones comparten la misma cantidad fija de ancho de banda. Entre más estaciones haya, menor será el ancho de banda promedio por estación.
Para que estos beneficios pudieran estar fácilmente disponibles, los puentes ideales tendrían que ser totalmente transparentes. Debería ser posible comprar los puentes, conectar los cables de LAN en los puentes y que todo funcionara a la perfección en un instante. No debería existir la necesidad de cambios de hardware o de software, ni de configurar switches de direcciones o descargar tablas de enrutamiento o parámetros, nada de eso. Simplemente conectar los cables y seguir con nuestras actividades cotidianas. Lo que es más, la operación de las redes LAN existentes no se debería ver afectada por los puentes para nada. En cuanto a las estaciones, no debería haber ninguna diferencia observable en cuanto a si son parte o no de una LAN con puente. Debería ser igual de fácil mover estaciones alrededor de una LAN con puente que moverlas en una sola LAN.
Puentes de aprendizaje
Los puentes se desarrollaron cuando se usaban redes Ethernet clásicas, por lo que a menudo se muestran en topologías con cables multiderivación. Sin embargo, todas las topologías en la actualidad están compuestas de cables punto a punto y switches. Los puentes funcionan de la misma forma en ambas configuraciones. Todas las estaciones conectadas al mismo puerto en un puente pertenecen al mismo dominio de colisión, y éste es distinto al dominio de colisión para otros puertos. Si hay más de una estación, como en una red Ethernet clásica, un hub o un enlace half-dúplex, se utiliza el protocolo CSMA/CD para enviar tramas.
Sin embargo, hay una diferencia en cuanto a la forma en que se construyen las redes LAN con puentes. Para conectar redes LAN multiderivación con puentes, se agrega un puente como una nueva estación en cada LAN multiderivación, como en la figura 4-41(a). Para conectar redes LAN punto a punto mediante puentes, los hubs se conectan a un puente o, lo que es preferible, se reemplazan con un puente para incrementar el desempeño.
7.3) Capa de red
La capa de red se encarga de llevar los paquetes todo el camino, desde el origen hasta el destino. Para llegar al destino tal vez sea necesario realizar muchos saltos en el camino por enrutadores intermedios. Esta función ciertamente contrasta con la de la capa de enlace de datos, cuya única meta es mover tramas de un extremo del cable al otro. Por lo tanto, la capa de red es la capa más baja que maneja la transmisión de extremo a extremo.
Para lograr sus objetivos, la capa de red debe conocer la topología de la red (es decir, el conjunto de todos los enrutadores y enlaces) y elegir las rutas apropiadas incluso para redes más grandes. También debe tener cuidado al escoger las rutas para no sobrecargar algunas de las líneas de comunicación y los enrutadores, y dejar inactivos a otros. Por último, cuando el origen y el destino están en redes diferentes, ocurren nuevos problemas. La capa de red es la encargada de solucionarlos.
La capa de red se encarga de llevar los paquetes todo el camino, desde el origen hasta el destino. Para llegar al destino tal vez sea necesario realizar muchos saltos en el camino por enrutadores intermedios. Esta función ciertamente contrasta con la de la capa de enlace de datos, cuya única meta es mover tramas de un extremo del cable al otro. Por lo tanto, la capa de red es la capa más baja que maneja la transmisión de extremo a extremo.
Para lograr sus objetivos, la capa de red debe conocer la topología de la red (es decir, el conjunto de todos los enrutadores y enlaces) y elegir las rutas apropiadas incluso para redes más grandes. También debe tener cuidado al escoger las rutas para no sobrecargar algunas de las líneas de comunicación y los enrutadores, y dejar inactivos a otros. Por último, cuando el origen y el destino están en redes diferentes, ocurren nuevos problemas. La capa de red es la encargada de solucionarlos.
7.3.1) Aspectos de la capa de red
En las siguientes secciones presentaremos una introducción sobre algunos de los problemas a los que se deben enfrentar los diseñadores de la capa de red. Estos temas incluyen el servicio proporcionado a la capa de transporte y el diseño interno de la red.
Conmutación de paquetes de almacenamiento y reenvio
Antes de empezar a explicar los detalles sobre la capa de red, vale la pena volver a exponer el contexto en el que operan los protocolos de esta capa. En la siguiente figura podemos ver este texto. Los componentes principales de la red son el equipo del Provedor del Servicio de Internet (ISP) (enrutadores conectados mediante líneas de transmisión), que se muestra dentro del óvalo sombreado, y el equipo de los clientes, que se muestra fuera del óvalo. El host H1 está conectado de manera directa a un enrutador del ISP, A, tal vez en forma de una computadora en el hogar conectada a un módem DSL. En contraste, H2 se encuentra en una LAN (que podría ser una Ethernet de oficina) con un enrutador, F, el cual es propiedad del cliente, quien lo maneja. Este enrutador tiene una línea alquilada que va al equipo del ISP. Mostramos a F fuera del óvalo porque no pertenece al ISP. Sin embargo y para los fines de este capítulo, los enrutadores locales de los clientes se consideran parte de la red del ISP debido a que ejecutan los mismos algoritmos que los enrutadores del ISP (y nuestro principal interés aquí son los algoritmos).

En las siguientes secciones presentaremos una introducción sobre algunos de los problemas a los que se deben enfrentar los diseñadores de la capa de red. Estos temas incluyen el servicio proporcionado a la capa de transporte y el diseño interno de la red.
Conmutación de paquetes de almacenamiento y reenvio
Antes de empezar a explicar los detalles sobre la capa de red, vale la pena volver a exponer el contexto en el que operan los protocolos de esta capa. En la siguiente figura podemos ver este texto. Los componentes principales de la red son el equipo del Provedor del Servicio de Internet (ISP) (enrutadores conectados mediante líneas de transmisión), que se muestra dentro del óvalo sombreado, y el equipo de los clientes, que se muestra fuera del óvalo. El host H1 está conectado de manera directa a un enrutador del ISP, A, tal vez en forma de una computadora en el hogar conectada a un módem DSL. En contraste, H2 se encuentra en una LAN (que podría ser una Ethernet de oficina) con un enrutador, F, el cual es propiedad del cliente, quien lo maneja. Este enrutador tiene una línea alquilada que va al equipo del ISP. Mostramos a F fuera del óvalo porque no pertenece al ISP. Sin embargo y para los fines de este capítulo, los enrutadores locales de los clientes se consideran parte de la red del ISP debido a que ejecutan los mismos algoritmos que los enrutadores del ISP (y nuestro principal interés aquí son los algoritmos).

7.3.2) Algoritmos de enrutamiento
La principal función de la capa de red es enrutar paquetes de la máquina de origen a la de destino. En la mayoría de las redes, los paquetes requerirán varios saltos para completar el viaje. La única excepción importante son las redes de difusión, pero aun aquí es importante el enrutamiento si el origen y el destino no están en el mismo segmento de red. Los algoritmos que eligen las rutas y las estructuras de datos que usan constituyen un aspecto principal del diseño de la capa de red.
El algoritmo de enrutamiento es aquella parte del software de la capa de red responsable de decidir por cuál línea de salida se transmitirá un paquete entrante. Si la red usa datagramas de manera interna, esta decisión debe tomarse cada vez que llega un paquete de datos, dado que la mejor ruta podría haber cambiado desde la última vez. Si la red usa circuitos virtuales internamente, las decisiones de enrutamiento se toman sólo al establecer un circuito virtual nuevo. En lo sucesivo, los paquetes de datos simplemente siguen la ruta ya establecida. Este último caso a veces se llama enrutamiento de sesión, dado que una ruta permanece vigente durante toda una sesión (por ejemplo, durante una sesión a través de una VPN).
En ocasiones es útil distinguir entre el enrutamiento, que es el proceso que consiste en tomar la decisión de cuáles rutas utilizar, y el reenvío, que consiste en la acción que se toma cuando llega un paquete. Podemos considerar que un enrutador tiene dos procesos internos. Uno de ellos maneja cada paquete conforme
llega, y después busca en las tablas de enrutamiento la línea de salida por la cual se enviará. Este proceso se conoce como reenvío. El otro proceso es responsable de llenar y actualizar las tablas de enrutamiento.
Es ahí donde entra en acción el algoritmo de enrutamiento. Sin importar si las rutas se eligen de manera independiente para cada paquete enviado o sólo cuando se establecen nuevas conexiones, existen ciertas propiedades que todo algoritmo de enrutamiento debe poseer: exactitud, sencillez, robustez, estabilidad, equidad y eficiencia. La exactitud y la sencillez apenas requieren comentarios, pero la necesidad de robustez puede ser menos obvia a primera vista. Una vez que una red principal entra en operación, es de esperar que funcione de manera continua durante años, sin fallas a nivel de sistema. Durante ese periodo habrá fallas de hardware y de software de todo tipo. Los hosts, enrutadores y líneas fallarán en forma repetida y la topología cambiará muchas veces. El algoritmo de enrutamiento debe ser capaz de manejar los cambios de topología y tráfico sin necesidad de abortar todas las tareas en todos los hosts. ¡Imagine el desastre si la red tuviera que reiniciarse cada vez que fallara un enrutador!
La estabilidad también es una meta importante para el algoritmo de enrutamiento. Existen algoritmos de enrutamiento que nunca convergen hacia un conjunto de rutas fijo, sin importar el tiempo que permanezcan en operación. Un algoritmo estable alcanza el equilibrio y lo conserva. Además debe converger con rapidez, ya que se puede interrumpir la comunicación hasta que el algoritmo de enrutamiento haya llegado a un equilibrio.
Antes de que podamos siquiera intentar encontrar el punto medio entre la equidad y la eficiencia, debemos decidir qué es lo que buscamos optimizar. Minimizar el retardo promedio de los paquetes es un candidato obvio para enviar tráfico a través de la red en forma efectiva, pero también lo es aumentar al máximo la velocidad real de transferencia total de la red. Además, estas dos metas también están en conflicto, ya que operar cualquier sistema de colas cerca de su capacidad máxima implica un gran retardo de encolamiento. Como término medio, muchas redes intentan minimizar la distancia que debe recorrer el paquete, o simplemente reducir el número de saltos que tiene que dar un paquete.
Cualquiera de estas opciones tiende a mejorar el retardo y también reduce la cantidad de ancho de banda consumido por paquete, lo cual tiende a mejorar la velocidad de transferencia real de la red en general. Podemos agrupar los algoritmos de enrutamiento en dos clases principales: no adaptativos y adaptativos. Los algoritmos no adaptativos no basan sus decisiones de enrutamiento en mediciones o estimaciones del tráfico y la topología actuales.
En contraste, los algoritmos adaptativos cambian sus decisiones de enrutamiento para reflejar los cambios de topología y algunas veces también los cambios en el tráfico. Estos algoritmos de enrutamiento dinámico difieren en cuanto al lugar de donde obtienen su información.
Principio de optimización
Antes de entrar en algoritmos específicos, puede ser útil señalar que es posible hacer una postulado general sobre las rutas óptimas sin importar la topología o el tráfico de la red. Este postulado se conoce como principio de optimización (Bellman, 1957) y establece que si el enrutador J está en la ruta óptima del enrutador I al enrutador K, entonces la ruta óptima de J a K también está en la misma ruta.
Como consecuencia directa del principio de optimización, podemos ver que el grupo de rutas óptimas de todos los orígenes a un destino dado forman un árbol con raíz en el destino. Dicho árbol se conoce como árbol sumidero (o árbol divergente), donde la métrica de distancia es el número de saltos. El objetivo de todos los algoritmos de enrutamiento es descubrir y usar los árboles sumidero para todos los enrutadores.
Cabe mencionar que un árbol sumidero no necesariamente es único; pueden existir otros árboles con las mismas longitudes de rutas. Si permitimos que se elijan todas las posibles rutas, el árbol se convierte en una estructura más general conocida como DAG (Gráfico Acíclico Dirigido, del inglés Directed Acyclic Graph). Los DAG no tienen ciclos. Usaremos los árboles sumidero como un método abreviado conveniente para ambos casos, que también dependen del supuesto técnico de que las rutas no interfieren entre sí; por ejemplo, un congestionamiento de tráfico en una ruta no provocará que se desvíe a otra ruta.
Puesto que un árbol sumidero ciertamente es un árbol, no contiene ciclos, por lo que cada paquete se entregará en un número de saltos finito y limitado. En la práctica, la vida no es tan fácil. Los enlaces y los enrutadores pueden fallar y recuperarse durante la operación, así que distintos enrutadores pueden tener ideas diferentes sobre la topología actual. Además, hemos evadido la cuestión de si cada enrutador tiene que adquirir de manera individual la información en la cual basa su cálculo del árbol sumidero, o si debe obtener esta información por otros medios. Regresaremos a estos asuntos pronto. Con todo, el principio de optimización y el árbol sumidero proporcionan los puntos de referencia contra los que se pueden medir otros algoritmos de enrutamiento.
Algoritmo de la ruta mas corta
Empecemos nuestro estudio de los algoritmos de enrutamiento con una técnica simple para calcular las rutas óptimas con base en una imagen completa de la red. Estas rutas son las que queremos que encuentre un algoritmo de enrutamiento distribuido, aun cuando no todos los enrutadores conozcan todos los detalles de la red.
La idea es construir un grafo de la red, en donde cada nodo del grafo representa un enrutador y cada arco del grafo representa una línea o enlace de comunicaciones. Para elegir una ruta entre un par específico de enrutadores, el algoritmo simplemente encuentra la ruta más corta entre ellos en el grafo. El concepto de la ruta más corta merece una explicación. Una manera de medir la longitud de una ruta es mediante el número de saltos.
Se conocen varios algoritmos para calcular la ruta más corta entre dos nodos de un grafo. Uno de éstos se debe a Dijkstra, el cual encuentra las rutas más cortas entre un origen y todos los destinos en una red. Cada nodo se etiqueta (entre paréntesis) con su distancia desde el nodo de origen a través de la mejor ruta conocida. Las distancias no deben ser negativas, como lo serán si se basan en cantidades reales como ancho de banda y retardo. Al principio no se conocen rutas, por lo que todos los nodos tienen la etiqueta infinito. A medida que avanza el algoritmo y se encuentran rutas, las etiquetas pueden cambiar para reflejar mejores rutas. Una etiqueta puede ser tentativa o permanente. En un principio todas las etiquetas son tentativas. Una vez que se descubre que una etiqueta representa la ruta más corta posible del origen a ese nodo, se vuelve permanente y no cambia más.
La principal función de la capa de red es enrutar paquetes de la máquina de origen a la de destino. En la mayoría de las redes, los paquetes requerirán varios saltos para completar el viaje. La única excepción importante son las redes de difusión, pero aun aquí es importante el enrutamiento si el origen y el destino no están en el mismo segmento de red. Los algoritmos que eligen las rutas y las estructuras de datos que usan constituyen un aspecto principal del diseño de la capa de red.
El algoritmo de enrutamiento es aquella parte del software de la capa de red responsable de decidir por cuál línea de salida se transmitirá un paquete entrante. Si la red usa datagramas de manera interna, esta decisión debe tomarse cada vez que llega un paquete de datos, dado que la mejor ruta podría haber cambiado desde la última vez. Si la red usa circuitos virtuales internamente, las decisiones de enrutamiento se toman sólo al establecer un circuito virtual nuevo. En lo sucesivo, los paquetes de datos simplemente siguen la ruta ya establecida. Este último caso a veces se llama enrutamiento de sesión, dado que una ruta permanece vigente durante toda una sesión (por ejemplo, durante una sesión a través de una VPN).
En ocasiones es útil distinguir entre el enrutamiento, que es el proceso que consiste en tomar la decisión de cuáles rutas utilizar, y el reenvío, que consiste en la acción que se toma cuando llega un paquete. Podemos considerar que un enrutador tiene dos procesos internos. Uno de ellos maneja cada paquete conforme
llega, y después busca en las tablas de enrutamiento la línea de salida por la cual se enviará. Este proceso se conoce como reenvío. El otro proceso es responsable de llenar y actualizar las tablas de enrutamiento.
Es ahí donde entra en acción el algoritmo de enrutamiento. Sin importar si las rutas se eligen de manera independiente para cada paquete enviado o sólo cuando se establecen nuevas conexiones, existen ciertas propiedades que todo algoritmo de enrutamiento debe poseer: exactitud, sencillez, robustez, estabilidad, equidad y eficiencia. La exactitud y la sencillez apenas requieren comentarios, pero la necesidad de robustez puede ser menos obvia a primera vista. Una vez que una red principal entra en operación, es de esperar que funcione de manera continua durante años, sin fallas a nivel de sistema. Durante ese periodo habrá fallas de hardware y de software de todo tipo. Los hosts, enrutadores y líneas fallarán en forma repetida y la topología cambiará muchas veces. El algoritmo de enrutamiento debe ser capaz de manejar los cambios de topología y tráfico sin necesidad de abortar todas las tareas en todos los hosts. ¡Imagine el desastre si la red tuviera que reiniciarse cada vez que fallara un enrutador!
La estabilidad también es una meta importante para el algoritmo de enrutamiento. Existen algoritmos de enrutamiento que nunca convergen hacia un conjunto de rutas fijo, sin importar el tiempo que permanezcan en operación. Un algoritmo estable alcanza el equilibrio y lo conserva. Además debe converger con rapidez, ya que se puede interrumpir la comunicación hasta que el algoritmo de enrutamiento haya llegado a un equilibrio.
Antes de que podamos siquiera intentar encontrar el punto medio entre la equidad y la eficiencia, debemos decidir qué es lo que buscamos optimizar. Minimizar el retardo promedio de los paquetes es un candidato obvio para enviar tráfico a través de la red en forma efectiva, pero también lo es aumentar al máximo la velocidad real de transferencia total de la red. Además, estas dos metas también están en conflicto, ya que operar cualquier sistema de colas cerca de su capacidad máxima implica un gran retardo de encolamiento. Como término medio, muchas redes intentan minimizar la distancia que debe recorrer el paquete, o simplemente reducir el número de saltos que tiene que dar un paquete.
Cualquiera de estas opciones tiende a mejorar el retardo y también reduce la cantidad de ancho de banda consumido por paquete, lo cual tiende a mejorar la velocidad de transferencia real de la red en general. Podemos agrupar los algoritmos de enrutamiento en dos clases principales: no adaptativos y adaptativos. Los algoritmos no adaptativos no basan sus decisiones de enrutamiento en mediciones o estimaciones del tráfico y la topología actuales.
En contraste, los algoritmos adaptativos cambian sus decisiones de enrutamiento para reflejar los cambios de topología y algunas veces también los cambios en el tráfico. Estos algoritmos de enrutamiento dinámico difieren en cuanto al lugar de donde obtienen su información.
Principio de optimización
Antes de entrar en algoritmos específicos, puede ser útil señalar que es posible hacer una postulado general sobre las rutas óptimas sin importar la topología o el tráfico de la red. Este postulado se conoce como principio de optimización (Bellman, 1957) y establece que si el enrutador J está en la ruta óptima del enrutador I al enrutador K, entonces la ruta óptima de J a K también está en la misma ruta.
Como consecuencia directa del principio de optimización, podemos ver que el grupo de rutas óptimas de todos los orígenes a un destino dado forman un árbol con raíz en el destino. Dicho árbol se conoce como árbol sumidero (o árbol divergente), donde la métrica de distancia es el número de saltos. El objetivo de todos los algoritmos de enrutamiento es descubrir y usar los árboles sumidero para todos los enrutadores.
Cabe mencionar que un árbol sumidero no necesariamente es único; pueden existir otros árboles con las mismas longitudes de rutas. Si permitimos que se elijan todas las posibles rutas, el árbol se convierte en una estructura más general conocida como DAG (Gráfico Acíclico Dirigido, del inglés Directed Acyclic Graph). Los DAG no tienen ciclos. Usaremos los árboles sumidero como un método abreviado conveniente para ambos casos, que también dependen del supuesto técnico de que las rutas no interfieren entre sí; por ejemplo, un congestionamiento de tráfico en una ruta no provocará que se desvíe a otra ruta.
Puesto que un árbol sumidero ciertamente es un árbol, no contiene ciclos, por lo que cada paquete se entregará en un número de saltos finito y limitado. En la práctica, la vida no es tan fácil. Los enlaces y los enrutadores pueden fallar y recuperarse durante la operación, así que distintos enrutadores pueden tener ideas diferentes sobre la topología actual. Además, hemos evadido la cuestión de si cada enrutador tiene que adquirir de manera individual la información en la cual basa su cálculo del árbol sumidero, o si debe obtener esta información por otros medios. Regresaremos a estos asuntos pronto. Con todo, el principio de optimización y el árbol sumidero proporcionan los puntos de referencia contra los que se pueden medir otros algoritmos de enrutamiento.
Algoritmo de la ruta mas corta
Empecemos nuestro estudio de los algoritmos de enrutamiento con una técnica simple para calcular las rutas óptimas con base en una imagen completa de la red. Estas rutas son las que queremos que encuentre un algoritmo de enrutamiento distribuido, aun cuando no todos los enrutadores conozcan todos los detalles de la red.
La idea es construir un grafo de la red, en donde cada nodo del grafo representa un enrutador y cada arco del grafo representa una línea o enlace de comunicaciones. Para elegir una ruta entre un par específico de enrutadores, el algoritmo simplemente encuentra la ruta más corta entre ellos en el grafo. El concepto de la ruta más corta merece una explicación. Una manera de medir la longitud de una ruta es mediante el número de saltos.
Se conocen varios algoritmos para calcular la ruta más corta entre dos nodos de un grafo. Uno de éstos se debe a Dijkstra, el cual encuentra las rutas más cortas entre un origen y todos los destinos en una red. Cada nodo se etiqueta (entre paréntesis) con su distancia desde el nodo de origen a través de la mejor ruta conocida. Las distancias no deben ser negativas, como lo serán si se basan en cantidades reales como ancho de banda y retardo. Al principio no se conocen rutas, por lo que todos los nodos tienen la etiqueta infinito. A medida que avanza el algoritmo y se encuentran rutas, las etiquetas pueden cambiar para reflejar mejores rutas. Una etiqueta puede ser tentativa o permanente. En un principio todas las etiquetas son tentativas. Una vez que se descubre que una etiqueta representa la ruta más corta posible del origen a ese nodo, se vuelve permanente y no cambia más.
7.3.3) Interconexión de redes
Hasta ahora hemos supuesto de manera implícita que hay una sola red homogénea, en donde cada máquina usa el mismo protocolo en cada capa. Por desgracia, este supuesto es demasiado optimista. Existen muchas redes distintas, entre ellas PAN, LAN, MAN y WAN. Ya describimos Ethernet, Internet por cable, las redes telefónicas fija y móvil, 802.11, 802.16 y muchas más. Hay numerosos protocolos con un uso muy difundido a través de estas redes, en cada capa. En las siguientes secciones estudiaremos con cuidado los aspectos que surgen cuando se conectan dos o más redes para formar una interred o simplemente una internet.
Sería más simple unir redes si todos usaran una sola tecnología de red; a menudo se da el caso de que hay un tipo dominante de red, como Ethernet. Algunos expertos especulan que la multiplicidad de tecnologías desaparecerá tan pronto como todos se den cuenta qué tan maravillosa es la red... No cuente con ello. La historia muestra que esto es sólo ilusión. Los distintos tipos de redes luchan con problemas diferentes; por ejemplo, las redes Ethernet y satelitales casi siempre difieren. Al reutilizar los sistemas existentes, como operar redes de datos a través del servicio de cable, la red telefónica y el cableado eléctrico, se agregan limitaciones que ocasionan la divergencia de las características de las redes. La heterogeneidad llegó para quedarse.
Si siempre habrá una variedad de redes, sería más simple que no necesitáramos interconectarlas. Esto también es muy poco probable. Bob Metcalfe postuló que el valor de una red con N nodos es el número de conexiones que se pueden hacer entre los nodos, o N^2 (Gilder, 1993). Esto significa que las redes grandes son mucho más valiosas que las pequeñas, ya que permiten muchas más conexiones, por lo que siempre habrá un incentivo para combinar redes pequeñas.
Internet es el ejemplo primordial de esta interconexión (vamos a escribir Internet con una “I” mayúscula para diferenciarla de otras interred o redes interconectadas). El propósito de unir todas estas redes es permitir que los usuarios en cualquiera de ellas se comuniquen con los usuarios de las otras redes. Cuando usted paga a un ISP por el servicio de Internet, el costo dependerá del ancho de banda de su línea, pero lo que en realidad está pagando es la capacidad de intercambiar paquetes con cualquier otro host que también esté conectado a Internet. Después de todo, Internet no sería muy popular si sólo pudiéramos enviar paquetes a otros hosts en la misma ciudad.
Como difieren las redes
Las redes pueden diferir de muchas maneras. Algunas de las diferencias, como técnicas de modulación o formatos de tramas diferentes, se encuentran en la capa física y en la de enlace de datos. No trataremos esas diferencias aquí. La conciliación de estas diferencias es lo que hace más difícil la interconexión de redes que la operación con una sola red.
Cuando los paquetes enviados por una fuente en una red deben transitar a través de una o más redes foráneas antes de llegar a la red de destino, pueden ocurrir muchos problemas en las interfaces entre las redes. Para empezar, la fuente necesita dirigirse al destino. ¿Qué hacemos si la fuente está en una red Ethernet y el destino en una red Wi-MAX? Suponiendo que sea posible especificar un destino Wi-MAX desde una red Ethernet, los paquetes pasarían de una red sin conexión a una orientada a conexión. Para ello tal vez sea necesario establecer una conexión improvisada, lo cual introduce un retardo y mucha sobrecarga si la conexión no se utiliza para muchos paquetes más.
También debemos tener en cuenta muchas diferencias específicas. Estos tipos de diferencias se pueden enmendar, con cierto esfuerzo. Por ejemplo, una puerta de enlace que une dos redes podría generar paquetes separados para cada destino en vez de un mejor soporte para la multidifusión. Un paquete extenso se podría dividir, enviar en piezas y unir de vuelta. Los receptores podrían colocar los paquetes en un búfer y entregarlos en orden. Las redes también pueden diferir en sentidos más importantes que son más difíciles de conciliar. El ejemplo más claro es la calidad del servicio. Si una red tiene una QoS sólida y la otra ofrece un servicio del mejor esfuerzo, será imposible hacer garantías de ancho de banda y retardo para el tráfico en tiempo real de un extremo al otro. De hecho, es probable que sólo se puedan hacer mientras la red del mejor esfuerzo opere con poco uso, o cuando se utilice en raras ocasiones, lo cual no es muy probable que sea el objetivo de la mayoría de los ISP. Los mecanismos de seguridad son problemáticos, pero por lo menos el cifrado para la confiabilidad e integridad de los datos se puede poner encima de las redes que no lo incluyen de antemano. Por último, las diferencias en la contabilidad pueden producir facturas no deseadas cuando el uso normal de repente se vuelve costoso, como lo han descubierto los usuarios de teléfonos móviles cuando usan roaming y tienen planes de datos.
Como se pueden conectar la redes
Existen dos opciones básicas para conectar distintas redes: podemos construir dispositivos que traduzcan o conviertan los paquetes de cada tipo de red en paquetes para otra red o, como buenos científicos de la computación, podemos tratar de resolver el problema al agregar una capa de indirección y construir una capa común encima de las distintas redes. En cualquier caso, los dispositivos se colocan en los límites entre las redes.
Desde un principio, Cerf y Kahn (1974) abogaron por una capa común para ocultar las diferencias de las redes existentes. Esta metodología ha tenido un gran éxito, y la capa que propusieron se separó eventualmente en los protocolos TCP e IP. Casi cuatro décadas después, IP es la base de la Internet moderna. Por este logro, Cerf y Kahn recibieron el Premio Turing 2004, conocido de manera informal como el Premio Nobel de las ciencias computacionales. IP proporciona un formato de paquete universal que todos los enrutadores reconocen y que se puede pasar casi por cualquier red. IP ha extendido su alcance de las redes de computadoras para apoderarse de la red telefónica. También opera en redes de sensores y en otros dispositivos pequeños que alguna vez se consideraron con recursos demasiado restringidos como para soportarlo.
Hemos analizado varios dispositivos diferentes que conectan redes, incluyendo repetidores, hubs, switches, puentes, enrutadores y puertas de enlace. Los repetidores y hubs sólo desplazan bits de un cable a otro. En su mayoría son dispositivos analógicos y no comprenden nada sobre los protocolos de las capas superiores. Los puentes y switches operan en la capa de enlace. Se pueden usar para construir redes, pero sólo con una pequeña traducción de protocolos en el proceso; por ejemplo, entre los switches Ethernet de 10, 100 y 1000 Mbps. Nuestro enfoque en esta sección es en los dispositivos de interconexión que operan en la capa de red, es decir, los enrutadores.
Hasta ahora hemos supuesto de manera implícita que hay una sola red homogénea, en donde cada máquina usa el mismo protocolo en cada capa. Por desgracia, este supuesto es demasiado optimista. Existen muchas redes distintas, entre ellas PAN, LAN, MAN y WAN. Ya describimos Ethernet, Internet por cable, las redes telefónicas fija y móvil, 802.11, 802.16 y muchas más. Hay numerosos protocolos con un uso muy difundido a través de estas redes, en cada capa. En las siguientes secciones estudiaremos con cuidado los aspectos que surgen cuando se conectan dos o más redes para formar una interred o simplemente una internet.
Sería más simple unir redes si todos usaran una sola tecnología de red; a menudo se da el caso de que hay un tipo dominante de red, como Ethernet. Algunos expertos especulan que la multiplicidad de tecnologías desaparecerá tan pronto como todos se den cuenta qué tan maravillosa es la red... No cuente con ello. La historia muestra que esto es sólo ilusión. Los distintos tipos de redes luchan con problemas diferentes; por ejemplo, las redes Ethernet y satelitales casi siempre difieren. Al reutilizar los sistemas existentes, como operar redes de datos a través del servicio de cable, la red telefónica y el cableado eléctrico, se agregan limitaciones que ocasionan la divergencia de las características de las redes. La heterogeneidad llegó para quedarse.
Si siempre habrá una variedad de redes, sería más simple que no necesitáramos interconectarlas. Esto también es muy poco probable. Bob Metcalfe postuló que el valor de una red con N nodos es el número de conexiones que se pueden hacer entre los nodos, o N^2 (Gilder, 1993). Esto significa que las redes grandes son mucho más valiosas que las pequeñas, ya que permiten muchas más conexiones, por lo que siempre habrá un incentivo para combinar redes pequeñas.
Internet es el ejemplo primordial de esta interconexión (vamos a escribir Internet con una “I” mayúscula para diferenciarla de otras interred o redes interconectadas). El propósito de unir todas estas redes es permitir que los usuarios en cualquiera de ellas se comuniquen con los usuarios de las otras redes. Cuando usted paga a un ISP por el servicio de Internet, el costo dependerá del ancho de banda de su línea, pero lo que en realidad está pagando es la capacidad de intercambiar paquetes con cualquier otro host que también esté conectado a Internet. Después de todo, Internet no sería muy popular si sólo pudiéramos enviar paquetes a otros hosts en la misma ciudad.
Como difieren las redes
Las redes pueden diferir de muchas maneras. Algunas de las diferencias, como técnicas de modulación o formatos de tramas diferentes, se encuentran en la capa física y en la de enlace de datos. No trataremos esas diferencias aquí. La conciliación de estas diferencias es lo que hace más difícil la interconexión de redes que la operación con una sola red.
Cuando los paquetes enviados por una fuente en una red deben transitar a través de una o más redes foráneas antes de llegar a la red de destino, pueden ocurrir muchos problemas en las interfaces entre las redes. Para empezar, la fuente necesita dirigirse al destino. ¿Qué hacemos si la fuente está en una red Ethernet y el destino en una red Wi-MAX? Suponiendo que sea posible especificar un destino Wi-MAX desde una red Ethernet, los paquetes pasarían de una red sin conexión a una orientada a conexión. Para ello tal vez sea necesario establecer una conexión improvisada, lo cual introduce un retardo y mucha sobrecarga si la conexión no se utiliza para muchos paquetes más.
También debemos tener en cuenta muchas diferencias específicas. Estos tipos de diferencias se pueden enmendar, con cierto esfuerzo. Por ejemplo, una puerta de enlace que une dos redes podría generar paquetes separados para cada destino en vez de un mejor soporte para la multidifusión. Un paquete extenso se podría dividir, enviar en piezas y unir de vuelta. Los receptores podrían colocar los paquetes en un búfer y entregarlos en orden. Las redes también pueden diferir en sentidos más importantes que son más difíciles de conciliar. El ejemplo más claro es la calidad del servicio. Si una red tiene una QoS sólida y la otra ofrece un servicio del mejor esfuerzo, será imposible hacer garantías de ancho de banda y retardo para el tráfico en tiempo real de un extremo al otro. De hecho, es probable que sólo se puedan hacer mientras la red del mejor esfuerzo opere con poco uso, o cuando se utilice en raras ocasiones, lo cual no es muy probable que sea el objetivo de la mayoría de los ISP. Los mecanismos de seguridad son problemáticos, pero por lo menos el cifrado para la confiabilidad e integridad de los datos se puede poner encima de las redes que no lo incluyen de antemano. Por último, las diferencias en la contabilidad pueden producir facturas no deseadas cuando el uso normal de repente se vuelve costoso, como lo han descubierto los usuarios de teléfonos móviles cuando usan roaming y tienen planes de datos.
Como se pueden conectar la redes
Existen dos opciones básicas para conectar distintas redes: podemos construir dispositivos que traduzcan o conviertan los paquetes de cada tipo de red en paquetes para otra red o, como buenos científicos de la computación, podemos tratar de resolver el problema al agregar una capa de indirección y construir una capa común encima de las distintas redes. En cualquier caso, los dispositivos se colocan en los límites entre las redes.
Desde un principio, Cerf y Kahn (1974) abogaron por una capa común para ocultar las diferencias de las redes existentes. Esta metodología ha tenido un gran éxito, y la capa que propusieron se separó eventualmente en los protocolos TCP e IP. Casi cuatro décadas después, IP es la base de la Internet moderna. Por este logro, Cerf y Kahn recibieron el Premio Turing 2004, conocido de manera informal como el Premio Nobel de las ciencias computacionales. IP proporciona un formato de paquete universal que todos los enrutadores reconocen y que se puede pasar casi por cualquier red. IP ha extendido su alcance de las redes de computadoras para apoderarse de la red telefónica. También opera en redes de sensores y en otros dispositivos pequeños que alguna vez se consideraron con recursos demasiado restringidos como para soportarlo.
Hemos analizado varios dispositivos diferentes que conectan redes, incluyendo repetidores, hubs, switches, puentes, enrutadores y puertas de enlace. Los repetidores y hubs sólo desplazan bits de un cable a otro. En su mayoría son dispositivos analógicos y no comprenden nada sobre los protocolos de las capas superiores. Los puentes y switches operan en la capa de enlace. Se pueden usar para construir redes, pero sólo con una pequeña traducción de protocolos en el proceso; por ejemplo, entre los switches Ethernet de 10, 100 y 1000 Mbps. Nuestro enfoque en esta sección es en los dispositivos de interconexión que operan en la capa de red, es decir, los enrutadores.
7.3.4) La capa de red de internet
Ahora es momento de examinar a conciencia la capa de red de Internet. Pero antes de entrar en detalles, vale la pena dar un vistazo a los principios que guiaron su diseño en el pasado y que hicieron posible el éxito que tiene hoy en día. En la actualidad, con frecuencia parece que la gente los ha olvidado. Estos principios se enumeran y analizan en el RFC 1958, el cual vale la pena leer. Este RFC utiliza mucho las ideas establecidas por Clark (1988) y por Saltzer y colaboradores.
En la capa de red, la Internet puede verse como un conjunto de redes, o Sistemas Autónomos (AS) interconectados. No hay una estructura real, pero existen varias redes troncales (backbones) principales. Éstas se construyen a partir de líneas de alto ancho de banda y enrutadores rápidos. Las más grandes de estas redes troncales, a la que se conectan todos los demás para llegar al resto de Internet, se llaman redes de Nivel 1. Conectadas a las redes troncales hay ISP (Proveedores de Servicio de Internet) que proporcionan acceso a Internet para los hogares y negocios, centros de datos e instalaciones de colocación
llenas de máquinas servidores y redes regionales (de nivel medio). Los centros de datos sirven gran parte del contenido que se envía a través de Internet. A las redes regionales están conectados más ISP, LAN de muchas universidades y empresas, y otras redes de punta. En la figura 5-45 se presenta un dibujo de esta organización cuasijerárquica.
El pegamento que mantiene unida a Internet es el protocolo de capa de red, IP (Protocolo de Internet, del inglés Internet Protocol). A diferencia de la mayoría de los protocolos de capa de red anteriores, IP se diseñó desde el principio con la interconexión de redes en mente. Una buena manera de visualizar la capa de red es la siguiente: su trabajo es proporcionar un medio de mejor esfuerzo (es decir, sin garantía) para transportar paquetes de la fuente al destino, sin importar si estas máquinas están en la misma red o si hay otras redes entre ellas.
La comunicación en Internet funciona de la siguiente manera. La capa de transporte toma flujos de datos y los divide para poder enviarlos como paquetes IP. En teoría, los paquetes pueden ser de hasta 64 Kbytes cada uno, pero en la práctica por lo general no sobrepasan los 1500 bytes (ya que son colocados en una trama de Ethernet). Los enrutadores IP reenvían cada paquete a través de Internet, a lo largo de una ruta de un enrutador a otro, hasta llegar al destino. En el destino, la capa de red entrega los datos a la capa de transporte, que a su vez los entrega al proceso receptor. Cuando todas las piezas llegan finalmente a la máquina de destino, la capa de red las vuelve a ensamblar para formar el datagrama original. A continuación este datagrama se entrega a la capa de transporte.
El protocolo IP versión 4
Un lugar adecuado para comenzar nuestro estudio de la capa de red de Internet es el formato de los datagramas de IP mismos. Un datagrama IPv4 consiste en dos partes: el encabezado y el cuerpo o carga útil. El encabezado tiene una parte fija de 20 bytes y una parte opcional de longitud variable. Los bits se transmiten en orden de izquierda a derecha y de arriba hacia abajo, comenzando por el bit de mayor orden del campo Versión (éste es un orden de bytes de red big endian. En las máquinas little endian, como las computadoras Intel x86, se requiere una conversión por software tanto para la transmisión como para la recepción). En retrospectiva, el formato little endian hubiera sido una mejor opción, pero al momento de diseñar IP nadie sabía que llegaría a dominar la computación.
El campo Versión lleva el registro de la versión del protocolo al que pertenece el datagrama. La versión 4 es la que domina Internet en la actualidad, y ahí es donde empezamos nuestro estudio. Al incluir la versión al inicio de cada datagrama, es posible tener una transición entre versiones a través de un largo periodo de tiempo. De hecho, IPv6 (la siguiente versión de IP) se definió hace más de una década y apenas se está empezando a implementar. Lo describiremos más adelante en esta sección. En un momento dado nos veremos obligados a usarlo cuando cada uno de los casi 231 habitantes de China tenga una PC de escritorio, una computadora portátil y un teléfono IP. Como observación adicional en cuanto a la numeración, IPv5 fue un protocolo de flujo experimental en tiempo real que nunca fue muy popular.
Dado que la longitud del encabezado no es constante, se incluye un campo en el encabezado (IHL) para indicar su longitud en palabras de 32 bits. El valor mínimo es de 5, cifra que se aplica cuando no hay opciones. El valor máximo de este campo de 4 bits es 15, lo que limita el encabezado a 60 bytes y por lo
tanto, el campo Opciones a 40 bytes. Para algunas opciones, por ejemplo una que registre la ruta que ha seguido un paquete, 40 bytes es muy poco, lo que hace inútiles estas opciones.
El campo de Servicio diferenciado es uno de los pocos campos que ha cambiado su significado (ligeramente) con el transcurso de los años. En un principio el nombre de este campo era Tipo de servicio. Su propósito era, y aún es, distinguir entre las diferentes clases de servicios. Son posibles varias combinaciones de confiabilidad y velocidad. Para voz digitalizada, la entrega rápida le gana a la entrega precisa. Para la transferencia de archivos, es más importante la transmisión libre de errores que la transmisión rápida.
El campo Tipo de servicio contaba con 3 bits para indicar la prioridad y 3 bits para indicar si a un host le preocupaba más el retardo, la velocidad de transmisión real o la confiabilidad. Sin embargo, nadie sabía realmente qué hacer con estos bits en los enrutadores, por lo que se quedaron sin uso durante muchos años. Cuando se diseñaron los servicios diferenciados, la IETF tiró la toalla y reutilizó este campo. Ahora, los 6 bits superiores se utilizan para marcar el paquete con su clase de servicio; anteriormente en este capítulo describimos los servicios expedito y asegurado. Los 2 bits inferiores se utilizan para transportar información sobre la notificación de congestión; por ejemplo, si el paquete ha experimentado congestión o no. Asimismo, también describimos la notificación explícita de congestión como parte del control de la congestión.
El campo Longitud total incluye todo en el datagrama: tanto el encabezado como los datos. La longitud máxima es de 65 535 bytes. En la actualidad este límite es tolerable, pero con las redes futuras tal vez se requieran datagramas más grandes.
El campo Identificación es necesario para que el host de destino determine a qué paquete pertenece un fragmento recién llegado. Todos los fragmentos de un paquete contienen el mismo valor de Identificación.
A continuación viene un bit sin uso, lo cual es sorprendente, ya que el espacio en el encabezado IP es muy escaso. Como broma del día de los inocentes, Bellovin (2003) propuso usar este bit para detectar el tráfico malicioso. Esto simplificaría de manera considerable la seguridad, puesto que se sabría que los paquetes con el bit “malo” habían sido enviados por atacantes y sólo había que descartarlos. Por desgracia, la seguridad de las redes no es tan simple. Después vienen dos campos de 1 bit relacionados con la fragmentación. DF significa no fragmentar (Don’t Fragment), es una orden para que los enrutadores no fragmenten el paquete. En un principio estaban destinados para soportar a los hosts incapaces de reunir las piezas otra vez. Ahora se utiliza como parte del proceso para descubrir la MTU de la ruta: el paquete más grande que puede viajar a través de una ruta sin necesidad de fragmentarse. Al marcar el datagrama con el bit DF, el emisor sabe que llegará en una pieza o recibirá de vuelta un mensaje de error.
MF significa más fragmentos (More Fragments). Todos los fragmentos excepto el último tienen establecido este bit, que es necesario para saber cuándo han llegado todos los fragmentos de un datagrama. El Desplazamiento del fragmento indica a qué parte del paquete actual pertenece este fragmento. Todos los fragmentos excepto el último del datagrama deben ser un múltiplo de 8 bytes, que es la unidad de fragmentos elemental. Dado que se proporcionan 13 bits, puede haber un máximo de 8 192 fragmentos por datagrama, para soportar una longitud máxima de paquete de hasta el límite del campo Longitud total. En conjunto, los campos Identificación, MF y Desplazamiento del fragmento se utilizan para implementar la fragmentación.
El campo TtL (Tiempo de vida) es un contador que se utiliza para limitar el tiempo de vida de un paquete. En un principio se suponía que iba a contar el tiempo en segundos, lo cual permitía un periodo de vida máximo de 255 seg. Hay que decrementarlo en cada salto y se supone que se decrementa muchas veces cuando un paquete se pone en cola durante un largo tiempo en un enrutador. En la práctica, simplemente cuenta los saltos. Cuando el contador llega a cero, el paquete se descarta y se envía de regreso un paquete de aviso al host de origen. Esta característica evita que los paquetes anden vagando eternamente, algo que de otra manera podría ocurrir si se llegaran a corromper las tablas de enrutamiento.
Una vez que la capa de red ha ensamblado un paquete completo, necesita saber qué hacer con él. El campo Protocolo le indica a cuál proceso de transporte debe entregar el paquete. TCP es una posibilidad, pero también están UDP y otros más. La numeración de los protocolos es global en toda la Internet.
Una característica que define a IPv4 consiste en sus direcciones de 32 bits. Cada host y enrutador de Internet tiene una dirección IP que se puede usar en los campos Dirección de origen y Dirección de destino de
los paquetes IP. Es importante tener en cuenta que una dirección IP en realidad no se refiere a un host, sino a una interfaz de red, por lo que si un host está en dos redes, debe tener dos direcciones IP. Sin embargo, en la práctica la mayoría de los hosts están en una red y, por ende, tienen una dirección IP. En contraste, los enrutadores tienen varias interfaces y, por lo tanto, múltiples direcciones IP.
Ahora es momento de examinar a conciencia la capa de red de Internet. Pero antes de entrar en detalles, vale la pena dar un vistazo a los principios que guiaron su diseño en el pasado y que hicieron posible el éxito que tiene hoy en día. En la actualidad, con frecuencia parece que la gente los ha olvidado. Estos principios se enumeran y analizan en el RFC 1958, el cual vale la pena leer. Este RFC utiliza mucho las ideas establecidas por Clark (1988) y por Saltzer y colaboradores.
En la capa de red, la Internet puede verse como un conjunto de redes, o Sistemas Autónomos (AS) interconectados. No hay una estructura real, pero existen varias redes troncales (backbones) principales. Éstas se construyen a partir de líneas de alto ancho de banda y enrutadores rápidos. Las más grandes de estas redes troncales, a la que se conectan todos los demás para llegar al resto de Internet, se llaman redes de Nivel 1. Conectadas a las redes troncales hay ISP (Proveedores de Servicio de Internet) que proporcionan acceso a Internet para los hogares y negocios, centros de datos e instalaciones de colocación
llenas de máquinas servidores y redes regionales (de nivel medio). Los centros de datos sirven gran parte del contenido que se envía a través de Internet. A las redes regionales están conectados más ISP, LAN de muchas universidades y empresas, y otras redes de punta. En la figura 5-45 se presenta un dibujo de esta organización cuasijerárquica.
El pegamento que mantiene unida a Internet es el protocolo de capa de red, IP (Protocolo de Internet, del inglés Internet Protocol). A diferencia de la mayoría de los protocolos de capa de red anteriores, IP se diseñó desde el principio con la interconexión de redes en mente. Una buena manera de visualizar la capa de red es la siguiente: su trabajo es proporcionar un medio de mejor esfuerzo (es decir, sin garantía) para transportar paquetes de la fuente al destino, sin importar si estas máquinas están en la misma red o si hay otras redes entre ellas.
La comunicación en Internet funciona de la siguiente manera. La capa de transporte toma flujos de datos y los divide para poder enviarlos como paquetes IP. En teoría, los paquetes pueden ser de hasta 64 Kbytes cada uno, pero en la práctica por lo general no sobrepasan los 1500 bytes (ya que son colocados en una trama de Ethernet). Los enrutadores IP reenvían cada paquete a través de Internet, a lo largo de una ruta de un enrutador a otro, hasta llegar al destino. En el destino, la capa de red entrega los datos a la capa de transporte, que a su vez los entrega al proceso receptor. Cuando todas las piezas llegan finalmente a la máquina de destino, la capa de red las vuelve a ensamblar para formar el datagrama original. A continuación este datagrama se entrega a la capa de transporte.
El protocolo IP versión 4
Un lugar adecuado para comenzar nuestro estudio de la capa de red de Internet es el formato de los datagramas de IP mismos. Un datagrama IPv4 consiste en dos partes: el encabezado y el cuerpo o carga útil. El encabezado tiene una parte fija de 20 bytes y una parte opcional de longitud variable. Los bits se transmiten en orden de izquierda a derecha y de arriba hacia abajo, comenzando por el bit de mayor orden del campo Versión (éste es un orden de bytes de red big endian. En las máquinas little endian, como las computadoras Intel x86, se requiere una conversión por software tanto para la transmisión como para la recepción). En retrospectiva, el formato little endian hubiera sido una mejor opción, pero al momento de diseñar IP nadie sabía que llegaría a dominar la computación.
El campo Versión lleva el registro de la versión del protocolo al que pertenece el datagrama. La versión 4 es la que domina Internet en la actualidad, y ahí es donde empezamos nuestro estudio. Al incluir la versión al inicio de cada datagrama, es posible tener una transición entre versiones a través de un largo periodo de tiempo. De hecho, IPv6 (la siguiente versión de IP) se definió hace más de una década y apenas se está empezando a implementar. Lo describiremos más adelante en esta sección. En un momento dado nos veremos obligados a usarlo cuando cada uno de los casi 231 habitantes de China tenga una PC de escritorio, una computadora portátil y un teléfono IP. Como observación adicional en cuanto a la numeración, IPv5 fue un protocolo de flujo experimental en tiempo real que nunca fue muy popular.
Dado que la longitud del encabezado no es constante, se incluye un campo en el encabezado (IHL) para indicar su longitud en palabras de 32 bits. El valor mínimo es de 5, cifra que se aplica cuando no hay opciones. El valor máximo de este campo de 4 bits es 15, lo que limita el encabezado a 60 bytes y por lo
tanto, el campo Opciones a 40 bytes. Para algunas opciones, por ejemplo una que registre la ruta que ha seguido un paquete, 40 bytes es muy poco, lo que hace inútiles estas opciones.
El campo de Servicio diferenciado es uno de los pocos campos que ha cambiado su significado (ligeramente) con el transcurso de los años. En un principio el nombre de este campo era Tipo de servicio. Su propósito era, y aún es, distinguir entre las diferentes clases de servicios. Son posibles varias combinaciones de confiabilidad y velocidad. Para voz digitalizada, la entrega rápida le gana a la entrega precisa. Para la transferencia de archivos, es más importante la transmisión libre de errores que la transmisión rápida.
El campo Tipo de servicio contaba con 3 bits para indicar la prioridad y 3 bits para indicar si a un host le preocupaba más el retardo, la velocidad de transmisión real o la confiabilidad. Sin embargo, nadie sabía realmente qué hacer con estos bits en los enrutadores, por lo que se quedaron sin uso durante muchos años. Cuando se diseñaron los servicios diferenciados, la IETF tiró la toalla y reutilizó este campo. Ahora, los 6 bits superiores se utilizan para marcar el paquete con su clase de servicio; anteriormente en este capítulo describimos los servicios expedito y asegurado. Los 2 bits inferiores se utilizan para transportar información sobre la notificación de congestión; por ejemplo, si el paquete ha experimentado congestión o no. Asimismo, también describimos la notificación explícita de congestión como parte del control de la congestión.
El campo Longitud total incluye todo en el datagrama: tanto el encabezado como los datos. La longitud máxima es de 65 535 bytes. En la actualidad este límite es tolerable, pero con las redes futuras tal vez se requieran datagramas más grandes.
El campo Identificación es necesario para que el host de destino determine a qué paquete pertenece un fragmento recién llegado. Todos los fragmentos de un paquete contienen el mismo valor de Identificación.
A continuación viene un bit sin uso, lo cual es sorprendente, ya que el espacio en el encabezado IP es muy escaso. Como broma del día de los inocentes, Bellovin (2003) propuso usar este bit para detectar el tráfico malicioso. Esto simplificaría de manera considerable la seguridad, puesto que se sabría que los paquetes con el bit “malo” habían sido enviados por atacantes y sólo había que descartarlos. Por desgracia, la seguridad de las redes no es tan simple. Después vienen dos campos de 1 bit relacionados con la fragmentación. DF significa no fragmentar (Don’t Fragment), es una orden para que los enrutadores no fragmenten el paquete. En un principio estaban destinados para soportar a los hosts incapaces de reunir las piezas otra vez. Ahora se utiliza como parte del proceso para descubrir la MTU de la ruta: el paquete más grande que puede viajar a través de una ruta sin necesidad de fragmentarse. Al marcar el datagrama con el bit DF, el emisor sabe que llegará en una pieza o recibirá de vuelta un mensaje de error.
MF significa más fragmentos (More Fragments). Todos los fragmentos excepto el último tienen establecido este bit, que es necesario para saber cuándo han llegado todos los fragmentos de un datagrama. El Desplazamiento del fragmento indica a qué parte del paquete actual pertenece este fragmento. Todos los fragmentos excepto el último del datagrama deben ser un múltiplo de 8 bytes, que es la unidad de fragmentos elemental. Dado que se proporcionan 13 bits, puede haber un máximo de 8 192 fragmentos por datagrama, para soportar una longitud máxima de paquete de hasta el límite del campo Longitud total. En conjunto, los campos Identificación, MF y Desplazamiento del fragmento se utilizan para implementar la fragmentación.
El campo TtL (Tiempo de vida) es un contador que se utiliza para limitar el tiempo de vida de un paquete. En un principio se suponía que iba a contar el tiempo en segundos, lo cual permitía un periodo de vida máximo de 255 seg. Hay que decrementarlo en cada salto y se supone que se decrementa muchas veces cuando un paquete se pone en cola durante un largo tiempo en un enrutador. En la práctica, simplemente cuenta los saltos. Cuando el contador llega a cero, el paquete se descarta y se envía de regreso un paquete de aviso al host de origen. Esta característica evita que los paquetes anden vagando eternamente, algo que de otra manera podría ocurrir si se llegaran a corromper las tablas de enrutamiento.
Una vez que la capa de red ha ensamblado un paquete completo, necesita saber qué hacer con él. El campo Protocolo le indica a cuál proceso de transporte debe entregar el paquete. TCP es una posibilidad, pero también están UDP y otros más. La numeración de los protocolos es global en toda la Internet.
Una característica que define a IPv4 consiste en sus direcciones de 32 bits. Cada host y enrutador de Internet tiene una dirección IP que se puede usar en los campos Dirección de origen y Dirección de destino de
los paquetes IP. Es importante tener en cuenta que una dirección IP en realidad no se refiere a un host, sino a una interfaz de red, por lo que si un host está en dos redes, debe tener dos direcciones IP. Sin embargo, en la práctica la mayoría de los hosts están en una red y, por ende, tienen una dirección IP. En contraste, los enrutadores tienen varias interfaces y, por lo tanto, múltiples direcciones IP.
7.4) Capa de aplicación
Habiendo concluido todos los preliminares, ahora llegamos a la capa en donde se encuentran todas las aplicaciones. Las capas por debajo de la de aplicación están ahí para proporcionar servicios de transporte, pero no hacen ningún trabajo verdadero para los usuarios. En este capítulo estudiaremos algunas aplicaciones de red reales. Sin embargo, incluso en la capa de aplicación se necesitan protocolos de apoyo que permitan el funcionamiento de las aplicaciones. En consecuencia, veremos uno de estos protocolos importantes antes de comenzar con las aplicaciones. El elemento en cuestión es el DNS, que maneja la asociación de nombres dentro de Internet.
Habiendo concluido todos los preliminares, ahora llegamos a la capa en donde se encuentran todas las aplicaciones. Las capas por debajo de la de aplicación están ahí para proporcionar servicios de transporte, pero no hacen ningún trabajo verdadero para los usuarios. En este capítulo estudiaremos algunas aplicaciones de red reales. Sin embargo, incluso en la capa de aplicación se necesitan protocolos de apoyo que permitan el funcionamiento de las aplicaciones. En consecuencia, veremos uno de estos protocolos importantes antes de comenzar con las aplicaciones. El elemento en cuestión es el DNS, que maneja la asociación de nombres dentro de Internet.
7.4.1) DNS: El sistema de nombres de dominio
Aunque en teoría los programas pueden hacer referencia a páginas web, buzones de correo y otros recursos mediante las direcciones de red (por ejemplo, IP) de las computadoras en las que se almacenan, a las personas se les dificulta recordar estas direcciones. Además, navegar en las páginas web de una empresa desde un servidor con la dirección 128.111.24.41 significa que si la compañía mueve el servidor web a una máquina diferente con una dirección IP distinta, hay que avisar a todos sobre la nueva dirección IP. Por este motivo se introdujeron nombres legibles de alto nivel con el fin de separar los nombres de máquina de las direcciones de máquina. De esta manera, el servidor web de la empresa podría conocerse como www.cs.washington.edu sin importar cuál sea su dirección IP. Sin embargo, como la red sólo comprende direcciones numéricas, se requiere algún mecanismo para convertir los nombres en direcciones de red. En las siguientes secciones analizaremos la forma en que se logra esta correspondencia.
Hace mucho, en los tiempos de ARPANET sólo había un archivo, hosts.txt, en el que se listaban todos los nombres de computadoras y sus direcciones IP. Cada noche, todos los hosts obtenían este archivo del sitio en el que se almacenaba. En una red conformada por unos cuantos cientos de grandes máquinas de tiempo compartido este método funcionaba razonablemente bien.
Sin embargo, antes de que se conectaran millones de computadoras PC a Internet, los involucrados se dieron cuenta de que este método no funcionaría eternamente. Por una parte, el tamaño de cada archivo crecería de manera considerable. Sin embargo, un problema aún mayor eran los constantes conflictos con los nombres de los hosts, a menos que dichos nombres se administraran en forma central (algo impensable en una enorme red internacional debido a su carga y latencia). Para resolver estos problemas, en 1983 se inventó el DNS (Sistema de Nombres de Dominio, del inglés Domain Name System), el cual ha sido una parte clave de Internet desde entonces.
La esencia del DNS es la invención de un esquema jerárquico de nombres basado en dominios y un sistema de base de datos distribuido para implementar este esquema de nombres. El DNS se usa principalmente para asociar los nombres de host con las direcciones IP, pero también se puede usar para otros fines. El DNS se define en los RFC 1034, 1035, 2181 y se elabora con más detalle en muchos otros. Dicho en forma muy breve, la forma en que se utiliza el DNS es la siguiente. Para asociar un nombre con una dirección IP, un programa de aplicación llama a un procedimiento de biblioteca llamado resolvedor y le pasa el nombre como parámetro. En la figura 6.6 vimos un ejemplo de un resolvedor, gethostbyname. El cual envía una consulta que contiene el nombre a un servidor DNS local, que después busca el nombre y devuelve una respuesta con la dirección IP al resolvedor, que a su vez lo devuelve al solicitante. Los mensajes de solicitud y respuesta se envían como paquetes UDP. Armado con la dirección IP, el programa puede entonces establecer una conexión TCP con el host o enviarle paquetes UDP.
El espacio de nombres del DNS
La administración de un conjunto grande de nombres que cambian en forma continua no es un problema sencillo. En el sistema postal, para administrar los nombres se requieren letras que especifiquen (de manera implícita o explícita) el país, estado o provincia, ciudad, calle y nombre del destinatario. Con este tipo de direccionamiento jerárquico, se asegura que no haya confusión entre el Marvin Anderson, de Main St., en White Plains, N.Y., y el Marvin Anderson, de Main St., en Austin, Texas. El DNS funciona de la misma manera.
En Internet, el nivel superior de la jerarquía de nombres se administra mediante una organización llamada ICANN (Corporación de Internet para la Asignación de Nombres y Números, del inglés Internet Corporation for Assigned Names and Numbers), la cual se creó para este fin en 1998 como parte del proceso de maduración de Internet, que se convirtió en un asunto económico a nivel mundial. En concepto, Internet se divide en más de 250 dominios de nivel superior, cada uno de los cuales abarca muchos hosts. Cada dominio se divide en subdominios, los que a su vez también se dividen, y así en lo sucesivo. Todos estos dominios se pueden representar mediante un árbol.
Las hojas del árbol representan los dominios que no tienen subdominios (pero que, por supuesto, contienen máquinas). Un dominio de hoja puede contener un solo host, o puede representar a una compañía y contener miles de hosts. Los dominios de nivel superior se dividen en dos categorías: genéricos y países. Los dominios genéricos, incluyen los dominios originales de la década de 1980 y los dominios introducidos mediante solicitudes a la ICANN. En lo futuro se agregarán otros dominios genéricos de nivel superior.
Los dominios de país incluyen una entrada para cada país, como se define en la ISO 3166. En 2010 se introdujeron nombres de dominio internacionalizados de países en los que se utilizan alfabetos distintos al latín. Estos dominios permiten nombrar hosts en árabe, cirílico, chino u otros idiomas.
En general, es fácil obtener un dominio de segundo nivel, como nombre-de-compañía.com. Los dominios de nivel superior son operados por registradores nombrados por la ICANN. Sólo es necesario ir con el registrador correspondiente (com, en este caso) para ver si el nombre deseado está disponible y si no es la marca registrada de alguien más. Si no hay problemas, el solicitante paga una pequeña cuota anual y obtiene el nombre.
Los nombres de dominio pueden ser absolutos o relativos. Un nombre de dominio absoluto siempre termina con un punto (por ejemplo, eng.cisco.com.), mientras que uno relativo no. Los nombres relativos se tienen que interpretar en cierto contexto para determinar de manera única su significado verdadero. En ambos casos, un dominio nombrado hace referencia a un nodo específico del árbol y a todos los nodos por debajo de él.
Los nombres de dominio no hacen distinción entre mayúsculas y minúsculas, por lo que edu, Edu y EDU significan lo mismo. Los nombres de componentes pueden ser de hasta 63 caracteres de longitud, y los de ruta completa no deben exceder de 255 caracteres.
Registros de recursos de dominios
Cada dominio, sea un host individual o un dominio de nivel superior, puede tener un grupo de registros de recursos asociados a él. Estos registros son la base de datos del DNS. En un host individual, el registro de recursos más común es simplemente su dirección IP, pero también existen muchos otros tipos de registros de recursos. Cuando un resolvedor asigna un nombre de dominio al DNS, lo que recibe son los registros de recursos asociados a ese nombre. Por lo tanto, la función principal del DNS es relacionar los nombres de dominios con los registros de recursos.
Un registro de recursos es una 5-tupla. Aunque éstas se codifican en binario por cuestión de eficiencia, en la mayoría de las presentaciones, los registros de recursos se presentan como texto ASCII, una línea por registro de recursos. El formato que usaremos es el siguiente:
El Nombre_dominio indica el dominio al que pertenece este registro. Por lo general, existen muchos registros por dominio y cada copia de la base de datos contiene información sobre múltiples dominios. Por lo tanto, este campo es la clave primaria de búsqueda que se utiliza para atender las consultas. El orden de los registros de la base de datos no es importante.
El campo de Tiempo_de_vida es una indicación de la estabilidad del registro. La información altamente estable recibe un valor grande, como 86 400 (la cantidad de segundos en 1 día). A la información que es altamente volátil se le asigna un valor pequeño, como 60 (1 minuto). Regresaremos a este punto después de estudiar el uso de caché.
El tercer campo de cada registro de recursos es la Clase. Para información de Internet, siempre es IN. Para información que no es de Internet se pueden utilizar otros códigos, pero en la práctica, éstos raras veces se ven.
El campo Tipo indica el tipo de registro del que se trata. Hay muchos tipos de registros de DNS.
Aunque en teoría los programas pueden hacer referencia a páginas web, buzones de correo y otros recursos mediante las direcciones de red (por ejemplo, IP) de las computadoras en las que se almacenan, a las personas se les dificulta recordar estas direcciones. Además, navegar en las páginas web de una empresa desde un servidor con la dirección 128.111.24.41 significa que si la compañía mueve el servidor web a una máquina diferente con una dirección IP distinta, hay que avisar a todos sobre la nueva dirección IP. Por este motivo se introdujeron nombres legibles de alto nivel con el fin de separar los nombres de máquina de las direcciones de máquina. De esta manera, el servidor web de la empresa podría conocerse como www.cs.washington.edu sin importar cuál sea su dirección IP. Sin embargo, como la red sólo comprende direcciones numéricas, se requiere algún mecanismo para convertir los nombres en direcciones de red. En las siguientes secciones analizaremos la forma en que se logra esta correspondencia.
Hace mucho, en los tiempos de ARPANET sólo había un archivo, hosts.txt, en el que se listaban todos los nombres de computadoras y sus direcciones IP. Cada noche, todos los hosts obtenían este archivo del sitio en el que se almacenaba. En una red conformada por unos cuantos cientos de grandes máquinas de tiempo compartido este método funcionaba razonablemente bien.
Sin embargo, antes de que se conectaran millones de computadoras PC a Internet, los involucrados se dieron cuenta de que este método no funcionaría eternamente. Por una parte, el tamaño de cada archivo crecería de manera considerable. Sin embargo, un problema aún mayor eran los constantes conflictos con los nombres de los hosts, a menos que dichos nombres se administraran en forma central (algo impensable en una enorme red internacional debido a su carga y latencia). Para resolver estos problemas, en 1983 se inventó el DNS (Sistema de Nombres de Dominio, del inglés Domain Name System), el cual ha sido una parte clave de Internet desde entonces.
La esencia del DNS es la invención de un esquema jerárquico de nombres basado en dominios y un sistema de base de datos distribuido para implementar este esquema de nombres. El DNS se usa principalmente para asociar los nombres de host con las direcciones IP, pero también se puede usar para otros fines. El DNS se define en los RFC 1034, 1035, 2181 y se elabora con más detalle en muchos otros. Dicho en forma muy breve, la forma en que se utiliza el DNS es la siguiente. Para asociar un nombre con una dirección IP, un programa de aplicación llama a un procedimiento de biblioteca llamado resolvedor y le pasa el nombre como parámetro. En la figura 6.6 vimos un ejemplo de un resolvedor, gethostbyname. El cual envía una consulta que contiene el nombre a un servidor DNS local, que después busca el nombre y devuelve una respuesta con la dirección IP al resolvedor, que a su vez lo devuelve al solicitante. Los mensajes de solicitud y respuesta se envían como paquetes UDP. Armado con la dirección IP, el programa puede entonces establecer una conexión TCP con el host o enviarle paquetes UDP.
El espacio de nombres del DNS
La administración de un conjunto grande de nombres que cambian en forma continua no es un problema sencillo. En el sistema postal, para administrar los nombres se requieren letras que especifiquen (de manera implícita o explícita) el país, estado o provincia, ciudad, calle y nombre del destinatario. Con este tipo de direccionamiento jerárquico, se asegura que no haya confusión entre el Marvin Anderson, de Main St., en White Plains, N.Y., y el Marvin Anderson, de Main St., en Austin, Texas. El DNS funciona de la misma manera.
En Internet, el nivel superior de la jerarquía de nombres se administra mediante una organización llamada ICANN (Corporación de Internet para la Asignación de Nombres y Números, del inglés Internet Corporation for Assigned Names and Numbers), la cual se creó para este fin en 1998 como parte del proceso de maduración de Internet, que se convirtió en un asunto económico a nivel mundial. En concepto, Internet se divide en más de 250 dominios de nivel superior, cada uno de los cuales abarca muchos hosts. Cada dominio se divide en subdominios, los que a su vez también se dividen, y así en lo sucesivo. Todos estos dominios se pueden representar mediante un árbol.
Las hojas del árbol representan los dominios que no tienen subdominios (pero que, por supuesto, contienen máquinas). Un dominio de hoja puede contener un solo host, o puede representar a una compañía y contener miles de hosts. Los dominios de nivel superior se dividen en dos categorías: genéricos y países. Los dominios genéricos, incluyen los dominios originales de la década de 1980 y los dominios introducidos mediante solicitudes a la ICANN. En lo futuro se agregarán otros dominios genéricos de nivel superior.
Los dominios de país incluyen una entrada para cada país, como se define en la ISO 3166. En 2010 se introdujeron nombres de dominio internacionalizados de países en los que se utilizan alfabetos distintos al latín. Estos dominios permiten nombrar hosts en árabe, cirílico, chino u otros idiomas.
En general, es fácil obtener un dominio de segundo nivel, como nombre-de-compañía.com. Los dominios de nivel superior son operados por registradores nombrados por la ICANN. Sólo es necesario ir con el registrador correspondiente (com, en este caso) para ver si el nombre deseado está disponible y si no es la marca registrada de alguien más. Si no hay problemas, el solicitante paga una pequeña cuota anual y obtiene el nombre.
Los nombres de dominio pueden ser absolutos o relativos. Un nombre de dominio absoluto siempre termina con un punto (por ejemplo, eng.cisco.com.), mientras que uno relativo no. Los nombres relativos se tienen que interpretar en cierto contexto para determinar de manera única su significado verdadero. En ambos casos, un dominio nombrado hace referencia a un nodo específico del árbol y a todos los nodos por debajo de él.
Los nombres de dominio no hacen distinción entre mayúsculas y minúsculas, por lo que edu, Edu y EDU significan lo mismo. Los nombres de componentes pueden ser de hasta 63 caracteres de longitud, y los de ruta completa no deben exceder de 255 caracteres.
Registros de recursos de dominios
Cada dominio, sea un host individual o un dominio de nivel superior, puede tener un grupo de registros de recursos asociados a él. Estos registros son la base de datos del DNS. En un host individual, el registro de recursos más común es simplemente su dirección IP, pero también existen muchos otros tipos de registros de recursos. Cuando un resolvedor asigna un nombre de dominio al DNS, lo que recibe son los registros de recursos asociados a ese nombre. Por lo tanto, la función principal del DNS es relacionar los nombres de dominios con los registros de recursos.
Un registro de recursos es una 5-tupla. Aunque éstas se codifican en binario por cuestión de eficiencia, en la mayoría de las presentaciones, los registros de recursos se presentan como texto ASCII, una línea por registro de recursos. El formato que usaremos es el siguiente:
Nombre_dominio Tiempo_de_vida Clase Tipo Valor
El Nombre_dominio indica el dominio al que pertenece este registro. Por lo general, existen muchos registros por dominio y cada copia de la base de datos contiene información sobre múltiples dominios. Por lo tanto, este campo es la clave primaria de búsqueda que se utiliza para atender las consultas. El orden de los registros de la base de datos no es importante.
El campo de Tiempo_de_vida es una indicación de la estabilidad del registro. La información altamente estable recibe un valor grande, como 86 400 (la cantidad de segundos en 1 día). A la información que es altamente volátil se le asigna un valor pequeño, como 60 (1 minuto). Regresaremos a este punto después de estudiar el uso de caché.
El tercer campo de cada registro de recursos es la Clase. Para información de Internet, siempre es IN. Para información que no es de Internet se pueden utilizar otros códigos, pero en la práctica, éstos raras veces se ven.
El campo Tipo indica el tipo de registro del que se trata. Hay muchos tipos de registros de DNS.
7.4.2) Correo electrónico
El correo electrónico o email, como se le conoce comúnmente, ha existido por más de tres décadas. Puesto que es mucho más rápido y económico que el correo convencional, el correo electrónico ha sido una aplicación popular desde los primeros días de Internet. Antes de 1990 se utilizaba principalmente en ambientes académicos. En la década de 1990 se dio a conocer al público en general y creció en forma exponencial, al punto que el número de mensajes de correo electrónico enviados por día ahora es mucho mayor que el número de cartas por correo fuera de línea (es decir, en papel). Existen otras formas de comunicación en red, como la mensajería instantánea y las llamadas de voz sobre IP, cuyo uso se ha expandido en forma considerable durante la última década, pero el correo electrónico sigue siendo el caballo de batalla de la comunicación en Internet. Se utiliza mucho dentro de la industria para la comunicación entre empresas.
El correo electrónico, como la mayoría de otras formas de comunicación, ha desarrollado sus propias convenciones y estilos. Es muy informal y tiene un umbral bajo de uso. Las personas que nunca hubieran soñado con escribir una carta a un personaje importante, no dudarían un instante para enviarle un mensaje de correo electrónico. Al eliminar la mayoría de las indicaciones asociadas con el rango, la edad y el género, los debates por correo electrónico se enfocan por lo regular en el contenido y no en el estatus.
El correo electrónico está lleno de abreviaturas, como SYL (See You Later, en español: nos vemos luego), FYI (For Your Information, en español: para su información) o TQM (Te Quiero Mucho). Muchas personas también utilizan pequeños símbolos ASCII llamados caritas (emoticones), que empiezan con el ubicuo “:-)”.
Los protocolos de correo electrónico también han evolucionado durante el periodo en que se han utilizado. Los primeros sistemas simplemente consistían en protocolos de transferencia de archivos, con la convención de que la primera línea de cada mensaje (es decir, archivo) contenía la dirección del destinatario. A medida que pasó el tiempo, el correo electrónico se separó de la transferencia de archivos y se agregaron muchas características, como la habilidad de enviar un mensaje a una lista de contactos. Las herramientas multimedia se hicieron populares en 1990 para enviar mensajes con imágenes y otros materiales además del texto. Los programas para leer correo electrónico se hicieron mucho más sofisticados también, pues cambiaron de una interfaz basada en texto a las interfaces gráficas de usuario, además de agregar la capacidad de que los usuarios accedieran a su correo desde sus laptops en donde quiera que se encontraran. Finalmente, con la prevalencia del correo spam, ahora los lectores de correo y los protocolos de transferencia de correo deben poner atención, a cómo detectar y eliminar el correo electrónico no deseado.
El correo electrónico o email, como se le conoce comúnmente, ha existido por más de tres décadas. Puesto que es mucho más rápido y económico que el correo convencional, el correo electrónico ha sido una aplicación popular desde los primeros días de Internet. Antes de 1990 se utilizaba principalmente en ambientes académicos. En la década de 1990 se dio a conocer al público en general y creció en forma exponencial, al punto que el número de mensajes de correo electrónico enviados por día ahora es mucho mayor que el número de cartas por correo fuera de línea (es decir, en papel). Existen otras formas de comunicación en red, como la mensajería instantánea y las llamadas de voz sobre IP, cuyo uso se ha expandido en forma considerable durante la última década, pero el correo electrónico sigue siendo el caballo de batalla de la comunicación en Internet. Se utiliza mucho dentro de la industria para la comunicación entre empresas.
El correo electrónico, como la mayoría de otras formas de comunicación, ha desarrollado sus propias convenciones y estilos. Es muy informal y tiene un umbral bajo de uso. Las personas que nunca hubieran soñado con escribir una carta a un personaje importante, no dudarían un instante para enviarle un mensaje de correo electrónico. Al eliminar la mayoría de las indicaciones asociadas con el rango, la edad y el género, los debates por correo electrónico se enfocan por lo regular en el contenido y no en el estatus.
El correo electrónico está lleno de abreviaturas, como SYL (See You Later, en español: nos vemos luego), FYI (For Your Information, en español: para su información) o TQM (Te Quiero Mucho). Muchas personas también utilizan pequeños símbolos ASCII llamados caritas (emoticones), que empiezan con el ubicuo “:-)”.
Los protocolos de correo electrónico también han evolucionado durante el periodo en que se han utilizado. Los primeros sistemas simplemente consistían en protocolos de transferencia de archivos, con la convención de que la primera línea de cada mensaje (es decir, archivo) contenía la dirección del destinatario. A medida que pasó el tiempo, el correo electrónico se separó de la transferencia de archivos y se agregaron muchas características, como la habilidad de enviar un mensaje a una lista de contactos. Las herramientas multimedia se hicieron populares en 1990 para enviar mensajes con imágenes y otros materiales además del texto. Los programas para leer correo electrónico se hicieron mucho más sofisticados también, pues cambiaron de una interfaz basada en texto a las interfaces gráficas de usuario, además de agregar la capacidad de que los usuarios accedieran a su correo desde sus laptops en donde quiera que se encontraran. Finalmente, con la prevalencia del correo spam, ahora los lectores de correo y los protocolos de transferencia de correo deben poner atención, a cómo detectar y eliminar el correo electrónico no deseado.
7.4.3) World Wide Web
La web, popularmente conocida como World Wide Web, es un marco arquitectónico para acceder a cierto contenido vinculado distribuido en millones de máquinas por toda Internet. En 10 años pasó de ser una manera de coordinar el diseño de los experimentos de física de alta energía en Suiza a la aplicación que millones de personas piensan que es “Internet”. Su enorme popularidad se deriva del hecho de que es fácil de usar para los principiantes, además de que provee acceso mediante una interfaz gráfica a un enorme cúmulo de información sobre casi cualquier tema concebible, desde aborígenes hasta zoología.
La web (también conocida como WWW ) comenzó en 1989 en el cern, el Centro Europeo de Investigación Nuclear. La idea inicial era ayudar a los equipos grandes, a menudo con miembros en media docena de países y zonas horarias o más, a que colaboraran mediante el uso de un conjunto siempre cambiante de informes, planos, dibujos, fotografías y demás documentos producidos por los experimentos de partículas en física. La propuesta de una red de documentos vinculados surgió de Tim Berners-Lee, físico del cern. El primer prototipo (basado en texto) estaba en operación 18 meses después. Una demostración pública en la conferencia Hypertext ’91 atrapó la atención de otros investigadores, lo que llevó a Marc Andressen, de la Universidad de Illinois, a desarrollar el primer navegador gráfico. Se llamó Mosaic y se liberó en febrero de 1993.
El resto, como dicen, es historia. Mosaic fue tan popular que un año más tarde, Andreessen formó su propia compañía llamada Netscape Communications Corp., cuya meta era desarrollar software web. Durante los siguientes tres años, Netscape Navigator y Microsoft Internet Explorer sostuvieron una “guerra de navegadores”, en donde cada uno trataba de capturar una mayor parte del nuevo mercado al agregar frenéticamente más características (y, por ende, más errores) que el otro.
Durante las décadas de 1990 y 2000, los sitios web y las páginas web, como se le dice al contenido web, crecieron en forma exponencial hasta que hubo millones de sitios y miles de millones de páginas. Una pequeña cantidad de estos sitios se hicieron muy populares. Esos sitios y las empresas que los respaldan son los que definen en gran parte la web y la forma en que las personas la experimentan en la actualidad.
En 1994, el cern y el MIT firmaron un acuerdo para establecer el W3C (Consorcio World Wide Web, del inglés World Wide Web Consortium), una organización dedicada al desarrollo de web, a la estandarización de protocolos y a fomentar la interoperabilidad entre los sitios. Berners-Lee se convirtió en el director. Desde entonces, cientos de universidades y compañías se han unido al consorcio. Aunque ahora hay más libros sobre la web de los que podemos contar, el mejor lugar para recibir información actualizada sobre ella es (naturalmente) la web misma. La página de inicio del consorcio se encuentra en www.w3.org. Los lectores interesados pueden encontrar ahí vínculos con páginas que cubren todos los numerosos documentos y actividades del consorcio.
Panorama de la arquitectura
Desde el punto de vista del usuario, la web consiste en una enorme colección de contenido en forma de páginas web, por lo general, conocidas simplemente como páginas. Cada una puede contener vínculos a otras páginas en cualquier lugar del mundo. Para seguir un vínculo, los usuarios pueden hacer clic en él, y a continuación los llevará a la página apuntada. Este proceso se puede repetir de manera indefinida. La idea de hacer que una página apunte a otra, lo que ahora se conoce como hipertexto, fue inventada por un profesor visionario de ingeniería eléctrica del MIT, Vannevar Bush, en 1945 (Bush, 1945). Esto fue mucho antes de que se inventara Internet. De hecho, fue antes de que existieran las computadoras comerciales, aunque varias universidades habían producido prototipos que ocupaban habitaciones extensas pero tenían menos poder que una moderna calculadora de bolsillo.
Para obtener cada página, se envía una solicitud a uno o más servidores, los cuales responden con el contenido de la página. El protocolo de solicitud-respuesta para obtener páginas es un protocolo simple basado en texto que se ejecuta sobre TCP, como en el caso de SMTP. Este protocolo se llama HTTP (Protocolo de Transferencia de HiperTexto, del inglés HyperText Transfer Protocol ). El contenido puede ser simplemente un documento que se lea de un disco, o el resultado de una consulta en una base de datos y la ejecución de un programa. La página se considera una página estática si es el mismo documento cada vez que se despliega en pantalla. Por el
contrario, si se generó bajo demanda mediante un programa o contiene uno, es una página dinámica. Una página dinámica se puede presentar de manera distinta cada vez que se despliega en pantalla. Por ejemplo, la página principal de una tienda electrónica puede ser distinta para cada visitante. Si el cliente de una librería ha comprado novelas de misterio en sus anteriores visitas, es probable que la próxima vez le aparezcan las nuevas novelas de misterio en la página de inicio; mientras que un cliente enfocado hacia lo culinario podría ser recibido con nuevos libros de cocina. La manera en que el sitio web mantiene el registro de los gustos de cada cliente es algo que veremos en breve. En sí, la respuesta involucra el uso de cookies.
La web, popularmente conocida como World Wide Web, es un marco arquitectónico para acceder a cierto contenido vinculado distribuido en millones de máquinas por toda Internet. En 10 años pasó de ser una manera de coordinar el diseño de los experimentos de física de alta energía en Suiza a la aplicación que millones de personas piensan que es “Internet”. Su enorme popularidad se deriva del hecho de que es fácil de usar para los principiantes, además de que provee acceso mediante una interfaz gráfica a un enorme cúmulo de información sobre casi cualquier tema concebible, desde aborígenes hasta zoología.
La web (también conocida como WWW ) comenzó en 1989 en el cern, el Centro Europeo de Investigación Nuclear. La idea inicial era ayudar a los equipos grandes, a menudo con miembros en media docena de países y zonas horarias o más, a que colaboraran mediante el uso de un conjunto siempre cambiante de informes, planos, dibujos, fotografías y demás documentos producidos por los experimentos de partículas en física. La propuesta de una red de documentos vinculados surgió de Tim Berners-Lee, físico del cern. El primer prototipo (basado en texto) estaba en operación 18 meses después. Una demostración pública en la conferencia Hypertext ’91 atrapó la atención de otros investigadores, lo que llevó a Marc Andressen, de la Universidad de Illinois, a desarrollar el primer navegador gráfico. Se llamó Mosaic y se liberó en febrero de 1993.
El resto, como dicen, es historia. Mosaic fue tan popular que un año más tarde, Andreessen formó su propia compañía llamada Netscape Communications Corp., cuya meta era desarrollar software web. Durante los siguientes tres años, Netscape Navigator y Microsoft Internet Explorer sostuvieron una “guerra de navegadores”, en donde cada uno trataba de capturar una mayor parte del nuevo mercado al agregar frenéticamente más características (y, por ende, más errores) que el otro.
Durante las décadas de 1990 y 2000, los sitios web y las páginas web, como se le dice al contenido web, crecieron en forma exponencial hasta que hubo millones de sitios y miles de millones de páginas. Una pequeña cantidad de estos sitios se hicieron muy populares. Esos sitios y las empresas que los respaldan son los que definen en gran parte la web y la forma en que las personas la experimentan en la actualidad.
En 1994, el cern y el MIT firmaron un acuerdo para establecer el W3C (Consorcio World Wide Web, del inglés World Wide Web Consortium), una organización dedicada al desarrollo de web, a la estandarización de protocolos y a fomentar la interoperabilidad entre los sitios. Berners-Lee se convirtió en el director. Desde entonces, cientos de universidades y compañías se han unido al consorcio. Aunque ahora hay más libros sobre la web de los que podemos contar, el mejor lugar para recibir información actualizada sobre ella es (naturalmente) la web misma. La página de inicio del consorcio se encuentra en www.w3.org. Los lectores interesados pueden encontrar ahí vínculos con páginas que cubren todos los numerosos documentos y actividades del consorcio.
Panorama de la arquitectura
Desde el punto de vista del usuario, la web consiste en una enorme colección de contenido en forma de páginas web, por lo general, conocidas simplemente como páginas. Cada una puede contener vínculos a otras páginas en cualquier lugar del mundo. Para seguir un vínculo, los usuarios pueden hacer clic en él, y a continuación los llevará a la página apuntada. Este proceso se puede repetir de manera indefinida. La idea de hacer que una página apunte a otra, lo que ahora se conoce como hipertexto, fue inventada por un profesor visionario de ingeniería eléctrica del MIT, Vannevar Bush, en 1945 (Bush, 1945). Esto fue mucho antes de que se inventara Internet. De hecho, fue antes de que existieran las computadoras comerciales, aunque varias universidades habían producido prototipos que ocupaban habitaciones extensas pero tenían menos poder que una moderna calculadora de bolsillo.
Para obtener cada página, se envía una solicitud a uno o más servidores, los cuales responden con el contenido de la página. El protocolo de solicitud-respuesta para obtener páginas es un protocolo simple basado en texto que se ejecuta sobre TCP, como en el caso de SMTP. Este protocolo se llama HTTP (Protocolo de Transferencia de HiperTexto, del inglés HyperText Transfer Protocol ). El contenido puede ser simplemente un documento que se lea de un disco, o el resultado de una consulta en una base de datos y la ejecución de un programa. La página se considera una página estática si es el mismo documento cada vez que se despliega en pantalla. Por el
contrario, si se generó bajo demanda mediante un programa o contiene uno, es una página dinámica. Una página dinámica se puede presentar de manera distinta cada vez que se despliega en pantalla. Por ejemplo, la página principal de una tienda electrónica puede ser distinta para cada visitante. Si el cliente de una librería ha comprado novelas de misterio en sus anteriores visitas, es probable que la próxima vez le aparezcan las nuevas novelas de misterio en la página de inicio; mientras que un cliente enfocado hacia lo culinario podría ser recibido con nuevos libros de cocina. La manera en que el sitio web mantiene el registro de los gustos de cada cliente es algo que veremos en breve. En sí, la respuesta involucra el uso de cookies.
7.5) Subcapa de control de acceso al medio
Los enlaces de red se pueden dividir en dos categorías: los que utilizan conexiones punto a punto y los que utilizan canales de difusión. En cualquier red de difusión, el asunto clave es la manera de determinar quién puede utilizar el canal cuando tiene competencia por él. Para aclarar este punto, considere una llamada en conferencia en la que seis personas, en seis teléfonos diferentes, están conectadas de modo que cada una puede oír y hablar con todas las demás. Es muy probable que cuando una de ellas deje de hablar, dos o más comiencen a hacerlo al mismo tiempo, lo que conducirá al caos. En una reunión cara a cara, el caos se evita por medios competentes. Por ejemplo, en una reunión la gente levanta la mano para solicitar permiso para hablar. Cuando sólo hay un canal disponible, es mucho más difícil determinar quién debería tener el turno. Se conocen muchos protocolos para resolver el problema, los cuales forman el contenido de este capítulo.
En la literatura, los canales de difusión a veces se denominan canales multiacceso o canales de acceso aleatorio. Los protocolos que se utilizan para determinar quién sigue en un canal multiacceso pertenecen a una subcapa de la capa de enlace de datos llamada subcapa MAC (Control de Acceso al Medio, del inglés Medium Access Control). La subcapa MAC tiene especial importancia en las LAN, en especial las inalámbricas puesto que el canal inalámbrico es de difusión por naturaleza. En contraste, las WAN usan enlaces punto a punto, excepto en las redes satelitales. Debido a que los canales multiacceso y las LAN están muy relacionados, en este capítulo analizaremos las LAN en general, además de algunos aspectos que no son estrictamente parte de la subcapa MAC, pero el tema principal será el control del canal.
7.5.1) Asignación de canal
El tema central de este capítulo es la forma de asignar un solo canal de difusión entre usuarios competidores. El canal podría ser una parte del espectro inalámbrico en una región geográfica, o un solo alambre o fibra óptica en donde se conectan varios nodos. Esto no es importante. En ambos casos, el canal conecta a cada usuario con todos los demás; cualquier usuario que utilice todo el canal interfiere con los demás que también desean usarlo.
Primero veremos las deficiencias de los esquemas de asignación estática para el tráfico en ráfagas. Después estableceremos las suposiciones clave que se utilizan para modelar los esquemas dinámicos que examinaremos en las siguientes secciones.
Asignación estática de canal
La manera tradicional de asignar un solo canal, como una troncal telefónica, entre múltiples usuarios competidores es dividir su capacidad mediante el uso de uno de los esquemas de multiplexión, como el FDM (Multiplexión por División de Frecuencia, del inglés Frequency Division Multiplexing). Si hay N usuarios, el ancho de banda se divide en N partes de igual tamaño, y a cada usuario se le asigna una parte. Debido a que cada usuario tiene una banda de frecuencia privada, ahora no hay interferencia entre ellos. Cuando sólo hay una pequeña cantidad fija y constante de usuarios, cada uno tiene un flujo estable o una carga de tráfico pesada, esta división es un mecanismo de asignación sencillo y eficiente. Las estaciones de radio de FM son un ejemplo inalámbrico. Cada estación recibe una parte de la banda de FM y la utiliza la mayor parte del tiempo para difundir su señal. Sin embargo, cuando el número de emisores es grande y varía continuamente, o cuando el tráfico se hace en ráfagas, el FDM presenta algunos problemas. Si el espectro se divide en N regiones y actualmente hay menos de N usuarios interesados en comunicarse, se desperdiciará una buena parte del valioso espectro. Y si más de N usuarios quieren comunicarse, a algunos de ellos se les negará el permiso por falta de ancho de banda, aun cuando algunos de los usuarios que tengan asignada una banda de frecuencia apenas transmitan o reciban algo.
Aun suponiendo que el número de usuarios podría, de alguna manera, mantenerse constante en N, dividir el único canal disponible en varios subcanales estáticos es ineficiente por naturaleza. El problema básico es que, cuando algunos usuarios están inactivos, su ancho de banda simplemente se pierde. No lo están usando, y a nadie más se le permite usarlo. Una asignación estática es un mal arreglo para la mayoría de los sistemas de cómputo, en donde el tráfico de datos se presenta en ráfagas muy intensas, a menudo con relaciones de tráfico pico a tráfico medio de 1000:1. En consecuencia, la mayoría de los canales estarán inactivos casi todo el tiempo.
El pobre desempeño del FDM estático se puede ver fácilmente mediante un cálculo sencillo de la teoría de colas. Primero obtendremos el retardo promedio, T, al enviar una trama a través de un canal con C bps de capacidad. Suponemos que las tramas llegan al azar con una tasa de llegada promedio de λ tramas/seg y que la longitud de las tramas es variable, con una longitud promedio de 1/m bits. Con estos parámetros, la tasa de servicio del canal es de mC tramas/seg. Un resultado de la teoría de colas estándar es:
Supuestos para la asignación dinámica de canales
Todo el trabajo hecho en esta área se basa en cinco supuestos clave, que se describen a continuación:
Es importante un análisis de estos supuestos. El primero dice que las llegadas de las tramas son independientes, tanto en todas las estaciones como en una estación específica, y que las tramas se generan en forma impredecible, pero a una tasa de transmisión constante. En realidad este supuesto no es en sí un buen modelo de tráfico de red, pues es bien sabido que los paquetes llegan en ráfagas durante un rango de escalas de tiempo (Paxson y Floyd, 1995; y Leland y colaboradores, 1994). Sin embargo, los modelos de Poisson, como se les dice con frecuencia, son útiles debido a que son matemáticamente de fácil solución.
Estos modelos nos ayudan a analizar protocolos para comprender a grandes rasgos cómo cambia el rendimiento durante un intervalo de operación y cómo se compara con otros diseños. El supuesto del canal único es la esencia del modelo. No existen formas externas de comunicación. Las estaciones no pueden levantar la mano para solicitar que el maestro les ceda la palabra, por lo que tendremos que idear mejores soluciones.
El tema central de este capítulo es la forma de asignar un solo canal de difusión entre usuarios competidores. El canal podría ser una parte del espectro inalámbrico en una región geográfica, o un solo alambre o fibra óptica en donde se conectan varios nodos. Esto no es importante. En ambos casos, el canal conecta a cada usuario con todos los demás; cualquier usuario que utilice todo el canal interfiere con los demás que también desean usarlo.
Primero veremos las deficiencias de los esquemas de asignación estática para el tráfico en ráfagas. Después estableceremos las suposiciones clave que se utilizan para modelar los esquemas dinámicos que examinaremos en las siguientes secciones.
Asignación estática de canal
La manera tradicional de asignar un solo canal, como una troncal telefónica, entre múltiples usuarios competidores es dividir su capacidad mediante el uso de uno de los esquemas de multiplexión, como el FDM (Multiplexión por División de Frecuencia, del inglés Frequency Division Multiplexing). Si hay N usuarios, el ancho de banda se divide en N partes de igual tamaño, y a cada usuario se le asigna una parte. Debido a que cada usuario tiene una banda de frecuencia privada, ahora no hay interferencia entre ellos. Cuando sólo hay una pequeña cantidad fija y constante de usuarios, cada uno tiene un flujo estable o una carga de tráfico pesada, esta división es un mecanismo de asignación sencillo y eficiente. Las estaciones de radio de FM son un ejemplo inalámbrico. Cada estación recibe una parte de la banda de FM y la utiliza la mayor parte del tiempo para difundir su señal. Sin embargo, cuando el número de emisores es grande y varía continuamente, o cuando el tráfico se hace en ráfagas, el FDM presenta algunos problemas. Si el espectro se divide en N regiones y actualmente hay menos de N usuarios interesados en comunicarse, se desperdiciará una buena parte del valioso espectro. Y si más de N usuarios quieren comunicarse, a algunos de ellos se les negará el permiso por falta de ancho de banda, aun cuando algunos de los usuarios que tengan asignada una banda de frecuencia apenas transmitan o reciban algo.
Aun suponiendo que el número de usuarios podría, de alguna manera, mantenerse constante en N, dividir el único canal disponible en varios subcanales estáticos es ineficiente por naturaleza. El problema básico es que, cuando algunos usuarios están inactivos, su ancho de banda simplemente se pierde. No lo están usando, y a nadie más se le permite usarlo. Una asignación estática es un mal arreglo para la mayoría de los sistemas de cómputo, en donde el tráfico de datos se presenta en ráfagas muy intensas, a menudo con relaciones de tráfico pico a tráfico medio de 1000:1. En consecuencia, la mayoría de los canales estarán inactivos casi todo el tiempo.
El pobre desempeño del FDM estático se puede ver fácilmente mediante un cálculo sencillo de la teoría de colas. Primero obtendremos el retardo promedio, T, al enviar una trama a través de un canal con C bps de capacidad. Suponemos que las tramas llegan al azar con una tasa de llegada promedio de λ tramas/seg y que la longitud de las tramas es variable, con una longitud promedio de 1/m bits. Con estos parámetros, la tasa de servicio del canal es de mC tramas/seg. Un resultado de la teoría de colas estándar es:
T = 1 / µC - λ
Supuestos para la asignación dinámica de canales
Todo el trabajo hecho en esta área se basa en cinco supuestos clave, que se describen a continuación:
- Tráfico independiente. El modelo consiste en N estaciones independientes (computadoras, teléfonos), cada una con un programa o usuario que genera tramas para transmisión. El número esperado de tramas que se generan en un intervalo de longitud Dt es de λDt, donde λ es una constante (la tasa de llegada de tramas nuevas). Una vez que se ha generado una trama, la estación se bloquea y no hace nada sino hasta que la trama se haya transmitido con éxito.
- Canal único. Hay un solo canal disponible para todas las comunicaciones. Todas las estaciones pueden transmitir en él y pueden recibir de él. Se asume que las estaciones tienen una capacidad equivalente, aunque los protocolos pueden asignarles distintos roles (prioridades).
- Colisiones observables. Si dos tramas se transmiten en forma simultánea, se traslapan en el tiempo y la señal resultante se altera. Este evento se llama colisión. Todas las estaciones pueden detectar una colisión que haya ocurrido. Una trama en colisión se debe volver a transmitir después. No hay otros errores, excepto aquéllos generados por las colisiones.
- Tiempo continuo o ranurado. Se puede asumir que el tiempo es continuo, en cuyo caso la transmisión de una trama puede comenzar en cualquier momento. Por el contrario, el tiempo se puede ranurar o dividir en intervalos discretos (llamados ranuras). En este caso las transmisiones de las tramas deben empezar al inicio de una ranura. Una ranura puede contener 0, 1 o más tramas, correspondientes a una ranura inactiva, una transmisión exitosa o una colisión, respectivamente.
- Detección de portadora o sin detección de portadora. Con el supuesto de detección de portadora, las estaciones pueden saber si el canal está en uso antes de intentar usarlo. Si se detecta que el canal está ocupado, ninguna estación intentará utilizarlo. Si no hay detección de portadora, las estaciones no pueden detectar el canal antes de intentar usarlo. Simplemente transmiten. Sólo después pueden determinar si la transmisión tuvo éxito.
Es importante un análisis de estos supuestos. El primero dice que las llegadas de las tramas son independientes, tanto en todas las estaciones como en una estación específica, y que las tramas se generan en forma impredecible, pero a una tasa de transmisión constante. En realidad este supuesto no es en sí un buen modelo de tráfico de red, pues es bien sabido que los paquetes llegan en ráfagas durante un rango de escalas de tiempo (Paxson y Floyd, 1995; y Leland y colaboradores, 1994). Sin embargo, los modelos de Poisson, como se les dice con frecuencia, son útiles debido a que son matemáticamente de fácil solución.
Estos modelos nos ayudan a analizar protocolos para comprender a grandes rasgos cómo cambia el rendimiento durante un intervalo de operación y cómo se compara con otros diseños. El supuesto del canal único es la esencia del modelo. No existen formas externas de comunicación. Las estaciones no pueden levantar la mano para solicitar que el maestro les ceda la palabra, por lo que tendremos que idear mejores soluciones.
7.5.2) Protocolos de acceso múltiple
Se conocen muchos algoritmos para asignar un canal de acceso múltiple.
Aloha
La historia de nuestro primer MAC empieza en la prístina Hawai de principios de la década de 1970. En este caso, podemos interpretar “prístina” como que “no tenía un sistema telefónico funcional”. Esto no hizo la vida más placentera para el investigador Norman Abramson y sus colegas de la Universidad de Hawai, quienes trataban de conectar a los usuarios en islas remotas a la computadora principal en Honolulu. Tender sus propios cables bajo el Océano Pacífico no era una opción viable, por lo que buscaron una solución diferente.
La que encontraron utilizaba radios de corto rango, en donde cada terminal de usuario compartía la misma frecuencia ascendente para enviar tramas a la computadora central. Incluía un método simple y elegante para resolver el problema de asignación de canal. Desde entonces, su trabajo ha sido extendido por muchos investigadores (Schwartz y Abramson, 2009). Aunque el trabajo de Abramson, llamado sistema ALOHA, usó la radiodifusión basada en tierra, la idea básica es aplicable a cualquier sistema en el que usuarios no coordinados compiten por el uso de un solo canal compartido. Analizaremos dos versiones de ALOHA: puro y ranurado. Difieren en cuanto a si el tiempo es continuo, como en la versión pura, o si se divide en ranuras discretas en las que deben caber todas las tramas.
Aloha Puro
La idea básica de un sistema ALOHA es sencilla: permitir que los usuarios transmitan cuando tengan datos por enviar. Por supuesto, habrá colisiones y las tramas en colisión se dañarán. Los emisores necesitan alguna forma de saber si éste es el caso. En el sistema ALOHA, después de que cada estación envía su trama a la computadora central, ésta vuelve a difundir la trama a todas las estaciones. Así, una estación emisora puede escuchar la difusión de la estación terrena maestra (hub) para ver si pasó su trama o no. En otros sistemas, como las LAN alámbricas, el emisor podría ser capaz de escuchar si hay colisiones mientras transmite.
Si la trama fue destruida, el emisor simplemente espera un tiempo aleatorio y la envía de nuevo. El tiempo de espera debe ser aleatorio o las mismas tramas chocarán una y otra vez, en sincronía. Los sistemas en los cuales varios usuarios comparten un canal común de modo tal que puede dar pie a conflictos se conocen como sistemas de contención.
Hemos hecho que todas las tramas sean de la misma longitud porque la velocidad real de transmisión (throughput) de los sistemas ALOHA se maximiza al tener tramas con un tamaño uniforme en lugar de tramas de longitud variable.
Cada vez que dos tramas traten de ocupar el canal al mismo tiempo, habrá una colisión y ambas se dañarán. Si el primer bit de una trama nueva se traslapa con el último bit de una trama casi terminada, ambas se destruirán por completo (es decir, tendrán sumas de verificación incorrectas) y ambas tendrán que volver a transmitirse más tarde. La suma de verificación no distingue (y no debe) entre una pérdida total y un error ligero. Lo malo es malo.
Aloha ranurado
Poco después de que ALOHA apareció en escena, Roberts (1972) publicó un método para duplicar la capacidad de un sistema ALOHA. Su propuesta fue dividir el tiempo en intervalos discretos llamados ranuras, cada uno de los cuales correspondía a una trama. Este método requiere que los usuarios acuerden límites de ranura. Una manera de lograr la sincronización sería tener una estación especial que emitiera una señal al comienzo de cada intervalo, como un reloj. En el método de Roberts, que se conoce como ALOHA ranurado, en contraste con el ALOHA puro de Abramson, no se permite que una estación envíe cada vez que el usuario escribe una línea. En cambio, se le obliga a esperar el comienzo de la siguiente ranura. Por lo tanto, el ALOHA de tiempo continuo se convierte en uno de tiempo discreto. Esto reduce el periodo vulnerable a la mitad. La probabilidad de que no haya más tráfico durante la misma ranura que nuestra trama de prueba es entonces de e−G, lo que conduce a:
Se conocen muchos algoritmos para asignar un canal de acceso múltiple.
Aloha
La historia de nuestro primer MAC empieza en la prístina Hawai de principios de la década de 1970. En este caso, podemos interpretar “prístina” como que “no tenía un sistema telefónico funcional”. Esto no hizo la vida más placentera para el investigador Norman Abramson y sus colegas de la Universidad de Hawai, quienes trataban de conectar a los usuarios en islas remotas a la computadora principal en Honolulu. Tender sus propios cables bajo el Océano Pacífico no era una opción viable, por lo que buscaron una solución diferente.
La que encontraron utilizaba radios de corto rango, en donde cada terminal de usuario compartía la misma frecuencia ascendente para enviar tramas a la computadora central. Incluía un método simple y elegante para resolver el problema de asignación de canal. Desde entonces, su trabajo ha sido extendido por muchos investigadores (Schwartz y Abramson, 2009). Aunque el trabajo de Abramson, llamado sistema ALOHA, usó la radiodifusión basada en tierra, la idea básica es aplicable a cualquier sistema en el que usuarios no coordinados compiten por el uso de un solo canal compartido. Analizaremos dos versiones de ALOHA: puro y ranurado. Difieren en cuanto a si el tiempo es continuo, como en la versión pura, o si se divide en ranuras discretas en las que deben caber todas las tramas.
Aloha Puro
La idea básica de un sistema ALOHA es sencilla: permitir que los usuarios transmitan cuando tengan datos por enviar. Por supuesto, habrá colisiones y las tramas en colisión se dañarán. Los emisores necesitan alguna forma de saber si éste es el caso. En el sistema ALOHA, después de que cada estación envía su trama a la computadora central, ésta vuelve a difundir la trama a todas las estaciones. Así, una estación emisora puede escuchar la difusión de la estación terrena maestra (hub) para ver si pasó su trama o no. En otros sistemas, como las LAN alámbricas, el emisor podría ser capaz de escuchar si hay colisiones mientras transmite.
Si la trama fue destruida, el emisor simplemente espera un tiempo aleatorio y la envía de nuevo. El tiempo de espera debe ser aleatorio o las mismas tramas chocarán una y otra vez, en sincronía. Los sistemas en los cuales varios usuarios comparten un canal común de modo tal que puede dar pie a conflictos se conocen como sistemas de contención.
Hemos hecho que todas las tramas sean de la misma longitud porque la velocidad real de transmisión (throughput) de los sistemas ALOHA se maximiza al tener tramas con un tamaño uniforme en lugar de tramas de longitud variable.
Cada vez que dos tramas traten de ocupar el canal al mismo tiempo, habrá una colisión y ambas se dañarán. Si el primer bit de una trama nueva se traslapa con el último bit de una trama casi terminada, ambas se destruirán por completo (es decir, tendrán sumas de verificación incorrectas) y ambas tendrán que volver a transmitirse más tarde. La suma de verificación no distingue (y no debe) entre una pérdida total y un error ligero. Lo malo es malo.
Aloha ranurado
Poco después de que ALOHA apareció en escena, Roberts (1972) publicó un método para duplicar la capacidad de un sistema ALOHA. Su propuesta fue dividir el tiempo en intervalos discretos llamados ranuras, cada uno de los cuales correspondía a una trama. Este método requiere que los usuarios acuerden límites de ranura. Una manera de lograr la sincronización sería tener una estación especial que emitiera una señal al comienzo de cada intervalo, como un reloj. En el método de Roberts, que se conoce como ALOHA ranurado, en contraste con el ALOHA puro de Abramson, no se permite que una estación envíe cada vez que el usuario escribe una línea. En cambio, se le obliga a esperar el comienzo de la siguiente ranura. Por lo tanto, el ALOHA de tiempo continuo se convierte en uno de tiempo discreto. Esto reduce el periodo vulnerable a la mitad. La probabilidad de que no haya más tráfico durante la misma ranura que nuestra trama de prueba es entonces de e−G, lo que conduce a:
S = Ge^-G
7.5.3) Ethernet
Hemos finalizado nuestra discusión general sobre los protocolos de asignación de canal, por lo que es tiempo de ver la forma en que estos principios se aplican a sistemas reales. Muchos de los diseños para las redes personales, locales y de área metropolitana se han estandarizado bajo el nombre de IEEE 802.
Algunos han sobrevivido pero muchos no. Quienes creen en la reencarnación piensan que Charles Darwin regresó como miembro de la Asociación de estándares del IEEE para eliminar a los débiles. Los sobrevivientes más importantes son el 802.3 (Ethernet) y el 802.11 (LAN inalámbrica). Bluetooth (PAN inalámbrica) se utiliza mucho en la actualidad, pero se estandarizó fuera del 802.15. Todavía es muy pronto para decir algo sobre el 802.16 (MAN inalámbrica).
Empezaremos nuestro estudio de los sistemas reales con Ethernet, que probablemente sea el tipo más ubicuo de red de computadoras en el mundo. Existen dos tipos de Ethernet: Ethernet clásica, que resuelve el problema de acceso múltiple mediante el uso de las técnicas que hemos estudiado en este capítulo; el segundo tipo es la Ethernet conmutada, en donde los dispositivos llamados switches se utilizan para conectar distintas computadoras. Es importante mencionar que, aunque se hace referencia a ambas como Ethernet, son muy diferentes. La Ethernet clásica es la forma original que operaba a tasas de transmisión de 3 a 10 Mbps. La Ethernet conmutada es en lo que se convirtió la Ethernet y opera a 100, 1 000 y 10 000 Mbps, en formas conocidas como Fast Ethernet, Gigabit Ethernet y 10 Gigabit Ethernet. Actualmente, en la práctica sólo se utiliza Ethernet conmutada.
Ethernet Clasica
La historia de Ethernet empieza casi al mismo tiempo que ALOHA, cuando un estudiante llamado Bob Metcalfe obtuvo su licenciatura en el MIT y después obtuvo su doctorado en Harvard. Durante sus estudios oyó hablar del trabajo de Abramson. Se interesó tanto en él que, después de graduarse de Harvard, decidió pasar el verano en Hawai trabajando con Abramson antes de empezar a trabajar en Xerox PARC (Palo Alto Research Center). Cuando llegó a PARC, vio que los investigadores ahí habían diseñado y construido lo que después se conocería como computadora personal. Pero las máquinas estaban aisladas.
Haciendo uso de su conocimiento sobre el trabajo de Abramson, junto con su colega David Boggs diseñó e implementó la primera red de área local (Metcalfe y Boggs, 1976). Esta red utilizaba un solo cable coaxial grueso y extenso; operaba a 3 Mbps. Llamaron al sistema Ethernet en honor al éter luminífero, por medio del cual se pensaba antes que se propagaba la radiación electromagnética (cuando el físico inglés del siglo xix James Clerk Maxwell descubrió que la radiación electromagnética se podía describir mediante una ecuación de onda, los científicos asumieron que el espacio debía estar lleno de algún medio etéreo en el que se propagaba la radiación. No fue sino hasta después del famoso experimento de Michelson-Morley en 1887 que los físicos descubrieron que la radiación electromagnética se podía propagar en un vacío).
La Xerox Ethernet fue tan exitosa que DEC, Intel y Xerox idearon un estándar en 1978 para una Ethernet de 10 Mbps, conocido como estándar DIX. Con una modificación menor, el estándar DIX se convirtió en el estándar IEEE 802.3 en 1983. Por desgracia para Xerox, ya contaba con un historial de hacer inventos seminales (como la computadora personal) y después fracasar en su comercialización, una historia contada en la publicación Fumbling the Future (Smith y Alexander, 1988). Cuando Xerox mostró poco interés en hacer algo con Ethernet aparte de ayudar a estandarizarla, Metcalfe formó su propia empresa llamada 3Com para vender adaptadores de Ethernet para PC. Vendió muchos millones de ellos.
La Ethernet clásica se tendía alrededor del edificio como un solo cable largo al que se conectaban todas las computadoras. Esta arquitectura se muestra en la figura 4-13. La primera variedad, conocida popularmente como Ethernet gruesa, se asemejaba a una manguera de jardín amarilla, con marcas cada 2.5 metros para mostrar en dónde conectar las computadoras (el estándar 802.3 en realidad no requería que el cable fuera amarillo, pero sí lo sugería). Después le siguió la Ethernet delgada, que se doblaba con más facilidad y las conexiones se realizaban mediante conectores BNC. La Ethernet delgada era mucho más económica y fácil de instalar, pero sólo se podían tender 185 metros por segmento (en vez de los 500 m con la Ethernet gruesa), cada uno de los cuales sólo podía manejar 30 máquinas (en vez de 100).
Cada versión de Ethernet tiene una longitud de cable máxima por segmento (es decir, longitud sin amplificar) a través de la cual se propagará la señal. Para permitir redes más grandes, se pueden conectar varios cables mediante repetidores. Un repetidor es un dispositivo de capa física que recibe, amplifica (es decir, regenera) y retransmite las señales en ambas direcciones. En cuanto a lo que al software concierne, una serie de segmentos de cable conectados por repetidores no presenta ninguna diferencia en comparación con un solo cable (excepto por una pequeña cantidad de retardo que introducen los repetidores).
Ethernet Conmutada
Pronto Ethernet empezó a evolucionar y a alejarse de la arquitectura de un solo cable extenso de la Ethernet clásica. Los problemas asociados con el hecho de encontrar interrupciones o conexiones flojas condujeron hacia un distinto tipo de patrón de cableado, en donde cada estación cuenta con un cable dedicado que llega a un hub (concentrador) central. Un hub simplemente conecta de manera eléctrica todos los cables que llegan a él, como si estuvieran soldados en conjunto.
Los cables eran pares trenzados de la compañía telefónica, ya que la mayoría de los edificios de oficinas contaban con este tipo de cableado y por lo general había muchos de sobra. Esta reutilización fue una ventaja, pero a la vez se redujo la distancia máxima de cable del hub hasta 100 metros (200 metros si se utilizaban pares trenzados categoría 5 de alta calidad). En esta configuración es más simple agregar o quitar una estación, además de que los cables rotos se pueden detectar con facilidad. Con las ventajas de usar el cableado existente y la facilidad de mantenimiento, los hubs de par trenzado se convirtieron rápidamente en la forma dominante de Ethernet.
Sin embargo, los hubs no incrementan la capacidad debido a que son lógicamente equivalentes al cable extenso individual de la Ethernet clásica. A medida que se agregan más estaciones, cada estación recibe una parte cada vez menor de la capacidad fija. En un momento dado, la LAN se saturará. Una forma de solucionar esto es usar una velocidad más alta; por decir, de 10 Mbps a 100 Mbp, 1 Gbps o incluso mayores velocidades. Pero con el crecimiento de multimedia y los poderosos servidores, incluso una Ethernet de 1 Gbps se podría saturar.
Por fortuna existe otra forma de tratar con el aumento de carga: una Ethernet conmutada. El corazón de este sistema es un conmutador (switch) que contiene un plano posterior (backplane) de alta velocidad, el cual conecta a todos los puertos como se muestra en la figura 4-17(b). Desde el exterior, un switch se ve igual que un hub. Ambos son cajas que por lo general contienen de 4 a 48 puertos, cada uno con un conector estándar RJ-45 r para un cable de par trenzado. Cada cable conecta al switch o hub con una sola computadora, como se muestra en la figura 4-18. Un switch tiene también las mismas ventajas que un hub. Es fácil agregar o quitar una nueva estación con sólo conectar o desconectar un cable, y es fácil encontrar la mayoría de las fallas, ya que un cable o puerto defectuoso por lo general afectará a una sola estación. De todas formas hay un componente compartido que puede fallar (el mismo switch), pero si todas las estaciones pierden conectividad, los encargados del TI sabrán qué hacer para corregir el problema: reemplazar el switch completo.
Un switch mejora el desempeño de la red en comparación con un hub de dos maneras. Primero, como no hay colisiones, la capacidad se utiliza con más eficiencia. Segundo y más importante, con un switch se pueden enviar varias tramas al mismo tiempo (por distintas estaciones). Estas tramas llegarán a los puertos del switch y viajarán hacia el plano posterior de éste para enviarlos por los puertos apropiados. No obstante, como se podrían enviar dos tramas al mismo puerto de salida y al mismo tiempo, el switch debe tener un búfer para que pueda poner temporalmente en cola una trama de entrada hasta que se pueda transmitir al puerto de salida. En general, estas mejoras producen una considerable ganancia en el desempeño que no es posible lograr con un hub. Con frecuencia, la velocidad real de transmisión total del sistema se puede incrementar en un orden de magnitud, dependiendo del número de puertos y patrones de tráfico.
Hemos finalizado nuestra discusión general sobre los protocolos de asignación de canal, por lo que es tiempo de ver la forma en que estos principios se aplican a sistemas reales. Muchos de los diseños para las redes personales, locales y de área metropolitana se han estandarizado bajo el nombre de IEEE 802.
Algunos han sobrevivido pero muchos no. Quienes creen en la reencarnación piensan que Charles Darwin regresó como miembro de la Asociación de estándares del IEEE para eliminar a los débiles. Los sobrevivientes más importantes son el 802.3 (Ethernet) y el 802.11 (LAN inalámbrica). Bluetooth (PAN inalámbrica) se utiliza mucho en la actualidad, pero se estandarizó fuera del 802.15. Todavía es muy pronto para decir algo sobre el 802.16 (MAN inalámbrica).
Empezaremos nuestro estudio de los sistemas reales con Ethernet, que probablemente sea el tipo más ubicuo de red de computadoras en el mundo. Existen dos tipos de Ethernet: Ethernet clásica, que resuelve el problema de acceso múltiple mediante el uso de las técnicas que hemos estudiado en este capítulo; el segundo tipo es la Ethernet conmutada, en donde los dispositivos llamados switches se utilizan para conectar distintas computadoras. Es importante mencionar que, aunque se hace referencia a ambas como Ethernet, son muy diferentes. La Ethernet clásica es la forma original que operaba a tasas de transmisión de 3 a 10 Mbps. La Ethernet conmutada es en lo que se convirtió la Ethernet y opera a 100, 1 000 y 10 000 Mbps, en formas conocidas como Fast Ethernet, Gigabit Ethernet y 10 Gigabit Ethernet. Actualmente, en la práctica sólo se utiliza Ethernet conmutada.
Ethernet Clasica
La historia de Ethernet empieza casi al mismo tiempo que ALOHA, cuando un estudiante llamado Bob Metcalfe obtuvo su licenciatura en el MIT y después obtuvo su doctorado en Harvard. Durante sus estudios oyó hablar del trabajo de Abramson. Se interesó tanto en él que, después de graduarse de Harvard, decidió pasar el verano en Hawai trabajando con Abramson antes de empezar a trabajar en Xerox PARC (Palo Alto Research Center). Cuando llegó a PARC, vio que los investigadores ahí habían diseñado y construido lo que después se conocería como computadora personal. Pero las máquinas estaban aisladas.
Haciendo uso de su conocimiento sobre el trabajo de Abramson, junto con su colega David Boggs diseñó e implementó la primera red de área local (Metcalfe y Boggs, 1976). Esta red utilizaba un solo cable coaxial grueso y extenso; operaba a 3 Mbps. Llamaron al sistema Ethernet en honor al éter luminífero, por medio del cual se pensaba antes que se propagaba la radiación electromagnética (cuando el físico inglés del siglo xix James Clerk Maxwell descubrió que la radiación electromagnética se podía describir mediante una ecuación de onda, los científicos asumieron que el espacio debía estar lleno de algún medio etéreo en el que se propagaba la radiación. No fue sino hasta después del famoso experimento de Michelson-Morley en 1887 que los físicos descubrieron que la radiación electromagnética se podía propagar en un vacío).
La Xerox Ethernet fue tan exitosa que DEC, Intel y Xerox idearon un estándar en 1978 para una Ethernet de 10 Mbps, conocido como estándar DIX. Con una modificación menor, el estándar DIX se convirtió en el estándar IEEE 802.3 en 1983. Por desgracia para Xerox, ya contaba con un historial de hacer inventos seminales (como la computadora personal) y después fracasar en su comercialización, una historia contada en la publicación Fumbling the Future (Smith y Alexander, 1988). Cuando Xerox mostró poco interés en hacer algo con Ethernet aparte de ayudar a estandarizarla, Metcalfe formó su propia empresa llamada 3Com para vender adaptadores de Ethernet para PC. Vendió muchos millones de ellos.
La Ethernet clásica se tendía alrededor del edificio como un solo cable largo al que se conectaban todas las computadoras. Esta arquitectura se muestra en la figura 4-13. La primera variedad, conocida popularmente como Ethernet gruesa, se asemejaba a una manguera de jardín amarilla, con marcas cada 2.5 metros para mostrar en dónde conectar las computadoras (el estándar 802.3 en realidad no requería que el cable fuera amarillo, pero sí lo sugería). Después le siguió la Ethernet delgada, que se doblaba con más facilidad y las conexiones se realizaban mediante conectores BNC. La Ethernet delgada era mucho más económica y fácil de instalar, pero sólo se podían tender 185 metros por segmento (en vez de los 500 m con la Ethernet gruesa), cada uno de los cuales sólo podía manejar 30 máquinas (en vez de 100).
Cada versión de Ethernet tiene una longitud de cable máxima por segmento (es decir, longitud sin amplificar) a través de la cual se propagará la señal. Para permitir redes más grandes, se pueden conectar varios cables mediante repetidores. Un repetidor es un dispositivo de capa física que recibe, amplifica (es decir, regenera) y retransmite las señales en ambas direcciones. En cuanto a lo que al software concierne, una serie de segmentos de cable conectados por repetidores no presenta ninguna diferencia en comparación con un solo cable (excepto por una pequeña cantidad de retardo que introducen los repetidores).
Ethernet Conmutada
Pronto Ethernet empezó a evolucionar y a alejarse de la arquitectura de un solo cable extenso de la Ethernet clásica. Los problemas asociados con el hecho de encontrar interrupciones o conexiones flojas condujeron hacia un distinto tipo de patrón de cableado, en donde cada estación cuenta con un cable dedicado que llega a un hub (concentrador) central. Un hub simplemente conecta de manera eléctrica todos los cables que llegan a él, como si estuvieran soldados en conjunto.
Los cables eran pares trenzados de la compañía telefónica, ya que la mayoría de los edificios de oficinas contaban con este tipo de cableado y por lo general había muchos de sobra. Esta reutilización fue una ventaja, pero a la vez se redujo la distancia máxima de cable del hub hasta 100 metros (200 metros si se utilizaban pares trenzados categoría 5 de alta calidad). En esta configuración es más simple agregar o quitar una estación, además de que los cables rotos se pueden detectar con facilidad. Con las ventajas de usar el cableado existente y la facilidad de mantenimiento, los hubs de par trenzado se convirtieron rápidamente en la forma dominante de Ethernet.
Sin embargo, los hubs no incrementan la capacidad debido a que son lógicamente equivalentes al cable extenso individual de la Ethernet clásica. A medida que se agregan más estaciones, cada estación recibe una parte cada vez menor de la capacidad fija. En un momento dado, la LAN se saturará. Una forma de solucionar esto es usar una velocidad más alta; por decir, de 10 Mbps a 100 Mbp, 1 Gbps o incluso mayores velocidades. Pero con el crecimiento de multimedia y los poderosos servidores, incluso una Ethernet de 1 Gbps se podría saturar.
Por fortuna existe otra forma de tratar con el aumento de carga: una Ethernet conmutada. El corazón de este sistema es un conmutador (switch) que contiene un plano posterior (backplane) de alta velocidad, el cual conecta a todos los puertos como se muestra en la figura 4-17(b). Desde el exterior, un switch se ve igual que un hub. Ambos son cajas que por lo general contienen de 4 a 48 puertos, cada uno con un conector estándar RJ-45 r para un cable de par trenzado. Cada cable conecta al switch o hub con una sola computadora, como se muestra en la figura 4-18. Un switch tiene también las mismas ventajas que un hub. Es fácil agregar o quitar una nueva estación con sólo conectar o desconectar un cable, y es fácil encontrar la mayoría de las fallas, ya que un cable o puerto defectuoso por lo general afectará a una sola estación. De todas formas hay un componente compartido que puede fallar (el mismo switch), pero si todas las estaciones pierden conectividad, los encargados del TI sabrán qué hacer para corregir el problema: reemplazar el switch completo.
Un switch mejora el desempeño de la red en comparación con un hub de dos maneras. Primero, como no hay colisiones, la capacidad se utiliza con más eficiencia. Segundo y más importante, con un switch se pueden enviar varias tramas al mismo tiempo (por distintas estaciones). Estas tramas llegarán a los puertos del switch y viajarán hacia el plano posterior de éste para enviarlos por los puertos apropiados. No obstante, como se podrían enviar dos tramas al mismo puerto de salida y al mismo tiempo, el switch debe tener un búfer para que pueda poner temporalmente en cola una trama de entrada hasta que se pueda transmitir al puerto de salida. En general, estas mejoras producen una considerable ganancia en el desempeño que no es posible lograr con un hub. Con frecuencia, la velocidad real de transmisión total del sistema se puede incrementar en un orden de magnitud, dependiendo del número de puertos y patrones de tráfico.




No hay comentarios.:
Publicar un comentario